




Thomas Krefeld | Stephan Lücke
Überarbeitete deutschsprachige Fassung eines auf dem Kongress "Lingue e culture della montagna", Torino / Bobbio Pellice, 15./16.5.2015, gehaltenen Vortrags
0. Wissenschaftskommunikation in der Perspektive der digital humanities
VerbaAlpina (= VA) wurde von vorneherein mit dem Anspruch konzipiert, ausschließlich Webtechnologie einzusetzen und auf alle, noch weithin verbreiteten, hybriden Lösungen zu verzichten, die sich ergeben, wenn die Optionen des Internet erst in einem zweiten, nachgeordneten Schritt genutzt werden, wie es z.B. bei der Veröffentlichung lokal entwickelter, proprietärer Formate geschieht. Die wissenschaftliche Zielsetzung wird dadurch durchaus nicht berührt, aber die Wissenschaftskommunikation unterliegt substanziell anderen Rahmenbedingungen (cf. Krefeld 2011).
Der tiefgreifendste Unterschied betrifft die Organisation der Forschungsarbeit; während die traditionelle Vorgehensweise die Abfolge unterschiedlicher Phasen vorsieht, die mit der Publikation der Ergebnisse zum Abschluss kommen, werden die unterschiedlichen Forschungsaufgaben bei webbasierter Durchführung weitgehend parallel geleistet. Genauer gesagt erfolgt die Arbeit in vier verschiedenen, eng miteinander verflochteten Domänen, die im Folgenden beschrieben werden sollen:
- Dokumentation,
- Kooperation,
- Erhebung,
- Publikation.
Um das reibungslose Ineinandergreifen dieser Funktionsbereiche zu garantieren, ist es unbedingt erforderlich ausschließlich Software mit öffentlich zugänglichen Quellcodes ('open source') einzusetzen. Die Kooperation mit privatwirtschaftlich ausgerichteten Unternehmen oder mit staatlichen Einrichtungen, die auf informationstechnische Eigenständigkeit ausgerichtet sind, ist daher grundsätzlich problematisch. Eine Sprache gehört niemandem, oder besser: Sie gehört allen, die sie erwerben oder lernen -- auch dann, wenn sie in digitaler Kodierung dokumentiert wird. Sprachdokumentationen, die durch öffentliche Mittel ermöglicht werden, müssen der Öffentlichkeit auch zur Verfügung gestellt. Keinesfalls dürfen sie in mehr oder weniger indirekter Weise, etwa durch die Verwendung proprietärer Software, zum geistigen und kommerziell einklagbaren Eigentum derjenigen werden, die sie medial bereit stellen.
1. Dokumentation
Die Dokumentation erfolgt in ethnolinguistischer Perspektive.
sono scelte certe tecniche culturali e fenomeni caratteristici dell'ambiente naturale alpino assieme alle designazioni dialettali corrispondenti. Tutti i dati sono presentati sotto forma cartografica virtuale, che esige la georeferenziazione di ogni dato. escludendo ovviamente qualisiasi informazione non georeferenziabile. L'utente ha la possibilitè di selezionare alternativamente concetti o tipi linguistici. Ecco un esempio che mostra sul tema dei fabbricati d'alpeggio (designazioni|foto); per il momento le foto non sono ancora implementate nella cartografazione.
I dati etnolinguistici sono completati da certi dati extralinguistici adatti a fornire informazioni sulla formazione del 'paesaggio' etnolinguistico in generale e specialmente alla diffusione di varianti dialettali. La funzione Carta sinottica permette anche di comporre e di salvare carte individuali combinando liberamente concetti, tipi lessicali e/o dati extralinguistici, come ad esempio i luoghi delle strade romane secondo la tavola Peutingeriana e i monasteri alpini. Nella zona oggi tedescofona la loro fondazione che risale delle volta fin al 8. secolo d.C. assiem alla ubicazione vicino a necropoli e insediamenti romani (non ancora georeferenziati) fa pensare a una continuità romanza fin al medioevo (vd. strade romane_monasteri).
#Überleitung Stephan: --- VA führt ALSO---
VerbaAlpina führt eine große Menge von Daten aus unterschiedlichen Quellen in einem einzigen System zusammen. Im Großen und Ganzen unterscheiden wir Sprachatlanten, Wörterbücher, Kooperationspartner und die sog. "Crowd" als Datenquellen. Jede dieser Quellenkategorien wie auch die Quellen im Einzelnen stellen unterschiedliche Herausforderungen dar. Im wesentlichen geht es darum, sämtliches Quellenmaterial, gleich welchen Ursprungs es ist, in eine einheitliche Datenstruktur und Zeichenkodierung zu überführen. Erst dadurch wird das Material quellenübergreifend vergleich- und analysierbar.
Im Zusammenspiel von VerbaAlpina mit seinen unterschiedlichen Datenquellen stellen die von VerbaAlpina gewählte Datenstruktur sowie Zeichenkodierung den Fix- und Ausgangspunkt aller Datenausstauschkonzepte dar.
VerbaAlpina ist in erster Linie lexikalisch ausgerichtet. Im Zentrum stehen also Wörter und deren Bedeutung, bzw., anders ausgedrückt: die Konzepte bzw. Begriffe, die mit Ihnen bezeichnet werden.
VerbaAlpina hat sich für die Verwendung des sogenannten relationalen Datenmodells entschieden. Dessen Charakteristikum ist die Anordnung der Daten in Tabellen. Im einfachsten Fall sieht – um ein Beispiel anzuführen – der Sachverhalt, dass das Wort "baita" das Konzept "Sennhütte" bezeichnet, im relationalen Datenmodell so aus:
| CONCETTO | NOME DEL COMUNE | LONGITUDINE | Latitudine | anno | fonte | |
|---|---|---|---|---|---|---|
| baita | CASCINA DI MONTAGNA | Monasterolo del Castello | 9.9327 | 45.7641 | 1940 | AIS 1192_1, 247 |
Da es sich um ein Projekt der Geolinguistik handelt, werden zusätzlich die Geokoordinaten des Ortes gespeichert, von dem die Daten stammen. Die Chronoreferenzierung in Gestalt der Jahreszahl gestattet diachrone Analysen. Die Nennung der Quelle ergibt sich aus dem Gebot wissenschaftlicher Nachvollziehbarkeit.
Ausgehend von einem sprachlichen Einzelbeleg, unterscheidet VerbaAlpina eine Reihe von Abstraktionsstufen. Zunächst werden – nach den Kriterien der historischen Phonetik – phonetisch ähnliche Belege zu phonetischen Typen zusammengefasst. Morphologisch ähnliche phonetische Typen werden anschließend wiederum zu morphologischen bzw. lexikalischen Typen zusammengefasst.
Partendo da un'attestazione concreta VerbalAlpina distingue in modi d’astrazione diversificati. Inizialmente – seguendo i criteri della fonetica storica -vengono riassunti dei tipi fonetici a base delle attestazioni fonetiche simili. Le attestazioni morfologiche simili vengono dunque riassunte come tipi morfologici cioè lessicali.
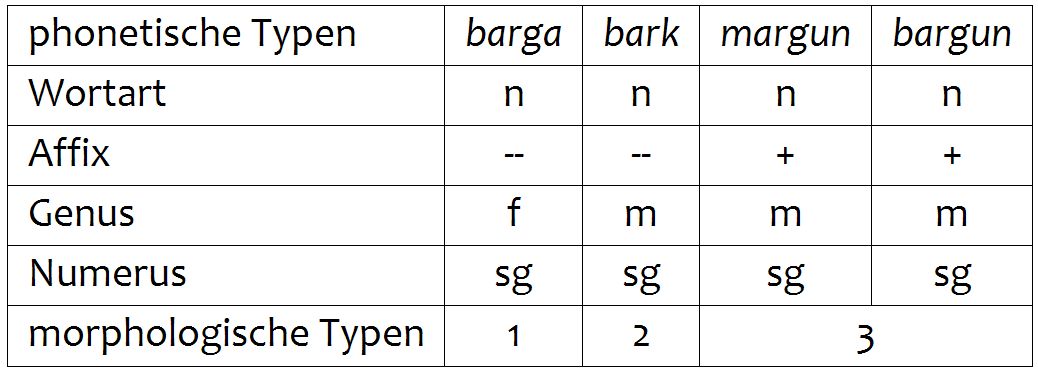
Die Kategorie "Basistyp" schließlich fasst mehrere morphologische Typen sprachübergreifend zusammen.
In fine la categoria “tipo di base” comprende alcuni tipi morfologici estendosi su lingue diverse.
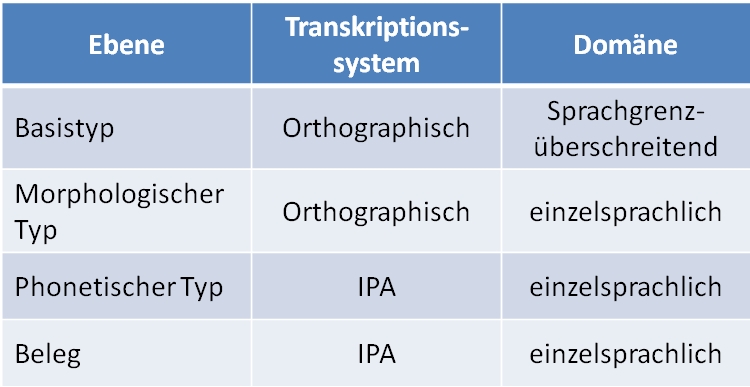
Während auf den Ebenen "Beleg" und "Phonetischer Typ" die IPA-Transkription verwendet wird, werden der "Morphologische Typ" und der Basistyp in Standardorthographie abgebildet, die sich, soweit möglich, an der Graphie definierter Referenzwörterbücher orientiert. Von besonderer Bedeutung sind in diesem Zusammenhang im romanischen Raum die tessinischen Wörterbücher RID und LSI, da sie auch über ihren eigentlichen Dialektbereich hinaus zahlreiche im Alpenraum weit verbreitete Typen in einer allgemein lesbaren Weise erfassen.
Usando la trascrizione IPA per l’attestazione concreta ed il tipo fonetico, i tipi morfologici ed il tipo di base vengono illustrati nell’ortografia dello standard , che si orienta, per quanto è possibile, alla grafia dei dizionari di riferimento definiti. In questo contesto i dizionari del Tessino RID e LSI sono di enorme importanza per l’area romanza, perché registrano anche numerosi tipi, della regione alpina, che non si trovano nella sua propria area dialettale, in modo generalmente comprensibile.

Die verschiedenen Ebenen der Typisierung werden zusammen mit einer Anzahl ausgewählter, relevanter Metadaten wie z.B. Informationen zur Quelle der Sprachdaten, also etwa bibliographischen Angaben, oder ihrer geographischen Herkunft und dem Erhebungszeitpunkt in einer einzigen Tabelle versammelt. Diese Tabelle erfüllt eine doppelte Funktion: Zum einen ist sie die sogenannte "Datenzugriffsschicht", auf die das Web-Frontend von VerbaAlpina etwa zur Erzeugung der interaktiven Sprachkarten zugreift, zum anderen ist sie Teil der zentralen Schnittstelle VAP, über die VerbaAlpina seinen Datenbestand seinen Projektpartnern zur Verfügung stellt. Nicht sprachbezogene, aber georeferenzierbare Daten werden in einer eigenen Tabelle zusammengeführt, die den anderen Teil der Schnittstelle VAP bildet.
I vari livelli della tipizzazione vengono raccolti con una quantità di metadati importanti selezionati , per esempio informazioni delle fonte dei dati linguistici, quindi la bibliografia, o la loro origine geografica e la data del rilevamento, racchiusi in una singola tabella. Questa tabella funziona in doppio modo: di una parte la tabella è il cosiddetto modulo di accesso ai dati, a cui il web-fronted di VerbaAlpina si serve per la produzione per le carte linguistiche interattive, e dell'altra fa parte dell’interfaccia VAP, con cui VerbaAlpina mette a disposizione il suo file di dati ai partner di cooperazione. I dati georeferenziati, che non si riferiscono alla lingua, sono raccolti in una propria tabella, che forma l’altra parte dell’interfaccia VAP
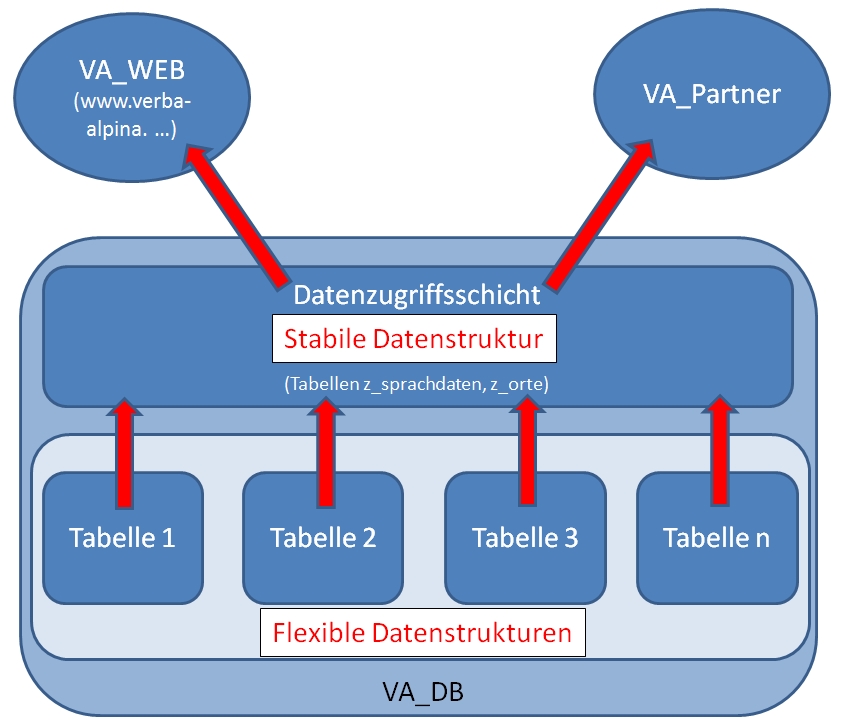
Datenzugriffsschicht
2. Die Datenquellen von VerbaAlpina
Während der derzeit laufenden Phase der systematischen Datensammlung besteht eine der wesentlichen Herausforderungen darin, Sprachmaterial aus Sprachatlanten, Wörterbüchern und Partnerprojekten in die skizzierte Systematik von VerbaAlpina zu überführen. Wir möchten dies im folgenden anhand ausgewählter Beispiele exemplifizieren.
2. Le fonti dei dati di VerbaAlpina
Durante la fase corrente del rilevamento dati, una delle sfide essenziali è il trasferimento del materiale linguistico degli atlanti linguistici, dei dizionari e dei partner di cooperazione nella sistematicità appena illustrata di VerbaAlpina. Ciò vorremmo presentare nei selezionati esempi seguenti :
a. Die Daten des AIS
Die Daten des AIS repräsentieren – der romanistischen Tradition der Sprachatlanten folgend – unmittelbare Einzelbelege in phonetischer Transkription des Böhmer-Ascoli-Systems. Normalerweise bezeichnen die in den Karten eingetragenen Belege das Konzept, dem die entsprechende Karte gewidmet ist. Im Einzelfall, aber nicht selten, geht aus Erläuterungen und Randnotizen auf den Karten hervor, dass ein spezieller Beleg nicht exakt das Hauptkonzept der Karte bezeichnet, sondern eine spezielle Variante oder ein Unterkonzept jenes Hauptkonzepts.
I dati dell’AIS presentano, seguendo la tradizione romanza degli atlanti linguistici, le attestazioni diretti nella trascrizione fonetica del sistema Böhmer-Ascoli. Normalmente le attestazioni, che sono iscritte nella carta, designano il concetto, a cui la carta è dedicata. Nel caso concreto, però non raro, si capisce dalle spiegazioni ed annotazioni , che un'attestazione speciale non corrisponde esattamente al concetto principale, bensì a una varietà particolare o a un concetto subordinato.
Die folgende Graphik zeigt einen Ausschnitt aus der AIS-Karte 1192_2, die – in Listenform – dem Konzept Milch- bzw. Käsekeller gewidmet ist.
La grafica in seguito mostra un frammento della carta AIS 1992_2, che è dedicata al concetto "cantina da latte, da formaggio" in forma di una lista.

Die drei mit rotem Pfeil markierten Belege bezeichnen den im Atlas gegebenen Zusatzinformationen zufolge jeweils bestimmte Varianten jenes Basiskonzepts. Bei der Erfassung der Daten in der Datenbank wird dies wie folgt registriert:
Le attestazioni che sono marcate con la freccia rossa designano gli informazioni aggiunti nell’atlante in conseguenza della variazione particolare del concetto di base. Nel rilevamento dei dati nella BD questo fatto viene registrato così:
Bei der Datenerfassung ist vom Bearbeiter jeweils zu entscheiden, welcher Kategorie innerhalb der VerbaAlpina-Systematik ein in der Quelle präsentierter "Beleg" zuzuordnen ist. In Betracht kommen grundsätzlich individuelle Sprecherbelege oder aber morphologische Typen. Im Fall des AIS handelt es sich stets um individuelle Sprecherbelege. Dies wird entsprechend in der VA-Datenbank registriert.
Nel rilevamento dei dati, l’elaboratore deve decidere a quale categoria entro la VerbaAlpina sistematicità , si deve assegnare un’attestazione presentata nella fonte. In generale vengono presi in considerazione le attestazioni individuali dall’informatore o tipi morfologici. Nel caso dell’ AIS si tratta sempre di attestazioni individuali. Ciò viene registrato appropriatamente nella banca dati di VerbaAlpina.
Grundsätzlich ist die Erfassung des Datenmaterials aus Sprachatlanten kaum zu automatisieren und muss im wesentlichen manuell erfolgen. Dabei tritt speziell bei den individuellen Sprecherbelegen das Problem der phonetischen Transkription auf, das per se ein doppeltes ist: Zum einen muss ein Weg gefunden werden, wie die bisweilen idiosynkratischen Zeichen, die teils noch nicht in Unicode kodiert sind, mit einer westeuropäischen Tastatur erfasst werden können. Zu diesem Zweck hat sich aus Sicht von VerbaAlpina der sog. Betacode bewährt, bei dem solche Zeichen in Abfolgen von ASCII-Zeichen übersetzt werden. Das andere Problem bei der Erfassung von Sprecherbelegen aus Sprachatlanten besteht darin, dass die phonetischen Eigenheiten der Einzelbelege in die IPA-Referenztranskription überführt werden müssen. Denn erst dadurch wird Material aus unterschiedlichen Quellen in unterschiedlichen phonetischen Transkriptionssystemen vergleichbar. Soweit möglich erfolgt diese Umsetzung in die IPA-Transkription algorithmisch durch den Einsatz von Ersetzungsroutinen.
Generalmente il rilevamento del materiale degli atlanti si può difficilmente automatizzare e quindi bisogna farlo manualmente. A questo punto si trovano dei problemi con la trascrizione fonetica specialmente con le attestazioni individuali. Questo è un problema doppio: anzitutto si deve trovare un modo come si possono usare i simboli idiosincratici, che non sono ancora codificati in Unicode, con una tastiera europea occidentale. A ciò,dal nostro punto di vista, il cosiddetto betacode, in cui questi simboli sono tradotti in successioni dei simboli di ASCII, ha dato buona prova. L’altro problema con il rilevamento delle attestazioni dai informatori è quello: si devono trasferire le particolarità fonetiche delle attestazioni nella trascrizione di riferimento di IPA. Non primo d'ora il materilae delle fonti varie in sistemi di trascrizione fonetici diversi è comparabile. Per quanto è possibile questa trasposizione in IPA risulta usando un'algoritmo di sostituzione

b. VALTS
Anders als der AIS folgt der "Vorarlberger Sprachatlas" der Tradition der germanistischen Sprachatlanten, die im wesentlichen mit Punktsymbolkarten arbeiten und den Einzelbeleg nur in Ausnahmefällen präsentieren. In den meisten Fällen lassen sich aus den VALTS-Karten demnach nur morphologische Typen ablesen. Das folgende Beispiel zeigt die VALTS-Karte IV 73, die den Konzepten "Sennhütte" und "Sennereiraum" gewidmet ist – wodurch bereits deutlich wird, dass bei der Erfassung dieser Karte im Einzelfall unterschieden werden muss, ob sich ein Datum auf "Sennhütte" oder auf "Sennereiraum" bezieht. Insofern besteht hier das gleich Problem wie im Fall des AIS. Hier nun der Ausschnitt aus der entsprechenden Karte:
Diverso dall'AIS, l'atlante "Voralberger Sprachatlas" (atlante linguistico di Voralberg) segue le tradizioni degli atlanti linguistici germanistici, che funzionano in generale con carte simboli e a punti e presentano le attestazioni solo nel caso concreto. Dalle carte del VALTS si possono dunque rilevare solo i tipi morfologici. L'esempio mostra la carta del VALTS IV 73, che è dedicata aiconcetti "cascina di montagna" e "stanza nella cascina di montagna" , così è già evidente che durante il rilevamento si deve differenziare se la data si riferisce al concetto "cascina" o "stanza nella cascina". Dunque c'è lo stesso problema come nell'AIS. Ora vorrei mostrarVi il frammento della carte equivalente:

Wie man sieht, präsentiert die Karte einen Mix aus phonetischen Typen wie "Tieje" oder "Taje" und morphologischen Typen wie "Hütte" und "Sennküche", wobei dieser letztere Typus eben nicht die Hütte als Ganzes, sondern nur einen Teil derselben, nämlich das Konzept "SENNEREIRAUM INNERHALB DER ALPHÜTTE" bezeichnet. Das grün markierte Exemplum wiederum illustriert den Fall, dass zusätzlich zur Angabe des morphologischen Typs ein konkreter Sprecherbeleg geliefert wird.
Si vede che la carta presenta un misto dei tipi fonetici come "Tieje" o "Taje" e i tipi morfologici come "Hütte" (baita) e "Sennküche" (cucina nella cascina di montagna) , in cui però l'ulimo tipo appunto non significa la cascina in tutto, bensì solamente una parte di essa, cioè "stanza dove si lavora il latte ed il formaggio nella cascina di montagna". L'esmpio in verde invece mostra il caso in cui inoltre al tipo morfologico viene rappresentato l'attestazione concreta dell'informatore.
Die Abbildung dieser Informationen in der VerbaAlpina-Datenbank sieht in schematischer Darstellung wie folgt aus. Die Farben der Tabelle beziehen sich auf die Markierungen der soeben gezeigten Karte:
L'illustrazione di questa informazione è realizzata nella banca dati di VerbaAlpina in modo schematico seguente. I colori della tabella corrispondano alle marcature della carta appena mostrata.

Im Fall der "Sennküche" enthält der VALTS uns den Einzelbeleg vor. Auf diese Weise können die Felder "Beleg" sowie, in Abhängigkeit davon, "Betacode" und "IPA" nicht befüllt werden. In unserer Graphik haben wir daher an dieser Stelle Fragezeichen eingetragen, in der Datenbank bleiben die Felder schlichtweg leer. Und im Fall der phonetischen Typen "Taje" und "Tieje" benennt der Atlas keinen morphologischen Typen, der demnach von VerbaAlpina identifiziert bzw. ergänzt werden *muss*, da es sich hierbei um die Leitkategorie von VerbaAlpina handelt. Dieser Schritt verlangt Expertenwissen und erfolgt in der Weise, dass aus einem oder mehreren Referenzwörterbüchern ein – oder gegebenenfalls auch mehrere – nach Ansicht des Bearbeiters passende Lemmata zugeordnet werden. Im vorliegenden Fall wurde der Eintrag "Teie" aus dem Schweizerischen Idiotikon gewählt:
Nel caso del concetto "cucina nella cascina di montagna in cui si lavora il latte ed il formaggio" il VALTS non dichiara le attestazioni. In conseguenza le celle "attestazione","Betacode" e "IPA" non possono essere definiti. Nella nostra grafica mettiamo dunque il punto interrogativo. Nella banca dati queste celle restano semplicemente vuote. E nel caso di "Taje" e "Tieje" l'atlante non propone un tipo morfologico. Il quale deve essere identificato cioè completato da VerbaAlpina, poichè si tratta di una categoria principale di VerbaAlpina. Questo passo chiede delle conoscienze speciali e viene realizzato in questo modo: assegniamo da uno o alcuni dizionari di riferimento, dipende dalla opinione dell'elaboratore, una lemma adeguata. Nel caso presente abbiamo scelto la registrazione di "Teie" del IDITIKON, un dizionario del tedesco svizzero.

3. Cooperazione
c. Daten aus Partnerprojekten
VerbaAlpina besitzt Kooperationvereinbarungen mit einer Vielzahl von Partnern, von denen die meisten selbst über georeferenzierte Sprachdaten verfügen. Wie gerade bei den Sprachatlanten demonstriert, so geht es auch bei den Daten der Partner darum, diese im Sinne der VerbaAlpina-Strukturen zu klassifizieren und in den VerbaAlpina-Datenbestand zu integrieren. Da es bislang keine verbindlichen Standards gibt, muss für die Daten eines jeden Projektpartners eine eigene Schnittstelle entworfen und realisiert werden, die die Strukturen und Kodierungen der Fremddaten den Standards von VerbaAlpina angleichen.
VerbaAlpina ha degli accordi di cooperazione con una moltitudine di partner, dai cui la maggior parte dispone già dei dati linguistici georeferenziati. Come Vi abbiamo già dimostrato con gli atlantici linguisitici si tratta anche con i dati dei partner di una classificazione nel senso di VerbaAlpina e di una integrazione nel file dei dati. Siccome finora non esiste uno standard vincolante, si deve creare e realizzare un'interfaccia particolare per i dati di ognuno dei partner, che adatta le strutture e le codifiche dai dati stranieri allo standard di VerbaAlpina.
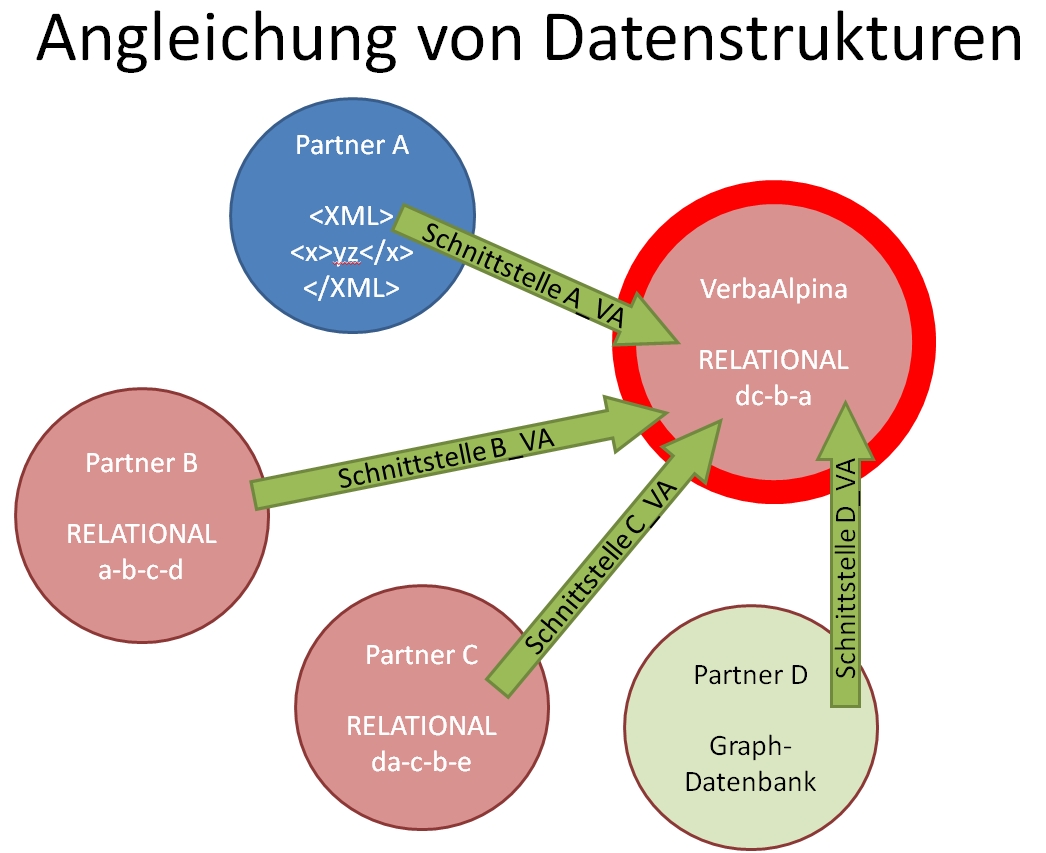
Sofern unsere Partner ebenfalls das relationale Datenmodell verwenden, stellen wir eine MySQL-Datenbank zur Verfügung, die nicht nur für den Datentransfer gedacht ist, sondern von unseren Partnern auch produktiv genutzt werden kann.
Purché i nostri partner usino anche il modello relazionale, mettiamo a disposiszione una banca dati di MySQL, che non si può usare solamente per il trasferimento dei dati, ma anche per l'uso produttivo dei partner.
1. "Archivio lessicale dei dialetti trentini" (ALTR)
VerbaAlpina hat bereits Daten von Kooperationspartnern erhalten. Das folgende Exemplum bezieht sich auf unser Partnerprojekt "Archivio lessicale dei dialetti trentini" (ALTR), geleitet von Patricia Cordin. Die Daten des ALTR sind gespeichert in der MySQL-Datenbank PVA_ALTR, wobei das Kürzel "PVA_" für "Partner von VerbaAlpina" steht. Ebenso wie viele andere unserer Quellen und Projektpartner verwendet auch der ALTR sein eigenes phonetisches Transkriptionssystem, das für die Zwecke von VerbaAlpina in die Referenztranskription IPA übertragen werden muss. Das Vorgehen ist dabei im wesentlichen so, wie oben im Zusammenhang mit dem AIS bereits beschrieben, so dass wir darauf nicht näher einzugehen brauchen. Komfortabel ist – verglichen z.B. mit dem AIS – natürlich, dass die Arbeit der manuellen Datenerfassung hier entfällt.
VerbaAlpina ha già ricevuto dei dati dei partner di cooperazione. L'esempio seguente si riferisce al nostro partner-proggeto "Archivio lessicale dei dialetti trentini" (ALTR) , condotto di Patrizia Cordin. I dati dell'ALTR sono salvati nellab banca di MySQL PV_ALTR. La sigla "PVA_" vuol dire : Partner di VerbaAlpina. Anche l'ALTR usa un proprio sistema di trascrizione fonetica, che si deve trasferire nella trascrizione di riferimento IPA per gli intendimenti di VerbaAlpina, come peraltro tanti delle nostri fonti e partner. Sostanzialmente il modo di agire è come abbiamo già spiegato nel contesto dell'AIS. Quindi non dobbiamo approfondire. Però naturalmente è più confortevole, confrontato all'AIS, che il rilevamento dei dati manuale venga omesso.
Anhand des ALTR lässt sich jedoch ein anderes Problem illustrieren, das auch bei verschiedenen anderen unserer Quellen auftritt, z.B. beim "Tirolischen Sprachatlas" (TSA). Hier geht es darum, Georeferenzierungen, die z.B. beim ALTR wenigstens teilweise flächenbezogen erfolgen, in das VA-System der Punktreferenzierung zu übertragen.
Pero con l'ALTR si può illustrare un altro problema, che si vede anche da alcune altre fonti. Per esempio al TSA (atlante linguistico del Tirolo). Qui si tratta di un trasferimento dei dati georeferenziati , che vengono rilevati in parte anche riguardando la superficie , per esempio dall'ALTR , nella sistematicità di VA di riferimento a punti.

Dem ursprünglichen Eintrag im ALTR (Markierung "A") ist zu entnehmen, dass der phonetische Typ "agraiöl" (eine Bezeichnung für ein Gefäß zur Aufbewahrung von Lab) in der Alta Val di Sole vorkommt. Darüberhinaus gibt es in bestimmten Ortschaften Varianten, nämlich "agraöl" in Peio und Vermiglio sowie "agröl" in Pellizano. Der in der ALTR-Datenbank dokumentierten regionalen Aufteilung zufolge (Markierung "B") gehören die beiden Ortschaften Vermiglio und Mezzana zur Alta Val di Sole. Daraus folgt, dass der Typ "agraiol" in diesen beiden Ortschaften belegt ist. Der Bemerkung im Feld Varianti_in_uso zufolge existiert jedoch in Vermiglio eine Variante, nämlich "agraöl" – ein Typ der seinerseits wiederum in Peio begegnet, einer Ortschaft, die in der Val di Peio liegt. Die Variante "agröl" schließlich ist für die Ortschaft Pellizano belegt, die sich ebenfalls außerhalb der Alta Val di Sole befindet. Durch das Gebot der Punktreferenzierung bei gleichzeitiger Unterscheidung verschiedener phonetischer Typen erfolgt die Speicherung der beschriebenen Daten in der Datenbank von VerbaAlpina in insgesamt fünf Datensätzen (Markierung "C").
Dalla registrazione originale dell'ALTR (Marcatura A) si capisce che il tipo fonetico “agraöil” (un'espressione per la conservazione del caglio) esiste nella Alta Val di Sole. Oltre a ciò si trovano delle variazioni nei certi luoghi, per esempio “agraöl” in Peio e Vermiglio o “agröl” in Pelliziano. Seguendo la divisione regionale (Marcatura B), che è documentata nella banca dati dell'ALTR, i luoghi Vermiglio e Mezzana fanno parte di Alta Val di Sole. Ne consegue che il tipo “agraiol” è attestato nei due luoghi. Ma secondo il commento nella cella Varianti_in_uso esiste una variante a Vermiglio, “agraöl” – un tipo che è attestato a Peio, e questo è un luogo che si trova nella Val di Peio. La variante “agröl” infine è attestata nel luogo Pelliziano, che si trova anche fuori dalla Alta Val di Sole. Sulla base del riferimento a punti, differenziamo contemporaneamente diversi tipi fonetici e l'archiviazione dei dati appena descritti risulta nella banca dati di VA in cinque passi. (Marcatura C)
2. Der "Atlant linguistich dl ladin dolomitich y di dialec vejins", 2a pert (Sprachatlas des Dolomitenladinischen und angrenzender Dialekte, 2. Teil) von Hans Goebl (ALD-II)
Ebenfalls bereits in relationaler Gestalt liegen die Daten des ALD-II vor. Darüberhinaus ist in diesem Korpus eine Punktreferenzierung der Sprachdaten gegeben. Bei den Sprachdaten selbst handelt es sich um unmittelbare Einzelbelege. Die Angleichung der Strukturen an VA_DB ist daher vollkommen unproblematisch. Die einzige Herausforderung besteht in diesem Fall in der Überführung des ALD-Transkriptionssystems in IPA, die in zwei Schritten erfolgt: Zunächst wird der ALD-eigene Betacode, also eine Transkription, die quasi ausschließlich mit ASCII-Zeichen auskommt, nach den ALD-Regeln, die u.a. in der Zeitschrift Ladinia publiziert wurden, in ein Transkriptionssystem übersetzt, das dem Böhmer-Ascoli-System ähnelt. Diese Transkription wird anschließend in IPA übertragen. Beide Schritte erfolgen automatisch durch den Einsatz von Ersetzungsroutinen.
2. L'atlante del ladino dolomitico e dei dialetti in vicinanza ?
Altrettanto abbiamo già in forma relazionale i dati del ALD-II. Oltre a ciò in questo corpus c'è un riferimento a punti dei dati linguistici.I dati linguisitici sono in sé per sé delle attestazioni dirette. Quindi per l'adeguamento strutturale a VA_BD non ci sono problemi. L'unica sfida è in questo caso il trasferimento del sistema di trascrizione del ALD in IPA. Il trasferimento viene effettuato in due passi: anzitutto si traduce seguendo le regole dell'ALD, che sono stati pubblicati fra l'altro nella rivista 'Ladinia' ,il Betacode del ALD, una trascrizione che funziona quasi solamente con simboli di ASCII, in un sistema di trascrizione che assomiglia al sistema di Böhmer-Ascoli.In seguito questa trascrizione viene trasferita in IPA. I due passi vengono effettuati automaticamente con l'uso di algoritmi di sostituzione.

Sämtliche aus den unterschiedlichen Quellen zusammengetragenen und hinsichtlich Struktur und Kodierung vereinheitliche Daten werden den Projektpartnern über die Schnittstelle VAP zur Verfügung gestellt. Die Schnittstelle liegt in drei verschiedenen Sprachversionen vor, nämlich Italienisch (VAP_it), Französisch (VAP_fr) und Deutsch (VAP_de). Die Schnittstelle ist über die Adresse https://pma.gwi.uni-muenchen.de:8888 erreichbar und enthält folgende Datenfelder:
Tutti i dati, che sono raccolti da fonti varie e sono stati standardizzati in riferimento alla struttura e la codifica ,vengono messi a disposizione ai partner usando l'interfaccia VAP. L'interfaccia esiste in tre lingue diverse, italiano, (VAP_it), francese (VAP_fr) e tedesco (VAP_de). Questa interfaccia è accessibile con l'indirizzo web https://pma.gwi.uni-muenchen.de:8888 e contiene le celle dei dati seguenti:

Wörterbücher
4. Rilevamento (Crowd)
Questa funzione non è ancora attiva; è prevista una'applicazione che si rivolge direttamente ai locutori per rilevare dati linguistici recenti; questa funzione sarà utilissima per vari motivi. Innanzitutto fornisce dati recenti, capaci di confermare, di attualizzare e di aricchire i dati atlantistici e lessicografici mai completi e delle volte anche invecchiati o imprecisi. Facciamo un esempio. AIS 1192 LA CASCINA DI MONTAGNA e AIS 1192a ## danno 1032 attestazioni per diversi tipi di fabbricati alpestri e il cambio d'alpeggio in 134 paesi alpini. Tutto il materiale linguistico è raggruppato sotto il titolo della carta e sotto i titoli di parecchi elenchi supplementari:
- LA CASCINA DI MONTAGNA
- LA CANTINA DA LATTE
- LA CANTINA DA FORMAGGIO
- I 'MAGGENGHI'
- LA STALLA D'ALPE
- LA CAMERA DA LETTO NELLA CASCINA
- VARIE CAPANNE
- TRAMUTARSI
A prima vista sembrano essere rapporti univoci tra designazioni e concetti. Moltissime attestazioni sono però precisate per quanto riguarda la materia, la costruzione, la funzione ecc. del fabbricato, in modo che ne risultano 120 concetti subordinati potenziali, senza che sia chiaro se queste precisazioni esprimono tratti semantici del tipo lessicale o, magari, delle qualità di un referente particolare. Un nuovo rilevamento chiarirebbe dunque la semantica e ci fornirebbe informazioni su eventuali sostituzioni delle parole ecc.

5. Pubblicazione
E’ chiaro che la documentazione sul web rappresenta in sé già una forma di pubblicazione; VA però non si accontenta di documentare dati grezzi. La piattaforma comprende anche diverse rubriche per testi linguistici che focalizzano in parte lo stesso progetto e in parte il materiale offerto da esso.
invitati da
(1) Il tab METODOLOGIA dà accesso a un elenco ragionato di alcuni concetti chiave di VerbaAlpina, in modo di chiarire i principi scientifici del progetto.
(2) Sotto il tab TESTI sono registrati innanzitutto contributi che discutono dati o aspetti metodologici di VerbaAlpina; si trovano saggi dei collaboratori ma ovviamente sono molto graditi anche articoli 'esterni', a condizione di trattare problemi rilevanti. Vengono distinti contributi pubblicati altrove (pubblicazioni esterne), studi originali (come questo testo sott'occhio) e materiale informativo.
(3) Ogni categoria che si può selezionare sulla carta interattiva (dati extralinguistici, concetti, carte sinottiche) può essere accompagnato di un commento (vd. Käse). Si potrebbero quindi inserire perfettamente i testi analici dell'Atlas des patois valdôtains e si aspetta che i partner che forniscono dati o che compongono nuove carte sinottiche scrivono pure commenti corrispondenti.
Va detto finalmente che la piattaforma coinvolgerà al di là delle cooperazioni con progetti scientifici anche locutori non linguisti; ma si tenga conto che entrambe le categorie non possono avere gli stessi diritte: i progetti partner dispongono ognuno di un database particolare dentro l‘architettura di VerbaAlpina che possono modificare liberamente; sono anche invitati a pubblicare commenti e contribut
Va detto finalmente che la piattaforma coninvolgerà al di là delle cooperazioni con progetti scientifici anche locutori non linguisti; ma si tenga conto che entrambe le categorie non possono avere gli stessi diritte: i progetti partner dispongono ognuno di un database particolare dentro l‘architettura di VerbaAlpina che possono modificare liberamente; sono anche invitati a pubblicare commenti e contribute nelle funzioni presentati. Eventuali commenti da parte degli utenti non linguisti non saranno mai pubblicati senza valutatazione positiva dai linguisti responsabili del progetto.
Bibliographie
- LSI = Lurà, Franco (Hrsg.) (2004): Lessico dialettale della Svizzera italana, Bellinzona, Centro di dialettologia e di etnografia
- RID = Lurà, Franco/ Galfetti, Johannes (2013): Repertorio italiano – dialetti, Bellinzona, Centro di dialettologia e di etnografia, CDE