Grundsätzliches
- VerbaAlpina (VA) beschäftigt sich mit der Frage, welche Bezeichnungen es für ausgewählte, für den Alpenraum typische Konzept/Begriffe es gab und gibt
- VA ist mit diesem Ziel ein von der DFG gefördertes Langfristvorhaben mit Perspektive bis 2025 (derzeit dritte Teilphase [2019-2022] in Beantragung)
- Die Untersuchung ist auf den Alpenraum beschränkt
- Die Grenze des Untersuchungsgebiets ist das Perimeter der sog. Alpenkonvention (Link)
- Das Sprachmaterial stammt hauptsächlich aus sog. Sprachatlanten und Wörterbüchern (letztere nur, wenn sie Auskunft über die regionale Verbreitung der verzeichneten Wörter geben; Beispiel: Idiotikon)
- Neben Sprachatlanten und Wörterbüchern verwendet VA Methoden des Crowdsourcing ("citizen science") zur Sammlung von Sprachmaterial (dazu später mehr)
- VA fragt nach der Verbreitung von Wörtern innerhalb des Alpenraums (welche Wörter werden wo verwendet und welche Bedeutung haben sie dort?)
- Im Hinblick auf die Wörter ist VA im Wesentlichen an sog. Morpholexikalischen Typen (Morphtypen) interessiert. Diese sind letztlich vergleichbar mit den Lemmata von Wörterbucheinträgen
- Ein Morphtyp im Sinn von VA wird definiert durch
- die Orthographie,
- die Zugehörigkeit zu einer Sprachfamilie (germanisch, romanisch, slawisch),
- die Wortart,
- das Genus und
- die Affigierung (letztere z. B. -chen in Häuschen ⇒ eigener Morphtyp neben Haus)
- Beispiel: la malga (romanisch, feminin, ohne Affigierung); zwei Morphtypen: die Butter und der Butter
- VA befasst sich in der Hauptsache mit Dialektausdrücken (also nicht mit den Hochsprachen)
- VA ist nur nachrangig an phonetischer Variation interessiert
- Das geographische Bezugssystem innerhalb der Alpenkonvention wird durch die politischen Gemeinden gebildet (5771; statisches Referenzystem; Änderungen werden nicht berücksichtigt)
- VA besitzt neben der diatopischen auch eine diachronische Dimension (Veränderungen über die Zeit; Sprachatlanten z. T. aus der 1. Hälfte des 20. Jh. ⇔ Daten aus dem Crowdsourcing von heute)
- Die Kernentitäten von VA sind demnach:
- Morphtyp
- Konzepte (zur Unterscheidung von Wörtern stets in Versalien geschrieben; BUTTER meine das Konzept, also die Sache als solche; Butter hingegen meint das Wort "Butter")
- Gemeinden
- [Zeit]
⇒ Das Wort xy wurde/wird in den Jahren jjjj in der/den Gemeinde(n) yz zur Bezeichnung des Konzepts KO verwendet
- Die Wechselbeziehung von Morphtypen und deren Bedeutung erzeugt vor dem Hintergrund von Raum und Zeit eine enorme Komplexität:
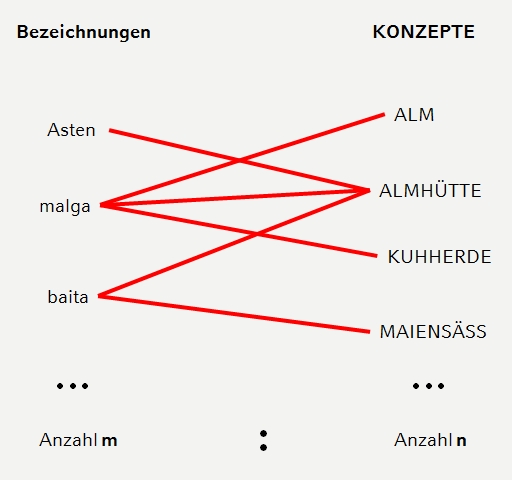
Zu den Kernentitäten gehört auch der sog. Basistyp. Damit sind Wörter gemeint, die in irgendeiner Weise ganz offenkundig mit einem Morphtypen verbunden sind, ohne dass der Zusammenhang im Detail geklärt werden kann. In aller Regel handelt es sich dabei um ältere Vorstufen. Hierzu ein Beispiel:
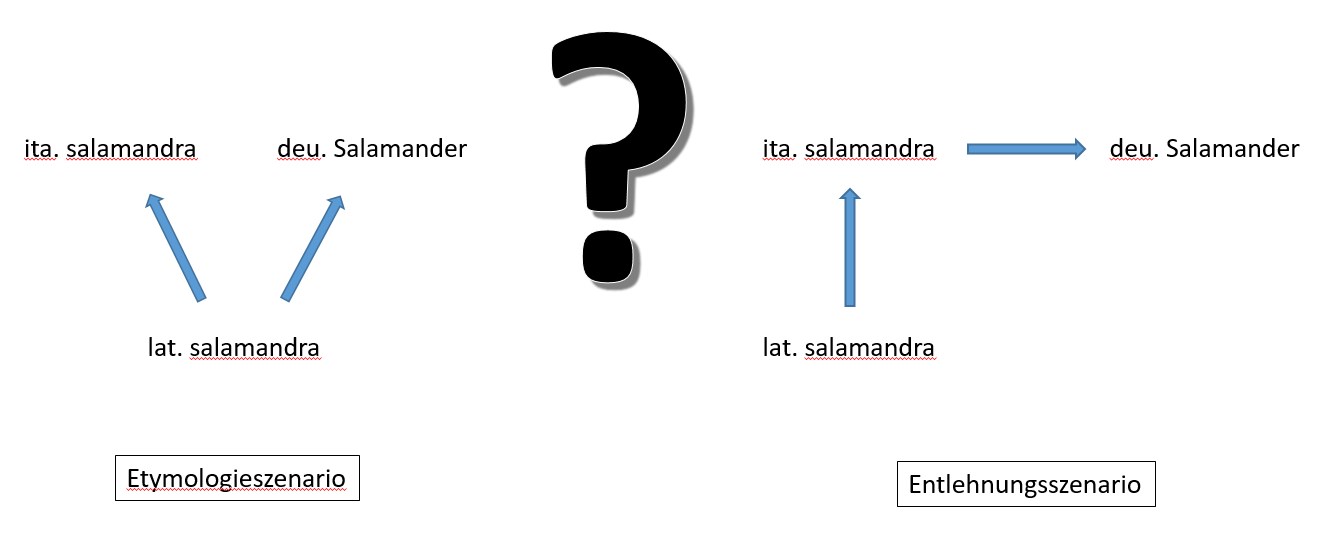
Das deutsche Wort Salamander hängt unverkennbar mit dem italienischen salamandra zusammen. Das Wort salamandra gab es schon im Lateinischen (Georges). Für das deutsche Salamander stellt sich nun die Frage, ob es sich direkt aus dem Lateinischen entwickelt hat (Etymologie-Szenario) oder ob es später aus dem Italienischen übernommen worden ist (Entlehnungs-Szenario). Fragen dieser Art sind häufig nur mit sehr großem Aufwand – wenn überhaupt – zu entscheiden. Dennoch besteht unverkennbar eine Verbindung. Um diese dokumentieren zu können, hat VA den Basistyp eingeführt. (anders als im Fall von lat. salamandra können manche Basistypen keiner spezifischen Sprache zugeordnet werden. Gleichwohl muss es sie gegeben haben. In solchen Fällen wird ein Basistyp rekonstruiert [Kennzeichnung durch * vor dem Basistypen]; Beispiel: *cala als Basistyp z. B. von frz. chalet)
- In Sprachatlanten und Wörterbüchern werden vielfach keine Morphtypen, sondern Einzelbelege oder phonetische Typen dokumentiert (z. B. Kaas, Chaas, Käs – alles Varianten des Morphtyps der Käse) ⇒ Quelldaten müssen klassifiziert werden (sog. "Typisierung")
- Im Zuge der Typisierung verknüpft VA nach Möglichkeit einen Morphtyp mit einem korrespondierenden Eintrag in einem sog. Referenzwörterbuch. Liste der Referenzwörterbücher (Beispiel: der Morphtyp "malga|rom|f|nicht affigiert" entspricht dem Eintrag malga im Vocabolario der Treccani; http://www.treccani.it/vocabolario/malga/)
- VA sammelt bis zu einem gewissen Grad auch Daten zur sog. außersprachlichen Peripherie. Als Beispiel können die Fundorte lateinischer Inschriften im Alpenraum genannt werden. Diese geben können einen Hinweis auf die Intensität der Romanisierung geben. Dies wiederum kann etwa die heutige Verbreitung romanischer Basistypen in bestimmten Regionen mehr oder weniger plausibel erscheinen lassen.
Technik
- VA ist ein rein digitales Projekt – praktisch vollkommener Verzicht auf traditionelle papiergebundene Methoden
- verwendet Standardsoftware, quasi ausschließlich open source
- knapp 50% der Projektbeteiligten sind im Informatik-Sektor des Projekts tätig (2 wiss. Mitarbeiter, 1 Hilfskraft)
Backend und Frontend
Backend
- Backend wird gebildet von einer MySQL-Datenbank
- Vorteile der MySQL-DB:
- Web-fähig
- an der ITG herrscht seit langem Expertise
- große Anzahl weiterer Projektdaten in der selben Server-Umgebung (MySQL-Cluster), so dass technische/inhaltliche Verknüpfung theoretisch möglich (Demo)
- Die VA-DB ist im Lauf der Zeit immer komplexer geworden (normaler Vorgang) – aktuell 156 Tabellen (Demo)
- Tabellen der Kernentitäten:
- Einzelbeleg: Tabellen "aeusserungen" und Tabelle "tokens"
- Morphtyp: Tabelle "morph_typen"
- Konzept: Tabelle "konzepte"
- Ortschaft: Tabelle "orte"
- Die Zusammenhänge zwischen den einzelnen Entitäten sind in der Datenbank aufgrund der sog. Normalisierung nur durch komplexe Operationen darstellbar. Nur eine kurze Skizze: Beispiel id_aeusserung = 89349
- Daher Bündelung der verteilten Informationen in sog. Datenzugriffsschicht: vap_ling_de ("Human-readable interface"; in mehreren Sprachen verfügbar) und z_ling (für Maschinen)
- jeweils aktuelle Arbeitsversion trägt den Namen va_xxx
- VA-DB wird alle halbe Jahre versioniert
- Erzeugung einer DB-Kopie, an der nichts mehr geändert wird.
- Suffix: _jjh (j=Jahr; h=Halbjahr), z. B. va_191: Datenbankversion der ersten Jahreshälfte 2019 (erzeugt Ende Juni/Anfang Juli; die Versionen der 2. Jahreshälfte werden gegen Ende Dezember erzeugt).
- Wichtig für Gewährleistung der Zitierfähigkeit! Ein Wechsel zwischen den Versionen ist im Frontend von VerbaAlpina möglich (Demo)
- neben der VA-DB existiert eine Reihe von Datenbanken der offiziellen VA-Partner (Kooperationsvereinbarungen; bislang insgesamt 53). Präfix: pva_ (= Partner von VerbaAlpina; Demo)
Frontend
- Standard-WordPress-Installation (Demo: https://www.verba-alpina.gwi.uni-muenchen.de/)
- auch hier wieder: Front- und Backend (Demo)
- ergänzt um Eigenentwicklungen, zumeist in Form von sog. Plugins (werden auf Github unter offenen Lizenzen (CC BY-SA, zur Nachnutzung zur Verfügung gestellt: https://github.com/VerbaAlpina/)
- Mehrsprachig: die wichtigsten Sprachen des Alpenraums + Englisch (verursacht großen Aufwand)
- Multifunktional:
- Arbeitsinstrument für Mitarbeiter
- Dokumentation
- Publikation
- Datensammlung
- Punkt Dokumentation: Methodologie (Reflexion vielfältiger Aspekte, sprachwissenschaftlicher ebenso wie informatischer) (Demo)
- Weitere Kern-Module des Frontend neben der Methodologie:
- Interaktive Karte (Demo: malga, HERDE;
- Integration von semasiologischer und onomasiologischer Perspektive;
- qualitative und quantitative Kartierung: quantitative Kartierung bildet die Häufigkeit der in einer Region auf der aktuellen Karte dargestellten Symbole durch Intensität der Flächenfärbung ab (Beispiel: malga|rom|f|- in der Bedeutung ALM)
- Kombination mit Daten der außersprachlichen Peripherie;
- Einbindung von Normdaten: Wikidata-Q-IDs und Geonames-IDs: Belegfenster malga ⇒ HERDE im Ort Stenico)
- Auf der Karte können auch individuelle Suchanfragen in SQL formuliert werden, die dann kartiert werden (Beispiel: liefer alle Einzelbelege des Morphtyps Butter, die mit einem "P" beginnen: where Type_Kind = 'L' AND Type = 'Butter' AND Instance like 'p%')
- Technisch hochperformant (Nutzung des Standards WebGL, der den direkten Zugriff auf die Grafikkarte erlaubt; s. den Methodologie-Eintrag)
- Lexicon Alpinum (Demo alt; Neuentwicklung! ⇒ Demo)
- Transkriptionstool: Operationalisierung der strukturierten Erfassung analoger Datenquellen, v. a. von Sprachatlanten (Demo; Verwendung des Betacodes ⇒ normale Tastatur, geringe Fehleranfälligkeit, schnell zu erlernen, keine Kenntnisse in phonetischer Transkription erforderlich; Automatisierung vor allem wegen Zuordnungsproblematik nicht möglich)
- Typisierungstool: Klassifizierung/Typisierung der digitalisierten Daten (Demo)
- Crowdsourcing-Tool(s) ...
- Interaktive Karte (Demo: malga, HERDE;
Einsatz von Crowdsourcing
- Motivation:
- Konsolidierung von Inkonsistenzen, die sich aus der inhomogenen Dokumentationslage auf Basis von Sprachatlanten und Wörterbüchern ergeben (Übersicht über unterschiedliche thematische Abdeckung verschiedener Atlanten) ⇒ regionale Begrenzung der Quellen und unterschiedlicher Inhalt: z. B. wird nicht jedes Konzept von jedem Sprachatlas berücksichtigt. ⇒ Beseitigung von Dokumentationslücken (Demo)
- Mithilfe bei Transkription (⇒ Zooniverse-Tool; ursprüngliche Absicht: Verwendung eines "Baukastens" ( Zooniverse Project Builder), der den Entwicklungsaufwand reduziert. Hoffnungen haben sich leider nicht bestätigt, Entwicklungsaufwand kaum geringer als bei Eigenentwicklung. Weiterer Nachteil: Nicht direkt ins VA-System integriert, sondern auf Server von Zooniverse. Bislang noch nicht beworben, daher noch nicht produktiv. Transkriptionsergebnisse müssen in csv-Datei exportiert werden, die dann in va-DB importiert wird. Entsprechende Prozedur wird derzeit entwickelt – (Demo) – Zooniverse ist ein "citizen science web portal ", das eine große Anzahl von Crowdsourcing-Projekten unterstützt und auf seinen Seiten hostet. Eines der sehr frühen Projekte: Klassifizierung von Glaxien, ähnliche Aufgabe wie bei VerbaAlpina: Transkription von Logbüchern von Arktisfahrern aus dem 19. und frühen 20. Jh. – Zooniverse ist an der Universität Oxford beheimatet und verfügt über eine sehr große Anzahl von *registrierten* freiwilligen "Crowdern" (über 1,5 Mio.); VerbaAlpina "not yet an official Zooniverse project" (aufwendiges Review-Verfahren)
- Die Vitalität des Crowd-Sourcing-Tools 1) wird überwacht: CSGRAPH
Nachhaltigkeit
- Sämtlicher "Output" von VA muss dauerhaft zugänglich und nutzbar sein
- Paradigma ist – in dieser Beziehung – das traditionelle Buch auf Papier
- Im Detail sind damit u. a. die folgenden Postulate verbunden:
- Die Daten müssen dauerhaft auffindbar sein (Buch: Bibliothekskataloge; wichtig: Es muss klar sein, an welche Institution ich mich wende. Bei einem Buch geht man selbstverständlich zur Bibliothek)
- Die Daten müssen dauerhaft zugänglich sein (Buch: Bibliotheken)
- Inhalte müssen präzise und stabil zitierbar sein (Buch: Seitenzahlen)
- Durch die Möglichkeiten der elektronischen Vernetzung kommen, gegenüber dem Paradigma des Buches, die folgenden Postulate hinzu:
- Projektdaten sollten mit Daten außerhalb des Projekts verknüpft werden können.
- Zu diesem Zweck müssen die Daten des Projekts zu Entitäten zusammengefasst werden. Jede Instanz einer Entität muss eindeutig identifizierbar sein und über eine elektronische Adresse ansprechbar sein.
- Die Kernentitäten von VA sind wiederum die oben bereits genannten:
- Morphtypen
- Konzepte
- Orte
- Basistypen
- Jede Instanz dieser Entitäten erhält einen innerhalb des Projekts eindeutigen Identifikator: Morphtypen Präfix L, Konzepte Präfix C, Orte Präfix A, Basistypen Präfix B) – Beispiele im Lexikon Alpinum
- Die Identifikatoren können auch als "Normdaten" bezeichnet werden – Unter Normdaten versteht man eindeutige, numerische oder alphanumerische Zeichenketten, die eine Instanz einer bestimmten Entität eindeutig identifizieren. Frühe Normdatensysteme sind z. B. im Kontext des Bibliothekswesens entstanden; ein Motiv dabei ist gewesen, Autoren mit gleichlautenden Namen eindeutig identifizieren zu können (⇒ häufige Personennamen wie im Deutschen "Schmid" oder "Meier"). Bekannte Normdatensysteme sind z. B. die Gemeinsame Normdatei (GND) der deutschen Nationalbibliothek (Suchportal; Demo: Krefeld [123778689], Alexander der Große [118501828]). Ein für VA relevantes Normdatensystem ist z. B. die Wikidata (Beispiel folgt gleich)
- Die projektspezifischen Normdaten können im Mapping-Verfahren mit bestehenden projektexternen Normdatensystem verknüpft werden (z. B. Wikidata-QIDs: VA-Konzept-ID C612 [ALMHÜTTE] ⇒ Wikidata Q-ID Q2649726])
- Sofern diese inhaltliche Verknüpfung nicht von Menschen, sondern von Maschinen geleistet werden soll, spricht man von Interoperabilität.
- Die interaktive Karte stellt im Hinblick auf die Zitierfähigkeit eine besondere Herausforderunge dar: Jeder User kann individuelle Kartenbilder erzeugen, die möglicherweise wesentlich für eine spezifische Argumentation sind. VA hat daher ein System entwickelt, das die Erzeugung individueller URLs erlaubt, deren Aufruf exakt das Kartenbild generiert, das bei Erzeugung der URL auf dem Bildschirm zu sehen war (Demo).
- Wesentliche Voraussetzung für die uneingeschränkte Nachnutzbarkeit von Projektdaten ist eine möglichst offene Lizenzpolitik. Seit einigen Jahren bietet hier die Initiative Creative Commons (CC; gemeinnützige Organisation, gegründet 2001) generische Lizenzmodelle. VA stellt all seine Inhalte, soweit möglich, unter der CC-Lizenz BY-SA zur Verfügung. Einzige Bedingung ist dabei nur die Nennung des ursprünglichen Urhebers (BY) und die Weitergabe der Daten unter eben dieser Bedingung (SA = share alike)
- Diese Postulate im Hinblick auf Nachhaltigkeit sind seit einigen Jahren im Akronym FAIR verankert (bereits von Thomas Krefeld angesprochen): Daten müssen Findable – Accessible – Interoperable und Reusable sein.
- Übertragung der VA-Daten an die UB der LMU, dabei Anreicherung um Metadaten (Prozeduren derzeit noch in der Entwicklung)
- Zu diesem Zweck: API (Application Programming Interface; dt: Programmierschnittstelle) – Ermöglicht Zugriff auf die Kerndaten von VA, gegliedert nach Morphtypen – Konzepten – Ortschaften – Einzelbelegen (Demo)
- Wozu Metadaten? – Ein simples Beispiel: VA spricht in seinem Datenbestand von "morpholexikalischem Typ". In einem anderen Projekt wird dasselbe Konzept etwa als "Lemma" bezeichnet. Die Inhalte beider Kategorien sind jedoch aufeinander zu beziehen. Damit Menschen – und mehr noch Maschinen – erkennen können, dass es sich um kongruente, mit einander zu verknüpfende Daten handelt, können die jeweiligen Datenbestände auf ein gemeinsames, nach Möglichkeit weithin bekanntes und anerkanntes Bezugssystem abgebildet werden. Meist verwendet das Metadatenschema ein alphanumerisches System, das bestimmte Entitäten eindeutig identifiziert.
- VA bzw. die UB der LMU verwenden zwei verschiedene, weit verbreitete Metadatenschemata, wobei das eine, vom Konsortium Datacite, im Wesentlichen für die Erfassung von üblicherweise in Bibliothekskatalogen erfassten Daten wie Autoren, Schlagwörter und Entstehungszeit und -ort bezieht (s. dazu den Best Practice Guide)
- Für die inhaltliche Tiefenerschließung findet das Metadatenschema CIDOC CRM (das Conceptual Reference Model [CRM] geht zurück auf eine Arbeitsgruppe des Comité International pour la Documentation [CIDOC], das seinerseits eine Gliederung des International Council of Museums (ICOM) darstellt; seit Anfang der 1990er Jahre) Anwendung (Dokumentation):