

Abstract
Since 2014 the DFG-funded long term project VerbaAlpina (VA) is run at the Ludwig-Maximilians-University of Munich (LMU). VA is a cooperation of the Institute of Romance Studies and the LMU Center for Digital Humanities (DH; IT-Gruppe Geisteswissenschaften).
The project focuses on lexical variation throughout the Alpine area as defined by the so-called Alpine Convention (https://www.alpconv.org/). Whereas geolinguistic research within the Alpine region is traditionally orientated towards the spread of national languages and towards political borders, VA takes the homogeneous natural environment of the mountaneous region and the resulting uniform habitat conditions and ways of living as the guiding parameters defining its area of research.
VA is conceptualized as a strictly digital project that uses web technology for various purposes such as documentation, publication and visualisation. VA takes its data from traditional geolinguistic publications, mainly linguistic atlases and suitable dictionaries (i.e. dictionaries providing geographic information). The strictly digital approach is associated with several challenges starting from the difficulties regarding the transcription of the sometimes complex phonetic characters that are used especially in some of the linguistic atlases. VA has developed a series of specific reusable and freely available online tools that are used within the workflow of digitizing data from the printed sources. Another tool, the so-called Crowdsourcing tool, was built for gathering speech data from online users with the aim of filling documentation gaps that result from inconsistencies of the available printed sources.
An interactive online map that is using performant up-to-date graphical technology (WebGL) offers suggestive qualitative and quantitative visualisation of geographic distribution patterns from onomasiological and/or semasiological perspectives. These can also be combined with non linguistic data such as the sites of latin inscriptions.
In addition to the geolinguistic core themes of the project, VA is providing methodological reflexion on many of the issues deriving from the strictly digital orientation that should be of interest also beyond the borders of the project and even beyond the field of geolinguistics. In general, VA is looking for perspectives and solutions that allow the linkage of lexical data across so far isolated domains of geolinguistic research projects with the option of real interoperability (the “I” in the acronym FAIR).
The talk will provide more detailed information on the mentioned aspects of the project VerbaAlpina.
Talk*
Einführung
Ein Wort vorab: Nach wie vor ist es üblich, bei Vorträgen mit PowerPoint-Präsentationen zu arbeiten. Es gehört zum Konzept von VerbaAlpina, darauf zu verzichten, und die Vorträge stattdessen als WordPress-Beiträge zu konzipieren, die im Internet frei verfügbar sind. Der Grund ist, dass PowerPoint-Präsentationen nicht "FAIR", also findable, accessible, interoperable und reusable sind, VerbaAlpina jedoch größten Wert auf die Einhaltung dieser Prinzipien legt. Mit WordPress-Beiträgen ist dies deutlich besser gewährleistet.
Some of you might already know our project VerbaAlpina, regardless I want to start my talk by sketching the overall frameset of VerbaAlpina in short terms.
Scientific Approach
VerbaAlpina ist ein im wesentlichen lexikalisch ausgerichtetes sprachwissenschaftliches Projekt. Im Zentrum des Interesses steht die vor der Hand einfache Frage, welche sprachlichen Bezeichnungen für ganz bestimmte Konzepte im Alpenraum verbreitet sind. Die Dokumentation ist dabei beschränkt auf Konzepte, die typisch für den Alpenraum sind, wie etwa die Alm- und Milchwirtschaft oder auch die spezifisch alpine Tier- und Pflanzenwelt. Eine aus Sicht der traditionellen Geolinguistik grundlegende Neuerung ist sicherlich der Zuschnitt des Untersuchungsgebiets, oder vielmehr die zugrundeliegende Motivation, die nicht, wie verbreitet der Fall, politisch-administrative Konzepte wie etwa Staatsgebiete, sondern vielmehr die naturräumliche und in der Folge kulturelle Homogenität einer Region zum Auswahlkriterium macht.
Wie bereits gesagt, steht das lexikalische Material im Mittelpunkt des Interesses von VerbaAlpina. Der Datenbestand von VerbaAlpina basiert zum einen auf dem Material, das in traditionellen Sprachatlanten publiziert vorliegt. Zum anderen wurden auch Wörterbücher herangezogen, allerdings nur solche, deren Einträge auch Informationen zur geographischen Verbreitung der Bezeichnungen enthalten. Als Beispiel können das Schweizerdeutsche Idiotikon oder auch der Dizionario di Montagne di Trento von Corrado Grassi genannt werden. Letzterer dokumentiert die lokale Variation eines einzelnen kleinen Ortes in der italienischen Provinz Trento. Von den Sprachatlanten können als prominente Beispiele der Sprach- und Sachatlas Italiens und der Südschweiz (AIS) oder auch der Sprachatlas von Vorarlberg (VALTS) genannt werden.
VerbaAlpina versteht sich als durch und durch "digitales" Online-Projekt, das vollständig auf Publikationen in herkömmlicher Buch- oder Atlasform verzichtet. Mit "digital" ist hier überdies die Arbeit mit *strukturierten*, also um Metadaten angereicherten, Daten gemeint. Diese werden in einer relationalen Datenbank verwaltet.
Das Datenmodell von VerbaAlpina wird dominiert von der Wechselbeziehung zwischen der Welt der Sprache und der außersprachlichen Realität, also der Welt der Konzepte. Das nachfolgende Schema illustriert diese Wechselbeziehung und macht deutlich, dass grundsätzlich ein bestimmtes Wort mehr als nur ein Konzept bezeichnen kann und umgekehrt auch mehrere Wörter für ein und dasselbe Konzept existieren können. Zur klaren Unterscheidung zwischen Wörtern und Konzepten werden im Kontext von VerbaAlpina Konzepte stets in Versalien geschrieben:
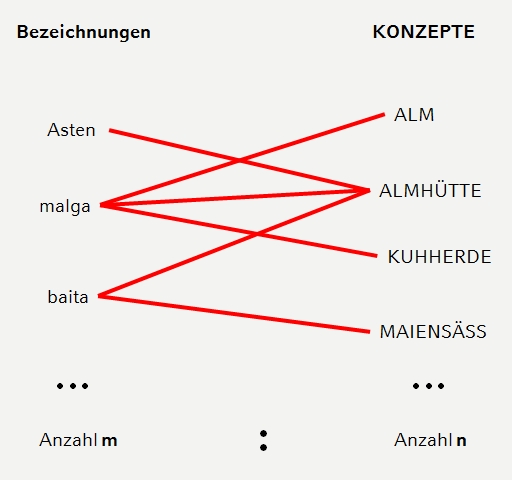
Zusammenhang zwischen Bezeichnungen und Konzepten
Dieses zunächst sehr simpel anmutende Basismodell erlangt sehr schnell hohe Komplexität durch die Hinzufügung der Dimensionen von Raum und Zeit. Denn bestimmte Bezeichnungen für bestimmte Konzepte sind nur in bestimmten Regionen gebräuchlich. Dabei können Lage und Größe dieser Regionen sich über die Zeit verändern oder auch ganz und gar verschwinden.
Die Fragestellung lautet also:
- Welche Wörter werden oder wurden
- an welchen Orten
- zu welcher Zeit zur Bezeichnung
- welcher Konzepte verwendet?
Da die Dimension des Raumes einen der zentralen Faktoren darstellt, sammelt VerbaAlpina ausschließlich Sprachmaterial mit Georeferenzierung, wie dies etwa in Sprachatlanten oder in manchen Wörterbüchern vorliegt.
Der Rahmen der räumlichen Dimension ist von VerbaAlpina durch das Perimeter der sog. Alpenkonvention abgesteckt. Die Alpenkonvention ist ein völkerrechtlicher Vertrag der Alpenanrainerstaaten. Das Perimeter ist eine von dieser Organisation gezogene Grenze, die die Ausdehnung der Alpen administrativ definiert. VerbaAlpina orientiert sich aus rein pragmatischen Gründen an dieser Grenze, da eine klare Abgrenzung des Untersuchungsgebiets organisatorisch unerlässlich und anders kaum möglich ist. Allerdings bedingt die gewählte Definition des Untersuchungsgebiets gewisse Asymmetrien, wie etwa die Tatsache, dass das Schweizerische Emmental, berühmt für seinen Käse, außerhalb der Alpenkonvention liegt und daher nicht von VerbaAlpina erfasst wird, obwohl diese Region in wirtschaftlicher wie auch naturräumlicher Hinsicht sehr wohl zum Alpenraum gerechnet werden könnte.
Innerhalb des Untersuchungsgebiets stellen für VerbaAlpina die politischen Gemeinden das zentrale Referenzsystem dar: Sämtliches gesammeltes und georeferenziertes Sprachmaterial wird auf das Raster der politischen Gemeinden bezogen. Bei großflächigen Verbreitungsangaben wie etwa "Tessin" oder "Vorarlberg" werden die entsprechenden Sprachbelege auf sämtliche Gemeinden dieser Regionen übertragen. Ausgehend von der feinen Granulierung der politischen Gemeinden kann das Sprachmaterial bei späteren Analysen nach übergeordneten politischen Einheiten wie etwa Kantonen, Départments, Regierungsbezirken oder Regionen gruppiert und auf einer Karte visualisiert werden.
Ein wenig problematisch ist aus Sicht von VerbaAlpina die Dimension der Zeit, da das Datennetz im Hinblick auf die chronologische Streuung bislang noch sehr dünn und bezogen auf den gesamten Alpenraum unausgewogen ist. Manche der von VerbaAlpina ausgewerteten Quellen geben den Zeitpunkt der Erhebung eines Einzelbelegs sehr exakt, manchmal sogar tagesgenau, an, bei anderen Quellen liefert das Jahr der Publikation lediglich einen Terminus ante quem für die darin erfassten Sprachdaten.
Das Datenmaterial von VerbaAlpina erhält historische Tiefe durch die Verklammerung der aus den Quellen geschöpften Wörter durch die Feststellung von Gemeinsamkeiten bezüglich der lexikalischen Basis. So besitzen französisch salamandre, italienisch salamandra und deutsch Salamander dieselbe lexikalische Basis. Hier einen historischen Zusammenhang zu vermuten, liegt nahe. Es lässt sich jedoch nicht ohne weiteres entscheiden, ob z.B. das deutsche Wort aus einem der beiden romanischen Wörter hervorgegangen ist (Entlehnungsszenario), oder ob alle drei Varianten unabhängig von einander auf einen gemeinsamen Vorläufer zurückzuführen sind. Um dennoch erfassen zu können, *dass* zwischen den drei genannten Wörtern ein Zusammenhang besteht, identifiziert VerbaAlpina in solchen Fällen einen lexikalischen Vorläufer aus einer früheren im Alpenraum verbreiteten Sprache und weist diesen den modernen Wörtern zu. VerbaAlpina bezeichnet solche Vorläufer als "Basistypen". Im Fall des Beispiels wäre dies das lateinische salamandra.
Der Grund für diese Vereinfachung ist ein doppelter: Zum einen ist vielfach nicht zu entscheiden, welche der genannten Varianten im Einzelfall vorliegt, zum anderen sind entsprechende Recherchen unter Umständen sehr aufwendig, so dass sie im Rahmen des Projekts aus Zeitgründen nicht betrieben werden können. Die VA-Basistypen haben den großen Vorteil, dass sie offenkundig bestehende Zusammenhänge datentechnisch abbilden lassen, *ohne* zur Spezifizierung der Zusammenhänge im einzelnen zu zwingen.
Die zentrale Bezugsgröße von VerbaAlpina sind die sog. "morpholexikalischen Typen", im folgenden kurz "Morphtypen" genannt. Dabei handelt es sich um lexikalische Einheiten, die bezüglich ihrer Sprachfamilienzugehörigkeit, ihrer Schreibung, des Genus und der Frage, ob sie eine Affigierung aufweisen oder nicht, distinkt, also unverwechselbar sind. Insofern entsprechen die Morphtypen in etwa den Lemmata der traditionellen Wörterbücher. Dabei handelt es sich ganz überwiegend um Nomina, Verben spielen bei VerbaAlpina bislang eine untergeordnete Rolle.
Bei der Typisierung orientiert sich VerbaAlpina zunächst an sog. Referenzwörterbüchern. Sofern in diesen Wörterbüchern ein passender Eintrag vorhanden ist, wird dieser den ausgewählten Tokens zugewiesen. Existiert der Typ in mehreren Referenzlexika, erfolgen Mehrfachzuordnungen. Sollte ein Morphtyp in keinem Referenzlexikon vorhanden sein, erzeugt VerbaAlpina einen eigenen, neuen Morphtypen, der dann zugewiesen wird.
Für die aus Sprachatlanten und Wörterbüchern erfassten Daten muss jeweils im Einzelfall entschieden werden, welchen Morphtypen sie repräsentieren. Eine automatische Zuweisung erscheint unmöglich. Für die manuelle Typisierung hat VerbaAlpina ein eigenes Tool entwickelt, in dem die transkribierten und anschließend tokenisierten Äußerungen Morphtypen zugeordnet werden können.
VerbaAlpina verzichtet bewusst auf die Zuweisung der Morphtypen zu Einzelsprachen oder gar Dialekten. Der Grund ist, dass sich Sprachlandschaften und so auch der Alpenraum grundsätzlich als Kontinua darstellen, innerhalb derer klare Abgrenzungen praktisch unmöglich sind. Streng genommen kann jede Ortschaft ihren eigenen Dialekt besitzen. Bei der Definition der Morphtypen erfolgt daher lediglich die Zuweisung zu einer der drei im Alpenraum vorhandenen Sprachfamilien. Die Zuordnung zu einer Sprachfamilie wird dabei von den Quellen vererbt, aus denen die Belege stammen, die dem jeweiligen Morphtypen angehören.
Die phonetische Dimension wird von VerbaAlpina weitgehend ausgeblendet, ist im Datenmodell von VerbaAlpina jedoch abbildbar und punktuell im Datenbestand auch schon präsent.
Die Entwicklung der Sprache im Raum ist stets mehr oder minder stark beeinflusst von einer ganzen Reihe dynamischer Prozesse. Dazu gehören etwa Wanderungsbewegungen, Verdrängungen, Landnahmen, der Wandel von Wirtschaftsformen oder auch der klimatischen Rahmenbedingungen. Aus diesem Grund sammelt VerbaAlpina – allerdings unsystematisch und selektiv – auch nicht-sprachliche Daten, die die genannten Phänomene dokumentieren. Als Beispiel können Daten zu archäologischen Fundstätten der Völkerwanderungszeit oder auch die Informationen zu Verkehrswegen und Ortschaften genannt werden, die der Tabula Peutingeriana entnommen werden können. Auch die Daten dieser außersprachlichen Peripherie müssen georeferenzierbar sein. VerbaAlpina bietet den Nutzern die Möglichkeit, diese Daten in Beziehung zur Verbreitung sprachlicher Phänomene zu setzen und auf diese Weise historische Zusammenhänge sichtbar werden zu lassen.
Technical Aspects
VA-Tools
VerbaAlpina setzt nach Möglichkeit weit verbreitete Standardsoftware ein, die außerdem open source sein muss. Im Wesentlichen handelt es sich um das Datenbankmanagementsystem (DBMS) MySQL zur Verwaltung des zentralen Datenbestands sowie um das PHP-Framework WordPress. Für die spezifischen Anforderungen des Projekts wurden jedoch überwiegend auf den genannten Basistechnologien aufbauende Tools entwickelt, die allesamt auf Github zur freien Nachnutzung unter der CC-BY-SA-Lizenz verfügbar sind (https://github.com/VerbaAlpina?tab=repositories).
Der VA-Betacode und das VA-Tanskriptionstool
Betacode
Für die Transkription von "exotischen" Schriftsystemen, wie sie häufig gerade in Sprachatlanten anzutreffen ist, setzt VerbaAlpina ein Verfahren ein, das bereits in den 1970er Jahren für den Thesaurus Linguae Graecae (TLG) entwickelt und erfolgreich eingesetzt worden war. Im Kern geht es darum, beliebige Schriftzeichen durch definierte und dokumentierte Sequenzen von ASCII-Zeichen zu ersetzen. Die Regeln folgen möglichst einfachen und mnemotechnisch günstigen Mustern. So wird z.B. ein Akut auf einem Basiszeichen durch einen Slash hinter dem Basiszeichen transkribiert.
Die Äußerung1
![]()
wird gemäß den Transkriptionsregeln folgendermaßen transkribiert:
la lac/a/
Dabei spielt der mit einem Zeichen bezeichnete Lautwert keine Rolle. Das bedeutet auch, dass identische Zeichen wie z.B. der Akut vollkommen unabhängig von der transkribierten Vorlage und der möglicherweise spezifischen phonetischen Bedeutung stets gleich, nämlich mit einem nachgestellten Slash transkribiert wird. Erst ein vorlagenspezifisches Konvertierungsverfahren, bei dem sämtliche Transkriptionen in das IPA-System übertragen werden, berücksichtigt die Lautwerte der ursprünglichen Quelle.
Diese Methode besitzt gleich mehrere Vorteile:
- Es ist die Transkription von Zeichen möglich, die bislang noch nicht unicode-kodiert sind
- Die Transkription kann bequem mit Standardtastaturen und ohne komplizierte Tastenkombinationen erfolgen
- Die Transkriptoren benötigen keine Kenntnisse über die Bedeutung der Zeichen
- Die Transkriptionen sind – anders als Multi-Byte-Characters von UTF-8 – technisch robust gegen ungewollte Veränderung
- Die Transkription erfolgt ohne Informationsverlust (was z.B. der Fall wäre, wenn anstelle des vorliegenden Böhmer-Ascoli-Systems direkt in IPA transkribiert werden würde, da IPA keine so feine Unterscheidung hinsichtlich der Einzellaute erlaubt wie Böhmer-Ascoli)
VA-Transkriptionstool
Speziell die automatische strukturierte Erfassung von lexikalischem Material aus Sprachatlanten stellt ein erhebliches technisches Problem dar. Dabei geht es nicht um die Verwandlung der, wie wir am Beispiel des AIS gesehen haben, teils exotischen Schriftsysteme, die dort bisweilen Verwendung finden. OCR-Programme wie z.B. Abbyy Finereader lassen sich so trainieren, dass sie auch solche Schriftsysteme korrekt erfassen und sogar den VerbaAlpina-spezifischen Betacode produzieren.
Im Fall der Sprachatlanten der romanistischen Tradition besteht die eigentliche Schwierigkeit darin, die direkt auf der Karte eingetragenen Äußerungen jeweils der richtigen Nummer zuzuordnen. Maschinen sind mit dieser Aufgabe immer dann überfordert, wenn die Eintragungen auf der Karte zu dicht beieinander liegen, wie dies z.B. im AIS im Bereich der Südschweiz und dem angrenzenden Italien der Fall ist. Am Institut für Informatik der LMU ist soeben eine Masterarbeit abgeschlossen worden, die eine algorithmische Lösung für dieses Problem entwerfen sollte. Dabei wurde u.a. mit Deep-Learning-Verfahren gearbeitet. Soweit VerbaAlpina es einschätzen kann, ist aber auch auf diesem Wege kein Erfolg in Sicht. Von einer technischen Verfügbarkeit eines entsprechenden Tools kann auf keinen Fall die Rede sein.
Aus Sicht der automatischen Datenerfassung noch komplizierter erscheinen die im Bereich der Germanistik verbreiteten Sprachatlanten mit Punktsymbolkarten, bei denen bestimmte Merkmalsausprägungen als Symbole auf der Karte dargestellt werden. Anders als bei den romanistischen Atlanten werden hier auch zumeist typisierte Daten abgebildet, konkrete Einzelbelege der Informanten werden nur in Ausnahmefällen präsentiert.
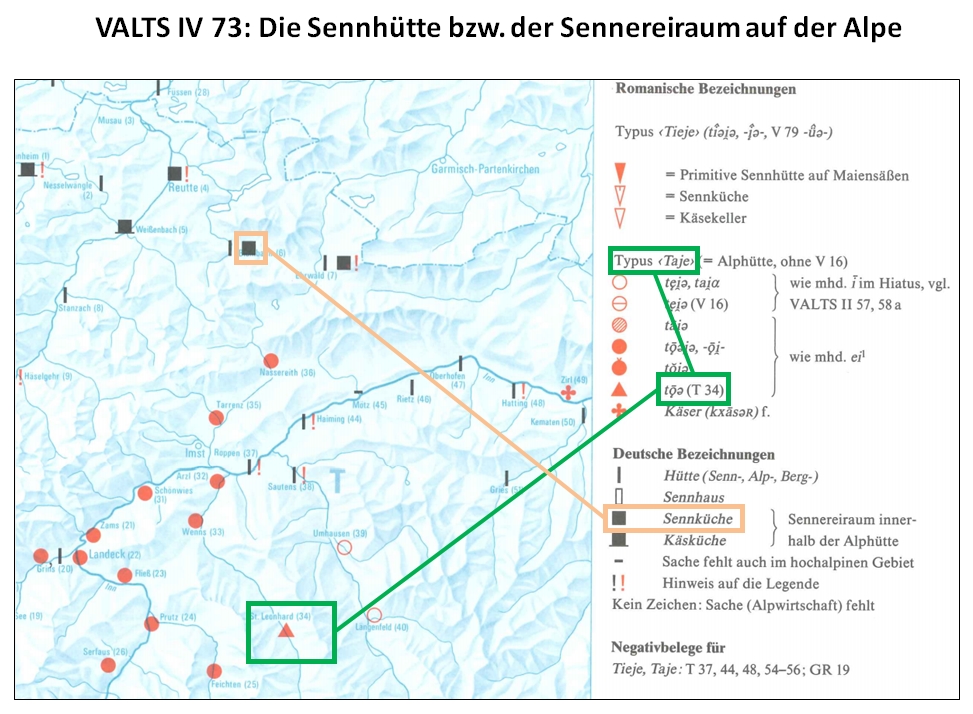
Punktsymbolkarte germanistischer Tradition (VALTS IV 73: Die SENNHÜTTE)
Das Tool integriert einen Scan der zu transkribierenden Karte in das Formular, in das die Transkriptionen eingetragen werden. Bereits transkribierte Karten werden entsprechend farblich markiert, und auch die Doppelerfassung einzelner Eintragungen auf der Karte werden vom System verhindert. Dem Transkriptor werden vom System nacheinander die Nummern oder Siglen der Ortspunkte auf der Karte vorgegeben. Die Transkription erfolgt dann in das dafür vorgesehen Feld des Formulars. Die anderen Parameter wie Kartennummer, Ortspunktnummer und Konzeptzuweisung sind vom System jeweils vorgegeben und werden gemeinsam mit der Transkription in der Datenbank abgespeichert. Die Eingabemaske präsentiert in einem Teilfenster rechts oben die allgemeinen Transkriptionsregeln für die Datenerfassung im Betacode, so dass der Transkriptor sie mit möglichst geringem Aufwand konsultieren kann. Zur Kontrolle für den Transkriptor wird rechts vom Eingabefeld simultan mit der Transkription die Originalschreibweise der Vorlage eingeblendet.
Crowdsourcingtool
Der von VerbaAlpina aus Sprachatlanten und Wörterbüchern zusammengetragene Datenbestand weist in mehrfacher Hinsicht Inkonsistenzen auf. Diese ergeben sich z.B. dadurch, dass die Sprachatlanten, die jeweils nur einen Teil des Alpenraums abdecken, nicht alle dieselben Konzepte dokumentieren, wie dies die folgende Abbildung ersichtlich macht:
[Screenshot]
In der Folge liegen also für eine bestimmte Region Bezeichnungen für Konzepte vor, die an anderer Stelle gar nicht abgefragt wurden – was nicht heißt, dass diese dort nicht existieren.
Die Durchführung von Nacherhebungen vor Ort ist nicht durchführbar. Daher setzt VerbaAlpina die Idee des Crowdsourcings ein, um den Datenbestand zu arrondieren. Die Idee ist, dass User im Internet bislang nicht dokumentierte Bezeichnungen für ausgewählte Konzepte beisteuern. Zu diesem Zweck hat VerbaAlpina ein spezielles Crowdsourcing-Tool (CS-Tool) entwickelt. Die Funktionalität ist bewusst simpel gehalten, um potentielle "Crowder" nicht abzuschrecken.
Jeder "Crowder" wird zu Beginn gefragt, welchem Dialekt seine Beiträge zuzuordnen sind. Anschließend muss er auf einer Karte einen Ort auswählen und gibt dann nach seiner Meinung an diesem Ort gebräuchliche Bezeichnungen für ausgewählte Konzepte ein. Das auf diese Weise gesammelte Material wird von VerbaAlpina ebenso typisiert wie die Daten aus Atlanten und Lexica. Eine Validierung des Crowd-Materials ist rein theoretisch durch das Prinzip der Fremdbestätigung möglich (Motto: Einmal ist kein Mal, zweimal ist immer), wird aktuell von VerbaAlpina aber nicht durchgeführt, nicht zuletzt, weil die Datenmenge bislang noch zu gering ist.
Die Erfahrung der vergangenen Jahre hat gezeigt, dass die Vitalität des Croudsourcing-Tools, also die Menge der Eintragungen, ganz entscheidend von entsprechenden Werbeaktivitäten abhängt. Nach Medien-Berichten über VerbaAlpina und sein Crowdsourcing-Tool oder entsprechende Propaganda in den sozialen Medien, steigen die Eintragungen jeweils stark an, sinken jedoch bald wieder ab.
Auch das CS-Tool kann unter der CC-BY-SA-Lizenz nachgenutzt werden.
Kartentool
Gleichsam das Schaufenster des Projekts bildet die interaktive Online-Karte. Sie ist als der zentrale Datenzugriffspunkt für die Öffentlichkeit konzipiert, der die Abbildung der Sprachdaten in der Dimension des Raums ermöglicht und somit Zusammenhänge offenbaren kann, die bei Betrachtung der Daten in Tabellen- oder Listenform häufig verborgen bleiben.
Die digitale Karte bietet sowohl die Möglichkeit, auf den Datenbestand aus der Perspektive der Wörter zuzugreifen, also sich die verschiedenen Konzepte kartieren zu lassen, die mit einem bestimmten Wort bezeichnet werden können, wie auch die Option, die umgekehrte Frage zu stellen: Welche Konzepte werden wo mit welchen Wörtern bezeichnet. Im traditionellen Publikationswesen konnten diese beiden Perspektiven nur durch zwei unterschiedliche Genera bedient werden: Den Sprachatlas und das Wörterbuch. Die digitale Online-Karte bietet sogar die Möglichkeit, beide Perspektiven synoptisch zu kartieren.
Die Karte bietet im wesentlichen zwei unterschiedliche Formen der Visualisierung an. Standard ist die qualitative Kartierung, bei der die Einzeldaten gebündelt nach politischen Gemeinden zunächst durch Symbole auf der Karte abgebildet werden. Das nachfolgende Beispiel zeigt die Kartierung der Verbreitung des romanischen Worttyps malga, gruppiert nach dessen regional unterschiedlichen Bedeutungen:
https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=191&tk=2414
Ein Klick auf die Kartensymbole öffnet ein Info-Window, in dem die zugrundeliegenden Sprachdaten präsentiert werden. Neben der Quelle werden auch das mit dem Wort bezeichnete Konzept, der Basistyp sowie der Einzelbeleg der jeweiligen Quelle in IPA-Transkription angezeigt. Die umrahmten Buchstaben hinter Morph- und Basistypen verweisen auf die entsprechenden Einträge in den Referenzwörterbüchern und sind z.T. interaktiv; ein Klick auf das Symbol führt dann direkt zum entsprechenden Eintrag im Referenzwörterbuch. In das Info-Window sind außerdem Normdaten eingebunden und entsprechend verlinkt. So führt ein Klick auf das Erdkugelsymbol neben oder unter dem Gemeindenamen auf die entsprechende Seite von Geonames, die Konzeptnamen sind mit den Einträgen bei Wikidata verknüpft.
Neben der qualitativen Kartierung bietet VerbaAlpina auch eine quantifizierende Darstellung an. Ein Klick auf das Q im Kreis neben dem Menüpunkt "Flächen und Regionen" kumuliert die im Moment kartierten Elemente nach Regionen und färbt diese entsprechend der Anzahl der dort kartierten Elemente unterschiedlich ein. In der Grundeinstellung bilden die großräumigen Sprachgebiete den Referenzrahmen. Durch entsprechende Auswahl über den Menüpunkt "Flächen und Regionen" kann die Kumulierung und Kartierung der Daten auch auf Basis kleinerer administrativer Einheiten erfolgen.
Neben der realitätstreuen Abbildung der geographischen Grenzverläufe kann die quantifizierende Darstellung auch auf der Grundlage einer Hexagonkarte erfolgen. Bei dieser Art der Kartendarstellung werden die geographischen Einheiten durch Hexagone mit jeweils identischer Größe dargestellt. Dadurch werden visuelle Verzerrungseffekte vermieden, die sich durch die in der Realität stark von einander unterscheidenden Flächengrößen ergeben. Natürlich ergibt sich bei dieser Art der Kartierung wiederum der Nachteil, dass die geographische Anordnung der Flächen und vor allem die Anzahl angrenzender Flächen in den meisten Fällen nicht mehr der Realität entspricht. Der Mehrwert besteht sicherlich in der Möglichkeit, zwischen den verschiedenen Kartierungsvarianten wechseln zu können und auf diese Weise einen annähernd objektiven Eindruck gewinnen zu können.
Das Teilensymbol am rechten oberen Rand der Karte erlaubt den Abruf eines persistenten Links, der stabil auf die aktuelle Kartenansicht verweist und z.B. über Mails versandt oder in Texte eingesetzt werden kann. Außerdem können ganz bestimmte Kartenansichten mit einer spezifischen Art und Anzahl von ausgewählten Daten als synoptische Karten unter einem frei wählbaren Namen gespeichert und mit einem ausführlichen Kommentar versehen werden. Anschließend erscheinen diese Karten im Menü "synoptische Karte". Allerdings ist diese Funktion registrierten Benutzern vorbehalten.
Die Realisierung der Online-Karte basiert auf modernster Graphiktechnologie (WebGL) und ist extrem leistungsfähig. Sichtbar wird diese Leistungsfähigkeit vor allem bei Zoom-Vorgängen mit einer großen Anzahl von Kartensymbolen und Grenzverläufen, die dem Computer eine hohe Rechenleistung abverlangen. Der Einsatz von WebGL erlaubt die erforderlichen Berechnungen auf dem Prozessor der Graphikkarte, was den entscheidenden Leistungsgewinn mit sich bringt.
Vernetzung und Nachhaltigkeit
Zugriffsmöglichkeiten von außerhalb
Der Zugriff auf die Daten von VerbaAlpina ist auf verschiedene Weise möglich:
- Über das im Internet frei zugängliche Projektportal und dort vor allem über die interaktive Online-Karte und das Lexicon alpinum
- Über die, ebenfalls frei zugängliche, API
- Über die PMA-Schnittstelle der MySQL-Datenbank
Die API erlaubt den Download des sprachlichen Kernmaterials in einer Reihe unterschiedlicher Formate und in unterschiedlicher Aggregierung. Der Zugriff über die PMA-Schnittstelle ist den offiziellen Kooperationspartnern von VerbaAlpina vorbehalten. Die PMA-Schnittstelle erlaubt Datenanalysen unter Einsatz der Sprache SQL.
Der Kerndatenbestand von VerbaAlpina ist sehr fein granuliert und die Einzelelemente sind mit persistenten Identifikatoren eindeutig identifiziert und somit präzise ansprechbar. Letztlich erfüllen diese alphanumerischen Identifikatoren die Funktion von VerbaAlpina-spezifischen Normdaten. Konkret erhalten unter anderem alle Morphtypen, Konzepte und politischen Gemeinden eine eindeutige Nummer, unter deren Verwendung dann auf unterschiedlichen Wegen auf die spezifischen Daten zugegriffen werden bzw. von externer Seite darauf referenziert werden kann. Identifikatoren der Morphtypen tragen das Präfix L, Konzepte C und Gemeinden A. Die ID L1435 steht beispielsweise für den Morphtypen "babeurre (m.) (roa.)". Die Adresse db=191&single=L1435" target="_BLANK">https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=133&db=191&single=L1435 ruft sodann eine Kartierung der Verbreitung dieses Morphtyps auf, der Link version=191&format=xml&empty=0" target="_BLANK">https://www.verba-alpina.gwi.uni-muenchen.de/?api=1&action=getRecord&id=L1435&version=191&format=xml&empty=0 führt zum Download der zu diesem Morphtyp gespeicherten Daten im XML-Format und der Link db=191#L1435" target="_BLANK">https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=2374&db=191#L1435 schließlich auf den Kommentar im Lexicon Alpinum (sofern vorhanden).
Mit wenigen Ausnahmen enthalten alle URLs, die sich auf Inhalte von VerbaAlpina beziehen, einen – in den Beispielen von gerade eben rot markierten – Parameter, der sich auf eine ganz bestimmte Version von VerbaAlpina bezieht. Die beiden ersten Ziffern stehen jeweils für das Jahr, die letzte für Versionsnummer im Jahr (191: Erste Version im Jahr 2019). Während der Datenbestand der Arbeitsversion, die an der Zeichenfolge xxx erkennbar ist, permanenten Änderungen unterliegt, sind die Inhalte der anderen Versionen jeweils stabil. Dadurch ist sichergestellt, dass Verweise auf diese URLs stets dieselben Inhalte aufrufen und Zitationssicherheit gewährleistet ist. Die Versionierung der VerbaAlpina-Daten erfolgt zweimal im Jahr, jeweils zu Jahresmitte und zu Jahresende. Auf der Homepage ist die Auswahl zwischen den vorhandenen Versionen möglich. Für alle Inhalte von VerbaAlpina sind auch DOIs verfügbar.2
Demnächst werden die VerbaAlpina-Daten auch in das RDF-Schema des Semantic Web übertragen. Die Einrichtung eines SPARQL-Endpoints ist jedoch zunächst nicht vorgesehen; die entsprechende Umsetzung ist mit einigem Aufwand verbunden und erscheint entbehrlich, da es eine Reihe anderer Zugriffsmöglichkeiten auf die VerbaAlpina-Daten gibt. Immerhin erfüllt VerbaAlpina die Kriterien der "Linguistic linked open data"-Bewegung (LLOD; http://linguistic-lod.org/).3, und die VerbaAlpina-Daten werden bald auch in die LLOD-Cloud eingebunden sein.4
Verknüpfung mit externen Ressourcen
VerbaAlpina verknüpft die drei Kernkategorien seines Datenbestands über die Einbindung geeigneter Normdaten mit externen Datenbeständen.
Im Fall der Morphtypen werden entsprechende Verbindungen zu den Referenzlexika hergestellt. Ein interessanter Nebeneffekt ist, dass dabei die unterschiedliche Eignung der entsprechenden Ressourcen deutlich wird. Im Sinne maximaler Interoperabilität sind bislang die Inhalte nur weniger der von VerbaAlpina erfassten Referenzwörterbücher adressierbar. Positive Beispiele wären etwa das Portal des Centre National de Ressources Textuelles et Lexicales ([Bibl:CNRTL]) oder die italienische Treccani, die jeweils transparente URLs für jeden lexikalischen Eintrag anbieten (z.B.: https://www.cnrtl.fr/definition/beurre, http://www.treccani.it/vocabolario/burro/). In manch anderen Fällen sind Referenzierungen entweder nur mit großer Ungenauigkeit oder auch gar nicht möglich. Nicht selten begegnet man dem Phänomen, dass sich die Adressierbarkeit der Inhalte noch an der herkömmlichen Seitenlogik des Buchdrucks und auf PDF-Dokumente oder Bilddateien bezieht. Dies ist etwa der Fall beim Französischen etymologischen Wörterbuch, ursprünglich von Walter Warburg (FEW).
Für die Konzepte verweist VerbaAlpina bislang ausschließlich auf die sog. Wikidata-Datenobjekte. Jedem Konzept ist in der VerbaAlpina-Datenbank die jeweilige Q-ID der Wikidata zugeordnet. Der entsprechende Link führt auf die Datenobjektseite bei Wikidata. Dort wiederum befinden sich Links zu den Artikeln in den verschiedensprachigen Wikipedien zu diesem Konzept. Bereits erwähnt wurde die Verknüpfung mit den Normdaten von geonames. Links für alle Normdaten der genannten Kategorien werden dem Nutzer in den Info-Windows auf der Online-Karte präsentiert.
Some organizational stuff
VerbaAlpina started in 2014 and is funded by the German Research Foundation (DFG) with a perspective until 2025. The individual project terms comprise 3 years each. At the moment we are heading towards the last year of the second term and are about to prepare the application for the funding of the third term.
Der Mitarbeiterstab ist zweigeteilt: Es gibt drei Sprachwissenschaftler und zwei Informatiker, die jeweils noch von Hilfskräften unterstützt werden. Unter den Sprachwissenschaftlern befinden sich zwei Romanisten und ein Germanist, von den Informatikern ist einer hauptsächlich für alle Belange der Kerndaten zuständig (Datenmodellierung, Schnittstellen, u.a. API), der andere überwiegend für alle Fragen der Visualisierung, hauptsächlich die interaktive Online-Karte.
VerbaAlpina stellt somit ein interdisziplinäres DH-Unternehmen mit Anteilen in den klassischen Geisteswissenschaften und in der Informatik dar. Der informatische Teil ist an der IT-Gruppe Geisteswissenschaften (ITG) angesiedelt. Diese Einrichtung besteht seit dem Jahr 2000, wird getragen von den sechs geisteswissenschaftlichen Fakultäten der LMU und besitzt eine unbefristete Existenzperspektive. Die ITG ist zuständig für Planung und Betrieb der IT-Infrastruktur im Bereich der Humanities. Einen stetig wachsenden Aufgabenbereich der ITG stellt die Unterstützung bei Planung und Durchführung von DH-Projekten dar. VerbaAlpina stellt aus Sicht der ITG also nur eines von zahlreichen Projekten dar, dessen Projektdaten im Kontext eines heterogenen, jedoch einheitlich – nämlich relational – strukturierten Gesamtdatenbestand verwaltet werden. Dieser im Lauf der Jahre auf beachtliche Größe und Vielfalt angewachsene Datenpool bietet zumindest theoretisch die Perspektive der Datenanalyse über Projektgrenzen hinweg. Vor diesem Hintergrund entwickelt sich zur Zeit eine Kooperation der ITG mit dem Master-Studiengang Data Science, der Anfang 2017 ins Leben gerufen wurde.
Die ITG spielt auch im Hinblick auf die Nachhaltigkeit der von VerbaAlpina erarbeiteten Ergebnisse eine wichtige Rolle. Nach dem Ende der Projektförderung wird die ITG das Projektportal im Rahmen ihrer Möglichkeiten weiter betreiben und das für den Betrieb erforderliche Minimum an Wartungsarbeit leisten.
* Given at the colloqium „NEW WAYS OF ANALYZING DIALECTAL VARIATION“, held at Sorbonne University, Paris, 21-23 November 2019
AIS 1218_1, 129 ↩
Fragezeichen und Ampersands (&) müssen dabei durch den jeweiligen Hexadezimalwert des Zeichens in der Unicode-Tabelle (? = 3f, & = 26) mit vorangestelltem % ersetzt werden. Die DOI der URL https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=133&db=191&single=L1435 liest sich wie folgt: https://dx.doi.org/10.5282/verba-alpina?urlappend=/%3fpage_id=133%26db=191%26single=L1435 ↩
S. Chiarcos, Christian; McCrae, John; Cimiano, Philipp; Fellbaum, Christiane (2013). Towards open data for linguistics: Lexical Linked Data (PDF). Heidelberg, in: Alessandro Oltramari, Piek Vossen, Lu Qin, and Eduard Hovy (Hrsgg.), New Trends of Research in Ontologies and Lexical Resources. Springer. ↩
Die Erzeugung der RDF-Struktur wird derzeit vorbereitet. Die Registrierung erfolgt anschließend unter der Adresse https://lod-cloud.net/add-dataset ↩
Bibliographie
- FEW = Wartburg, Walter (1922-1967): Französisches etymologisches Wörterbuch. Eine Darstellung des galloromanischen Sprachschatzes , Basel, vol. 20, Zbinden. Link
- VALTS = Gabriel, Eugen (1985-2004): Vorarlberger Sprachatlas mit Einschluss des Fürstentums Liechtenstein, Westtirols und des Allgäus , vol. 1-5, Bregenz, vol. 1-5, Vorarlberger Landesbibliothek