

Gliederung
2.1 Was ist Crowdsourcing?
2.2 Bereits angewandte Crowdsourcingsysteme
2.3 Crowdsourcing und Linguistik
2.4 Grenzen und Möglichkeiten im Umgang mit Crowdsourcing
3. Methodik und Vorgehensweise: Konzeption der Personenrecherche für die Crowd
3.1 Suchstrategien: Potenzielle User in Colle Santa Lucia und Brescia
3.2 Social Media
3.3 Institutionen
4. Realisierung des Pretests
4.1.Kriterien für den geeigneten Test
4.1.1 Sprachliche Gestaltung
4.1.2 Effizienz: Die Auswahl geeigneter Konzepte
4.1.3 Der Fragetypus
4.1.4 Unterhaltungswert: Medialer Einsatz zur attraktiven Gestaltung
4.2 Stand des Pretests: Funktionalität und Aufbau
4.2.1 Funktionalität und Aufbau der App
4.2.2 Das Abfragen eines weiteren Dialekts und Feedback
5. Ausblick auf die Analyse
5.1. Geplante Parameter zur Auswertung
5.1.1 Kongruenz schriftlicher und mündlicher Daten
5.1.2 Auswertung der soziodemographischen Fragen
5.1.2.1 Männersprache vs. Frauensprache
5.1.2.2 Durchschnittsalter der Nutzer und eventuelle Auswirkungen auf die Kompetenz
5.1.3 Auswertung des Feedbacks
5.2 Analyse am Beispiel von Colle Santa Lucia
6. Fazit
7. Bibliographie
1. Über das Projekt VerbaAlpina
VerbaAlpina ist ein Forschungsprojekt der Ludwig-Maximilians Universität, das den Sprach- und Kulturraum der Alpen auf ausgewählte Sachbereiche wie Natur, Kulturgeschichte und kulturelle Gegenwart untersucht. Innerhalb dieser Sachgebiete werden Kategorien wie beispielsweise Milchverarbeitung, Gebäude, Geräte, Produkte, Tätigkeiten und viele mehr konkretisiert. Das linguistisch betrachtet komplexe Untersuchungsgebiet deckt die Sprachen Italienisch, Französisch, Deutsch, Slowenisch und Rätoromanisch, sowie ihre jeweiligen Dialekte ab. Charakteristisches Sprach-und Kulturgut dieser Region wird systematisch erfasst und mit moderner Medientechnologie – Social Software, Internet, Datenbank und Georeferenzierung – analysiert und online aufbereitet, sowohl für Linguisten als auch für Laien. Im Zentrum der Untersuchung steht der spezifische Alpenwortschatz. Der Pretest wird sich aber insbesondere mit dem der Milch-und Käseverarbeitung befassen. Die Zielsetzung VerbaAlpinas ist das Erschaffen eines sprachübergreifenden Onlineportals, das der Dokumentation, Datenerhebung und Publikation dienen soll. Somit wird bereits bestehendes Material digital zugänglich gemacht und neue Daten hinzugefügt. Das Material für die Untersuchungen stammen aus unterschiedlichen Quellen, vorwiegend Sprachatlanten, Wörterbüchern und Parallelprojekten. Das besondere Augenmerk bei der Digitalisierung der Daten liegt auf der sogenannten Georeferenzierung, d.h. der geographischen Kennzeichnung der Herkunft. Allerdings sind die bisher existierenden Daten uneinheitlich, z.T. unübersichtlich und – durch den Erhebungszeitpunkt bedingt – mit veralteten Methoden aufbereitet, und müssen daher neu systematisiert und einheitlich digitalisiert werden, um sich einen guten ethnolinguistischen Überblick verschaffen zu können, was durch die eigens konzipierte Datenbank von VerbaAlpina gewährleistet wird.
Die bisherigen Quellen decken außerdem den Alpenwortschatz z.T. nur ungenügend ab, sodass neue Wege der Datenbeschaffung beschritten werden müssen. Einer dieser neuen Wege bietet der Umgang mit Crowdsourcing. Die Theorie sowie die praktische Anwendung eines Crowdsourcingsystems auf das Projekt im Rahmen eines Pretests für eine italienischsprachige 'Minicrowd' ist daher das zentrale Thema des vorliegendes Beitrags. Das Ziel des Pretests ist es, die angewandte Methodik auf Effizienz, mögliche Probleme und letztlich auf den Erfolg vorab zu testen, um somit Risiken des Crowdsourcings für VerbaAlpina zu minimieren und folglich die vielversprechenste Methode anwenden zu können. Vgl. Mutter 2016, Dialektologentreffen_Würzburg.
2. Das Konzept Crowdsourcing
2.1 Was ist Crowdsourcing?
Der aus englischen Wörtern crowd und outsourcing zusammengesetzte Neologismus crowdsourcing (dt. Schwarmauslagerung), bezeichnet eine heutzutage meist webbasierte Form der Arbeitsteilung, bei der Arbeits- und Kreativprozesse, Problemlösungen und Finanzierungsprojekte (crowdfounding) an eine undefinierte Masse von Internetnutzern ausgelagert werden. Dies funktioniert zumeist in Form eines Aufrufs auf einer Internetplattform, auf der die Nutzer freiwillig mitarbeiten können. Dabei ist ein besonderes Augenmerk auf den Mehrwert sowohl für die Institution, die ihre Crowd sucht, als auch für die Crowd selbst, zu legen.
Den Begriff Crowdsourcing beansprucht ein Journalist namens Jeff Howe im Jahr 2006 in einem Artikel für das US Magazin "Wired" geprägt zu haben. Seine These beinhaltet die konzeptionelle Unterscheidung des traditionellen Outsourcings, was bedeutet, dass Unternehmen Aufträge an Zulieferer vergibt, während das Crowdsourcing die Vergabe der Aufgaben an die Öffentlichkeit bezeichnet.
Da normalerweise für die Arbeit der Crowd keine Bezahlung ansteht, gilt es durch Bekanntheit, Anerkennung oder das Gefühl etwas Nützliches getan zu haben, die Masse zu belohnen. Ein passendes Beispiel dafür ist das die Onlineenzyklopädie Wikipedia: Hier wird die Crowd zum Autor bzw. Redakteur einzelner oder mehrerer Artikel, ohne eine Vergütung zu erhalten. Wikipedia ist jedem online zugänglich und somit können alle davon profitieren. Die "Belohnung" für die Crowd ist also hierbei das Teilen ihres Wissens, wodurch sie eine Art Expertenstatus erhalten, sowie die Publikation ihrer Artikel. Der Erfolg dieses Prinzips ist unverkennbar, da fast jeder Internetnutzer die Enzyklopädie kennt und zu Rate zieht. Vgl. Crowdsourcing
http://www.gruenderszene.de/lexikon/begriffe/crowdsourcing
Im Fall von VerbaAlpina handelt es sich um eine Form des Crowdsourcings, die sich collective knowledge nennt. Unter diesem Begriff versteht sich die Sammlung, Organisation und Filterung von Wissen. Es geht dabei weniger um die Kompetenzen des Einzelnen, sondern eher um die Intelligenz der Masse und den gegenseitigen Austausch, sodass Daten und Informationen immer besser und präziser werden. Vgl. Grimme Institut
2.2 Bereits angewendete Crowdsourcingsysteme
Als eines der erfolgreichsten Crowdsourcingprojekte darf Zooniverse an dieser Stelle nicht fehlen.
"The Zooniverse is the world’s largest and most popular platform for people-powered research. This research is made possible by volunteers—hundreds of thousands of people around the world who come together to assist professional researchers. Our goal is to enable research that would not be possible, or practical, otherwise. Zooniverse research results in new discoveries, datasets useful to the wider research community, and many publications."
Mit seiner Plattform, auf der verschiedene Projekte zu finden sind, hat es Zooniverse geschafft hunderttausende von Menschen zu motivieren, mobilisieren und zu sog. researcher zu machen. Ohne einen besonderen akademischen Hintergrund oder einem erwünschtem Profil sucht sich der User eines der vielen Projekte aus und kann durch das Beantworten einfacher Fragen den Forschern helfen und wird in verschiedensten Bereichen wie Tiere und Natur, Geschichten, Galaxien, Literatur u.v.m. selbst zum Forscher.
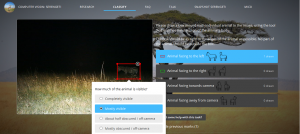
Abbildung 1 (vgl. https://www.zooniverse.org/about) Screenshot: 17.05.2016
2.3 Crowdsourcing und Linguistik
Bereits 1879 wurde von Crowdsourcing Gebrauch gemacht um die Linguistik voranzutreiben. Mit großen Erfolg kam die Technik des Crowdsourcings im Zuge der Produktion des Oxford English Dictionnary zum Einsatz. Der englische Philologe James Murray startete einen Aufruf an die gesamte anglophone Leserschaft mit der Bitte, ihm Belegstellen für alltägliche und ungewöhnliche Wörter zuzusenden. Der Erfolg ist unübersehbar, denn bis heute gilt das Oxford English Dictionnary als das Standardwörterbuch des Englischen.
Durch die neue Medientechnologie ist eine enorme Erweiterung dieser simplen Idee möglich geworden. Wie Wikipedia, Yahoo! oder Linux u.A. beweisen, ermöglicht die 'Weisheit von vielen' unabhängig vom geographischen Standort, eine schnelle globale Vernetzung von Akteuren, sog. User und zudem die Aktivierung großer Massen. Als modernere Beispiele der erfolgreichen Verbindung von Linguistik und Crowdsourcing sind die Dialäkt Äpp von Adrian Lehmann und das Dialekt-Quiz des Atlas zur deutschen Alltagssprache anzuführen.
Die Dialäkt Äpp wurde so konstruiert, dass die dem User zwei unterschiedliche Funktionen bietet. Zum einen kann die Crowd ihren schweizer Dialekt lokalisieren, indem die Aussprache von 16 Wörtern analysiert wird. Zum anderen kann der User Dialektwörter einsprechen und auch die Aufnahmen der anderen User hören und somit das dialektale Spektrum der deutschsprachigen Schweiz erforschen.
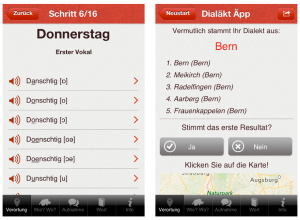
Abbildung 2
Das Quiz des Atlas zur deutschen Alltagssprache Moin, Grüezi, Servus: Sagen Sie uns wie Sie sprechen, und wir sagen Ihnen, woher Sie stammen ähnelt in seiner Funktionalität dem vorangegangen Beispiel. Nach dem Prinzip 'Wie sagst du zu..?' werden diverse Antwortmöglichkeiten, die morphologische Typen aus dem deutschsprachigen Raum aus Deutschland, Österreich und der Schweiz abbilden, angeboten. Am Ende des Quiz werden einige potenzielle Herkunftsgebiete des Users – nach Analyse seiner Antworten – angegeben, die, wie Erfahrungswerte zeigten, oft zutreffend waren.
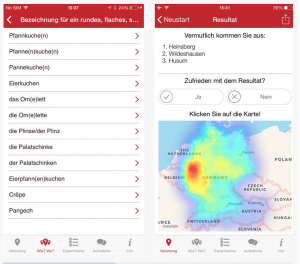
Abbildung 3
Allerdings ist hier keine Lokalisierung bzw. Georefernzierung auf Dorfebene möglich, was jedoch als Untersuchungskriterium sehr interessant wäre, da sich trotz geographischer Nähe die Dialekte aus Nachbardörfern sehr unterscheiden können.
Dies nutzt VerbaAlpina durch die Verwendung einer Strategie, die erlaubt, die Dialektverortung zumindest bis auf Gemeindeebene zurück zuverfolgen. Im Crowdsourcing von VerbaAlpina geht es vor Allem darum, das kognitive Wissen der User zu nutzen, von dem sie oft nicht wissen, dass sie es haben. Somit können Lücken der Sprachatlanten, wie z.B. im AIS oder im ALI gefüllt werden, da diese nur selten den sehr spezifischen Alpenwortschatz erfasst haben. Durch die Vorgehensweise des geplanten Crowdsourcings können wir also vom unschätzbaren „Laien-Wissen“ profitieren.
Auf der folgenden Bildschirmaufnahme der interaktiven Karte der Website von VerbaAlpina ist graphisch eine "Datenlücke", die sich wegen mangelnder bzw. für VerbaAlpina nicht zungänglicher Datenbestände in Österreich abzeichnet, abgebildet und demonstriert daher die Notwendigkeit des Crowdsourcings.
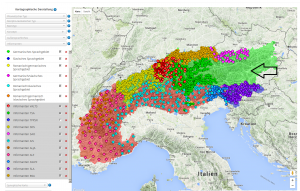
Abbildung 4
2.4 Grenzen und Möglichkeiten im Umgang mit Crowdsourcing
Die prinzipiellen Herausforderungen, die sich beim Gebrauch von Crowdsourcing stellen, sind die folgenden: Das Rekrutieren motivierter User und deren Beibehaltung, das sinnvolle Vereinen ihrer Beiträge, das Verteilen von Aufgaben, das Sicherstellen ihrer Kompetenzen, der Balanceakt zwischen Transparenz und Qualität sowie das Verhindern von Missbrauch (vgl. Review articles) Vgl. Review Artciles
Dies erfordert eine genaue Strukturierung der Arbeitsaufträge, was sich allein schon in der Formulierung widerspiegelt. Abschreckend wissenschaftliche oder zu abstrakte Formulierungen sind daher dringlich zu vermeiden, aber auch zu spielerisch darf es nicht konzipiert sein, da ansonsten die Seriösität und somit das Ziel der Datenbeschaffung verloren geht. Die Ausgewogenheit zwischen Ernsthaftigkeit und Unterhaltungswert gilt es also auch zu berücksichtigen. Allgemein lässt sich sagen, dass die Schwächen des Crowdsurcing "viele Beliebigkeiten, Laienhaftigkeit und mangelnde Verlässlichkeit" (http://www.verba-alpina.gwi.uni-muenchen.de/?page_id=493&letter=C#crowdsourcing) sind.
Die Stärken des Crowdsourcings sind ohne Frage Kreativität, Kollektivität und das Teilen der "Schwarmintelligenz". In Verbindung mit dem Web 2.0 sind schnell enorme Massen mobilisiert, die Basis für einen regen Wissensaustausch geschaffen und im positiven Fall folgt die Entstehung eines Schneeballsystem, welches ständige Informationen und eine wachsende Crowd garantieren kann. Je mehr User aktiviert werden, desto größer wird die Plattform und somit der Informationsfluss. Die Semantik des Begriffs User ist an dieser Stelle genau zu differenzieren: der User soll im Crowdsourcing ein Informant, ein Nutzer der Daten und auch ein Autor sein. Dies lässt sich gut an folgenden Graphiken veranschaulichen, die widerspiegeln, wie sich das Kommunikationsverhältnis zwischen Informanten und Autor durch das Nutzen des Crowdsourcing und somit im Sinne der Digital Humanities verändert.
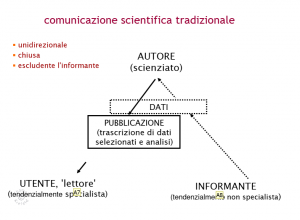
Abbildung 5
Wie auf Abbildung 5 zu sehen, entsteht durch das bisherige Kommunikationsmodell zwischen Informant, Autor und Nutzer ein unidirektionaler Informationsfluss: vom Informanten zum Autor und vom Autor werden die verarbeiteten Daten für den User zugänglich gemacht.
Auf der folgenden Abbildung 6 werden nun die Veränderungen durch den Umgang mit Crowdsourcing deutlich erkennbar: ab jetzt kann ein reger Informationsaustausch in alle Richtungen erfolgen. Angewandt auf VerbaAlpina würde dieses neue Kommunikationsmodell Folgendes ergeben: der Informant vermittelt VerbaAlpina dialektale Daten, mittels Crowdsourcing landen diese direkt in der VerbaAlpina Datenbank, werden aufbereitet, d.h. transkribiert und typisiert und danach für die User zugänglich gemacht. Ein ebenso nützliches und wünschenswertes Szenario wäre, dass der linguistisch motivierte oder bewanderte User seine Daten gleich selbst transkribieren kann. Um auf den Begriff des Users zurückzukommen, ist hier nun zu sehen wie der Nutzer alle kommunikativen Funktionen übernehmen kann und soll. Der "Idealnutzer" VerbaAlpinas ist ein Dialektsprecher, also ein Informant, der aber auch die Daten, die von VerbaAlpina kommen, kommentieren oder verändern kann, also ein Autor, und das Datenmaterial auch zu eigenen Zwecken verwenden kann, folglich ein Nutzer. In jedem Fall ist der Austausch zwischen Autoren, Usern und Informanten aller Art durch die "Öffnung" der VerbaAlpinaplattform möglich und erwünscht.
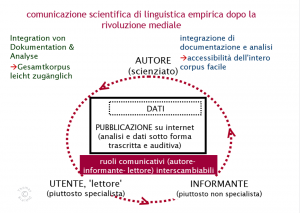
Abbildung 6
Einmal auf der VerbaAlpinaplattform angekommen, geht es anschließend um die Arbeitsteilung. Bei der Vermittlung der Arbeitsaufträge und bei der darauffolgenden Filterung der Informationen zeichnen sich jedoch gewisse Herausforderungen ab.
Es muss die Frage gestellt werden, nach welchen Kriterien gefiltert wird. Das bedeutet, dass der Auftrag der Crowd so unmissverständlich wie möglich gestellt werden muss, sodass keine Missverständnisse o.Ä. auftreten können. Zudem sollte aber auch Raum für zusätzliche Informationen bedacht werden, damit der User soviel von seinem Wissen teilen kann wie er möchte, denn auch davon kann man ungeahnt profitieren. Zudem müssen bereits bei der Personenrecherche für die Crowd Einschränkungen gemacht werden; es muss zunächst ein Kriterienkatalog erstellt werden, nach dem passende User rekrutiert werden. Weiterhin darf die Genauigkeit nicht verloren gehen; im Falle des Collecitve Knowledge sollte nicht außer Acht gelassen werden, dass die Informationen so konkret wie möglich abgefragt werden müssen, damit die Ergebnisse verwertbar bleiben.
Die bereits aufgeführten Kriterien und alle weiteren, die in der Realisierung des Pretests Anwendung fanden, werden im folgenden Teil der Arbeit zur Methodik und Vorgehensweise sowie zur Realisierung zusammengetragen.
3. Methodik und Vorgehensweise
3.1 Konzeption der Personenrecherche für die Crowd
Bei der Personenrecherche für eine geeignete Crowd des Projekts bzw. für den Pretest müssen zwei grundsätzliche Punkte berücksichtigt werden. Zunächst stellt die Erreichbarkeit der Personen, die interessant für VerbaAlpina sind, ein gewisses Problem da. Ein echter Experte bzgl. Milch- und Käseproduktion und daher für den Alpenwortschatz im Allgemeinen z.B. ein Senn, ist tendenziell ein älterer Mensch, der im VerbaAlpinagebiet lebt. Das heißt, es könnte schwierig werden, jene Experten zum einen altersbedingt mit Social Media, App oder Website zu erreichen. Zum anderen könnte die zweite Schwierigkeit geographischer Natur sein, da der Internetanschluss im Gebirge und somit die Zugänglichkeit nicht abzusehen ist. Auch bei schlechtem Empfang o.Ä. könnten Komplikationen für das Nutzen der App/Website auftreten.
Von diesen grundsätzlichen Einschränkungen abgesehen, mussten für die Funktionalität des Pretests gewisse Suchstrategien entwickelt werden, um Probanden zu finden.
3.1.1 Suchstrategien: Potenzielle User in Colle Santa Lucia und Brescia
Glücklicherweise hat VerbaAlpina durch zwei Kontaktpersonen die Möglichkeit auf verschiedene 'Minicrowds' zurückzugreifen. Zum einen steht eine Minicrowd aus Colle Santa Lucia, gelegen mitten im VerbaAlpina-Gebiet (gelbe Markierung s. Abb. 7), zur Verfügung, das verschiedene interessante Parameter zur Untersuchung bietet.

Abbildung 7
Es handelt sich dabei um eine Gruppe von 15-20 Personen. Da unter diesen Personen zumindest schon zwei Generationen vertreten sind, kann man heterogene Antworten erwarten, sowohl bei den dialektalen Fragen als auch im Kompetenztest. Weiterhin lässt sich bei dieser Anzahl von Probanden auch eine 'dorfspezifische' Untersuchung durchführen, wobei es hier besonders interessant wäre, im Falle heterogener Antworten, das Alter, Geschlecht und die Kompetenz zu vergleichen und somit unterschiedliche Antworten zu erklären.
Bei der Minicrowd aus Brescia ist noch nicht abzusehen, welche Art von Usern und wie viele teilnehmen werden. Der Anprechpartner aus Brescia hat sich bereit erklärt, über seinen Newsletter alle Mitglieder der Gruppe gruppo dei ricercatori ed appassionati di cultura alpina della Valle Camonica an der Teilnahme am Pretest einzuladen.
3.1.2 Social Media
Über gängige Social Media Plattformen zu suchen, bietet sich im Umgang mit Crowdsourcing sehr gut an. Zur Auswahl stehen verschiedene Möglichkeiten, die im Rahmen des Pretests getestet werden und – falls sich diese als erfolgreich herausstellen – im großen Stil für das Crowdsourcing für VA angewendet werden sollen. Als eine der ersten Plattformen kann man Facebook nutzen. Die Suchstrategie, die ich hier anwenden möchte, sieht vor, verschiedene Facebookgruppen, die potenzielle User für den Pretest darstellen, zu suchen und durch einen direkten Aufruf anzuschreiben. Zunächst wurde also stichprobenartig direkt nach Gruppierungen der Gemeinden aus dem VerbaAlpina Gebiet gesucht. Die Basis dafür ergibt sich aus der VerbaAlpina-Datenbank, in der alle Gemeinden, die im Erhebungsgebiet liegen, aufgelistet sind. Durch eine simple Abfrage mit MySQL
SELECT * FROM `gemeinden_ak` WHERE Sprachfamilie REGEXP 'rom'
lassen sich die Gemeinden nach Sprachfamilie sortieren, die in diesem Fall ''romanisch" wäre:
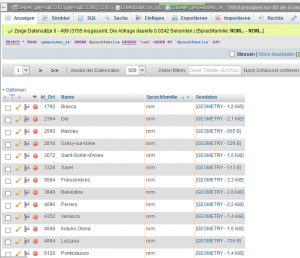
Abbildung 7
Da man sich durch die Georeferenzierung nun alle Orte anzeigen lassen kann, die im italofonen Gebiet liegen, kann eine systematische Suche nach Gruppierungen, Vereinen o.Ä. dieser Gemeinde im Internet erstellt werden.
Eine andere Herangehensweise stellt die Suche nach allgemeineren Gruppen dar, von denen ich mir erhoffe, Menschen zu finden, die aus dem Erhebungsgebiet stammen. Passende Gruppen können z.B. italiani a monaco, Italiener in München etc. sein. Der Aufruf soll in direkter Form die jeweiligen Gruppen geposted werden. Dieser Aufruf sieht wie folgt aus.
Ciao a tutti,
sono una studentessa italo-tedesca di Monaco e per la mia tesi ho costruito un'applicazione per analizzare i dialetti italiani alpini, cioè si tratta di un lavoro sui dialetti italiani nelle regione italofone nelle Alpi. I temi trattati saranno anche tipici per le Alpi: Lavorazione del Latte, Alpeggio etc..
Come funziona?
18 domande, tipo: come dici 'il latte'? Ci sono anche delle fotografie, video etc., dunque ci si può divertire anche un po' 😉
Non durerà più che ca. 15 minuti. Quindi, se sei di una regione alpina italofona, se hai voglia di aiutarmi e di far parte della scienza linguistica, clicca direttamente qui! 🙂
Tutto si svolgerà in modo anonimo!
Il test e la tesi fanno parte del progetto linguistico VerbaAlpina, guidato da Prof. Dr. Thomas Krefeld e Dr. Stefan Lücke, Ludwig-Maximilians-Universität München. Per ulteriori informazioni clicca su http://www.verba-alpina.gwi.uni-muenchen.de !
Grazie in anticipo per il vostro aiuto ed a presto!
Giorgia
Dieser Text soll auch auf weiteren öffentlichen Netzwerken wie Twitter veröffentlicht werden.
Das Ziel über die Suche durch Social Media sollte sein, dass so viele Menschen wie möglich erreicht werden, z.B. – im Idealfall- durch selbstständiges Teilen.
3.1.3 Institutionen
Eine andere Möglichkeit stellt das Suchen der User über Institutionen dar, die entweder eine italienischsprachige Zielgruppe haben, im Alpenraum tätig sind oder Interesse am Alpenraum haben. Dazu gehören das italienische Kulturinstitut in München, das italienische Konsulat, evtl. der bayerische Alpenverein, Ass.Alpini di Monaco oder auch Onlineportals wie www.comuni-italani.it.
Der Vorteil des Kontakts mit öffentlichen Institutionen besteht darin, dass sie oft eine große community haben und über Newsletter der Institutionen erreicht werden können. Außerdem kann man davon ausgehen, dass Einrichtungen wie Kulturinstitute selbst ein Interesse an Projekten wie VerbaAlpina haben, da hier Sprach-und Kulturgut Italiens im Vordergrund steht.
Des Weiteren habe ich durch die Recherche mit der Suchmaschine Google nach Molkereien, Almen (mit touristischem Hintergrund und auch Milch-und Käseproduktion) sowie Schaukäsereien im italienischsprachigen Erhebungsgebiet gesucht und alle Kontaktmöglichkeiten genutzt; d.h. Emailadressen kontaktiert sowie auf jeweiligen Facebookseiten den eben gezeigten Aufruf gepostet.
Abbildung 8
Es folgt nun eine Auflistung aller kontaktieren Institutionen:
Kulturinstitute:
-
Istituto di cultura italiana di Monaco di Baviera
-
Istituto Ladino
Molkereien:
-
Caseificio dal Casarao
-
Latteria Livigno
- Caseificio Sociale di Vallecamonica
Almen:
- Kreuzwiesenalm
- Samerhof (Meransen)
- Fallhof
Unternehmen:
- La Macelleria Rigamonti (Produktion von Käse- und Salamispezialitäten)
- Gutes aus Südtirol (Versand von Südtiroler Spezialitäten)
Die Resonanz und den Erfolg dieser Suchstrategien bleibt noch abzuwarten. Mit persönlichen Antworten ist kaum zu rechnen, allerdings wird sich in der Datenmenge und auch in der IP-Adresse der Nutzer zeigen, wie erfolgreiche diese Methoden waren und welche Gruppen erreicht wurden.
4. Realisierung des Pretests
Wie schon erwähnt, soll das eigentliche zukünftige Crowdsourcingprojekt von VerbaAlpina die sogenannten Datenlücken füllen bzw. neuen/modernen alpinen Wortschatz zu Tage fördern und online zugänglich machen, um die Endprodukte des Projekts, die auf der VerbaAlpinaplattform sichtbar sein sollen, nämlich einerseits die Verbreitung von Bezeichnungen und andererseits die Verbreitung von Bedeutungen, zu ermöglichen. In diesem Pretest sollen also vorab die Eventualitäten, Probleme etc. abgeklärt werden, um eben genannte Ziele zu erreichen. Ein Problem, das sich beispielsweise sofort stellt, ist der Fragetypus im Test. Die Fragestellung 'come dici..?' kann variiert werden: mit Konzeptbeschreibung und Bild, nur Bild, Konzeptbeschreibung und Videomaterial etc.. Ebenso schwierig verhielt es sich zunächst mit den Antwortmöglichkeiten, nämlich Schrift sowie Aufnahme, und letztlich bleibt noch das Feedback der User abzuwarten. Außerdem wurden sogenannte Kompetenzfragen eingebaut, die sowohl die Kompetenz als auch die Aufmerksamkeit des Users testen und daher einer anderen Fragestruktur unterliegen. Das konkrete Ziel dieser Arbeit ist es, die effizienteste Methode des Crowdsourcings für die Gewinnung linguistischer Daten zu ermitteln. Dafür erlag die Erstellung des Tests einem wohlüberlegten Kriterienkatalog, der folgend erklärt wird.
4.1 Kriterien für den geeigneten Test
Für den größtmöglichen Nutzen des Pretests gilt es grundlegende Kriterien als Basis für alle folgenden zu berücksichtigen: selbsterklärend formuliert, effizient durch richtige Fragstellung, was die Auswahl geeigneter Konzepte beinhaltet, passende Antwortmöglichkeiten sowie eine ansprechende Gestaltung für den User.
4.1.1 Sprachliche Gestaltung
Für das erste Kriterium spielen mehrere Faktoren eine Rolle, die daher ausdifferenziert werden müssen. Für eine selbsterklärende Formulierung, die einfach und daher weder abstrakt noch wissenschaftlich sein darf, muss zusätzlich noch der Platzmangel auf einem Smartphonebildschirm einkalkuliert werden. Das heisst, mit so wenig Worten wie möglich, muss eine kurze Einführung zur Nutzung und ein klarer Arbeitsauftrag hervorgehen. Daher wurde für den Test viel mit selbsterklärenden Symbolen und Ikonen, mit den jeweiligen Funktionen für die Symbole/Ikonen und Bildern gearbeitet. An einem konkreten Beispiel demonstriert bedeutet das, dass der Start der App/mobilen Website mit dem Klick auf das Startbild zu betätigen ist. Danach folgt eine kurze Einführung zur Nutzung des Tests. Dies bleibt der einzige Fließtext im ganzen Test. Die genaue aber nicht übertriebene Formulierung ist an dieser Stelle sehr wichtig, um sicherzustellen, dass der Arbeitsauftrag verstanden wurde und ausgeführt wird.

Abbildung 9
Zur Veranschaulichung des Auftrags folgt eine Beispielfolie, auf der einfach erklärt wird, wie der Auftrag auszuführen ist, in dem die verwendeten Symbole erklärt werden.

Abbildung 10
Wie eben erwähnt, sind die Symbole auf diesen Abbildungen gut zu erkennen und im Beispiel noch mit Text hinterlegt, der in den folgenden Folien nicht mehr zu sehen sein wird. Ist das Symbol einmal erklärt, kann so der Text im restlichen Test maximal gekürzt werden. Weiterhin wurde entschieden, den User persönlich anzusprechen (2.Pers.Sg.) und somit ein weniger wissenschaftliches, entspanntes und persönlicheres Umfeld zu schaffen. Die Formulierungsmethode, die hier demonstriert wurde, zieht sich nach dem gleichen Schema durch den ganzen Test. Die Syntax ist selbst in der Fragstellung auf das nötigste reduziert und es tauchen weder Fachtermini noch Fremdwörter auf, da diese – wenn sie nicht verstanden werden- zu großem Unbehagen des Users führen könnten und somit schlimmstenfalls zum Abbruch des Tests. Das Ziel ist es, mit der treffenden Formulierung dem User zu vermitteln, dass er und sein Wissen – das ohnehin nur eine gewisse Anzahl von Menschen hat – von unserer Seite extrem gebraucht werden und nur der User VerbaAlpina helfen kann.
4.1.2 Effizienz: Die Auswahl geeigneter Konzepte
Nachdem die passende Formulierung gefunden wurde, muss die Effizienz des Tests gewährleistet werden, was durch das Abfragen der richtigen Konzepte sowie durch das Anbieten der passenden Antwortmöglichkeiten bzw. durch den Fragetypus geschehen soll.
Nach welchen Kriterien die ausgewählten Konzepte ihren Platz im Pretest gefunden haben und worin die Notwendigkeit besteht genau diese Konzepte abzufragen soll im folgenden Abschnitt erläutert werden. Grundlegend für das Verständnis ist jedoch die Kenntnis der Konzeptstruktur, das heißt von der Anlegung bis hin zur Hierarchie in der Datenbank von VerbaAlpina. Zur Veranschaulichung dient daher Abbildung 10.
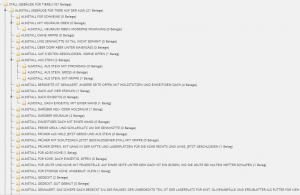
Abbildung 10
Zu sehen ist der sogenannte Konzeptbaum, der die hierarchische Struktur der Konzepte VerbaAlpinas abbildet. Des Weiteren ist somit sofort ersichtlich, wie spezifisch diverse Konzepte sind und sich daher sogenannte Unterkonzepte zu den jeweiligen Konzepten formieren. Bei der Betrachtung gewisser Konzepte, wie beispielsweise 'ALMSTALL, FRÜHER OFFEN, MIT GANG IN DER MITTE UND LAGERPLÄTZEN FÜR KÜHE RECHTS UND LINKS, JETZT GESCHLOSSEN' (vgl. Abb. 10 Mitte) wird klar, dass eine wohlüberlegte Auswahl der abzufragenden Konzepte vorgenommen werden muss, da sich dieses beispielhafte Konzept (als eines von vielen) definitiv nicht abfragen lässt – und das aus verschiedenen Gründen: Zum einen kann aus pragmatischer Sicht ein Konzept dieser Länge nicht abgefragt werden, da auf der mobilen Version, die auf Smartphones oder Tablets genutzt werden soll, der Platz sehr eng bemessen ist. Weiterhin sind jene spezifischen Konzepte, nicht an allen Orten vorhanden, da sie z.T. nur an exakt einem Ort vorkommen und daher gemeindespezifisch sind. Es gilt also, jegliche Unterkonzepte auszusparen und sich am allgemeinsten Konzept zu orientieren, um flächenabdeckend abfragen zu können . Dies hieße für das vorangegangene Beispiel, dass das hierarchisch ganz oben angesiedelte Konzept aus dem Konzeptbaum auszuwählen ist, in diesem Fall wäre das 'ALMSTALL'.
Ein "Experiment" mit einem dieser sogenannten Unterkonzepte findet allerdings doch Anwendung am Ende des Test: Abgefragt wurde das Unterkonzept 'ALMSTALL, OFFEN, AUF 4 PFÄHLEN GESTÜTZT'. Es wird sich also in der Analyse des Pretests zeigen, wie viele Daten und welche bei dieser Frage erhoben werden können. Zu berücksichtigen ist dabei, dass nicht geprüft werden kann, ob dieses Konzept in allen Gemeinden existiert und ob ein dialektaler Beleg, der sich vom Hauptkonzept 'ALMSTALL' abhebt, gebräuchlich ist oder nicht. Ausgangspunkt für dieses Experiment ist die Karte des AIS zum Stimulus 'Almstall'. Auf dieser Karte zeigte sich eine enorme Menge an sehr spezifischen Unterkonzepten bzgl. Almställen in verschiedensten Varianten. Daher ist es interessant zu überprüfen, ob sich eine solche Datenmenge an spezifischen Unterkonzepten auch mittels Crowdsourcing erheben lässt, ob diese Belege aus Erhebungszeiten des AIS noch aktuell sind und wenn dies der Fall ist, welche Art von Informanten diesen Wortschatz noch kennt.
4.1.3 Der Fragetypus
Wie schon angedeutet gibt es semantisch zwei unterschiedlich konzipierte Fragetypen. Einerseits, und mehrheitlich wurde dieser Fragetyp genutzt, gibt es sprachlich orientierte Fragen, die nur darauf abzielen, die dialektale Bezeichnung für ein Konzept zu erfragen. Diese kann eingetippt und eingesprochen werden.

Abbildung 11
Andererseits wurden die sogenannten Kompetenzfragen eingebaut, die bei der Analyse feststellen sollen, wie kompetent der User, der diesen Test durchlaufen hat, wirklich ist und wie aufmerksam er war. Für diese Fragen werden zwei bis drei Antworten zum anklicken angeboten. In diesem Fall gibt es entweder eine richtige oder eine falsche Antwort bzw. könnten Abstufungen in der Kompetenz festgestellt werden. Anhand der folgenden Bildschirmaufnahme des Pretests kann dies veranschaulicht werden.

Abbildung 12
Auf dem Bild ist das Konzept – bei diesem Fragetypus natürlich ohne Konzeptbeschreibung – des Prozesses 'HERAUSHEBEN DES KÄSES AUS DEM KÄSEKESSEL MIT KÄSETUCH' zu sehen, was der Antwortmöglichkeit 1 entspricht. Markiert der User also Antwortmöglichkeit 2 ist er weniger kompetent, als die User, die die richtige Antwort markiert haben. Somit hat man während der Analyse Vergleichsmaterial: zu untersuchen wäre z.B. inwiefern sich die Antworten der User – am besten aus dem gleichen Dorf bzw. aus der gleichen Gemeinde – die den Kompetenztest 'bestanden' haben zu denen unterscheiden, die die Kompetenzfragen nicht korrekt beantwortet haben. Zusätzlich sollen durch die Fragen, die auf die Aufmerksamkeit abzielen, also die z.B. durch genaues Hinsehen richtig zu beantworten werden können, weitere Abstufungen sichtbar sein bzw. weitere Vergleiche möglich machen. Durch das analysieren der Antworten können nun also dialektale Kompetenz, Aufmerksamkeit und Sachkompetenz bzgl. Almwesen getestet werden. Somit wird also sprachlicher und außersprachlicher Input. Spielt man dieses Szenario durch, könnte sich folgendes ereignen: zwei User aus der gleichen Gemeinde geben verschiedene Antworten bei den sprachlichen Fragen. Im zweiten Teil des Tests wird Kompetenz und Aufmerksamkeit abgefragt. Durch ein unterschiedliches 'Kompetenzniveau' könnten z.B. unterschiedliche Antworten erklärt werden. Weiterhin ist es VerbaAlpina so möglich, festzustellen welche Art von User am besten erreicht wurde. Und letztlich kann VerbaAlpina, bei Einverständnis des Users, mit allen Probanden, aber vor allem mit den Experten, in Kontakt bleiben. Daher scheint mir die eben skizzierte Konzeption des Pretests als die effizienteste für diesen Rahmen.
Letztlich gilt es dies noch in einen ansprechenden Kontext für den Probanden und Nichtlinguisten einzugliedern. Daher muss der Punkt des Unterhaltungswerts durchdacht werden.
4.1.3 Unterhaltungswert und ansprechende Gestaltung: Medialer Einsatz
Diesen Bereich gilt es – wie bereits angedeutet – mit Vorsicht zu bearbeiten. Durch die Formulierung (so wenig Text wie möglich und der Einsatz verschiedener Medien) hat der Test bereits eine nutzerfreundliche Position eingenommen. Ferner darf aber eine ansprechende Gestaltung und ein gewisses Quantum an Unterhaltung meiner Ansicht nach nicht fehlen, da der User sich sonst langweilen könnte und im schlimmsten Fall den Test abbricht oder ihn gar nicht erst startet. Es ist daher notwendig dem User etwas für seine aktive und ordentliche Teilnahme – also für seinen Beitrag zur Wissenschaft – zu bieten, um ihn zunächst zur Teilnahme zu motivieren, daraufhin für das Crowdsourcing von VerbaAlpina zu gewinnen und ein Schneeballsystem (z.B. über Mundpropaganda) in Gang zu bringen, um laufenden Zuwachs und stetigen Informationsfluss zu bewirken. Da es sich aber bei dem Pretest für VerbaAlpina weder um ein Spiel noch um ein Quiz handelt, liegt die Schwierigkeit im Balanceakt zwischen Seriösität und Entertainment.
Um dieses gewisses Quantum an Unterhaltung für den User zu erzeugen, stehen verschiedene Mittel für eine ansprechende Gestaltung zur Verfügung.
Sowohl aus wissenschaftlicher als auch aus pragmatischer Sicht sind unterstützende Fotos und Videos zu den Fragestellungen, die auf die dialektale Kompetenz abzielen, nicht notwendig, im Gegenteil: das Einfügen von Medien verringert den schon begrenzten Platz, der auf einer Seite zur Verfügung steht. Da bei besagten Dialektfragen immer eine Konzeptbeschreibung zur Verfügung steht, handelt es sich beim medialen Einsatz für die sprachlichen Fragen um ein reines Mittel zur Erstellung eines attraktiven Designs. Andererseits kann somit sichergestellt werden, dass das Konzept richtig verstanden wurde.

Abbildung 13
Bei der Verwendung von Videomaterial handelt es sich auch um unterstützenden medialen Einsatz, allerdings haben die eingefügten Videos auch einen konzeptionellen Hintergrund, der im Punkt 4.2.1 erklärt wird. Generell auf den medialen Einsatz bezogen, lässt sich sagen, dass bewegte Bilder im Vergleich zu Standbildern, meist anschaulicher sind und zudem ein zusätzliches Medium darstellen; der Wechsel zwischen Fotos und Videos stellt also meiner Meinung nach, einen größeren Unterhaltungswert da, als die homogene und konsequente Verwendung desselben Mediums.

Abbildung 13
Video 1
Die "Belohnung" des Informanten für die Teilnahme am Crowdsourcing könnte diverse Gestalten annhemen. Denkbar wäre die Vergabe eines Expertenstatus, der die Nutzung verschiedener Tools auf der VerbaAlpinalattform für den Informanten möglich macht, z.B. die Nutzung des Trasnkriptionstools. Dies wird allerdings erst in der Crowdsourcingsphase VerbaAlpinas statfinden, nachdem der Pretest ausgewertet wurde.
4.2 Stand des Pretests: Funktionalität und Aufbau
4.2.1 Funktionalität und Aufbau der App/mobilen Website
Die mobile Website ist seit dem 30.05.2016 online zugänglich und wurde an alle bereits genannten Kontake und Institutionen verschickt. Die Funktionalität ist momentan auf schriftliche Eingabe der Belege beschränkt, da die Eingabe von Sound bisher von mobilen Browsern kaum unterstützt wird. Allerdings wird bereits daran gearbeitet und diese Funktion sollte im Crowdsourcing von VerbaAlpina angeboten werden können.
Es folgt nun die Beschreibung und Erläuterung der Struktur und des Aufbaus der App/mobilen Website. Dies lässt sich am anschaulichsten durch die Verwendung durch Screenshots und den jeweiligen Erklärungen dazu, demonstrieren.
Bei den bisher gezeigten Screenshots handelte es sich um die 'Rohversion' der mobilen Website, während das nun gezeigte Bild den Screenshot der Website, die nun online ist, zeigt. Bevor der Test startet, wird allerdings die Nutzungserklärung angezeigt, die unbedingt akzeptiert werden muss und besagt, dass die Daten, die aus der App/mobilen Website hervorgehen, gespeichert, verarbeitet und publiziert werden dürfen. Weiterhin muss der zukünftige User ausdrücklich in die Speicherung der personenbezogenen Daten sowie des Standorts zum Zeitpunkt der Dateneingabe und des Zeitpunkts der Dateneingabe einwilligen. Nachdem die Nutzungserklärung akzeptiert wurde, öffnet sich die Startseite.

Abbildung 14
Bei Klick auf die Seite startet der Test indem die Erklärung des Arbeitsauftrages folgt.

Abbildung 15
Der Nutzer kann sich nun entscheiden, ob er sich ein Beispiel anzeigen lässt oder gleich mit der ersten Frage starten möchte. Das Beispiel zeigt das Konzept mit Bild Butter. Um zu veranschaulichen, wie der Auftrag auszuführen ist, wird der Beleg, den ich bespielhaft aus dem Ort Olivone ausgewählt habe – ul buter - graphisch automatisch eingetippt. Das Beispiel kann so oft wie gewünscht wiederholt werden. Klickt man auf dem Pfeil nach rechts, startet die erste Frage, die sich an den User richtet.

Abbildung 16
Die ersten 10 Fragen sind genau nach diesen Typus aufgebaut und fragen nur die dialektale Kompetenz ab. Nach der zehnten Frage folgt eine Art semantischer Umbruch, wobei dem User freisteht weiter zu machen oder abzubrechen. Zudem werden auf dieser Seite die soziodemographischen Daten abgefragt.
Abbildung 17
Entscheidet sich der User dafür, weiterzumachen, folgen 8 weitere Fragen, die sowohl aus Dialektfragen, Kompetenzfragen und Fragen, die auf die Aufmerksamkeit abzielen, bestehen.
Beispielsweise stellt die Frage 12 eine Frage dar, die auf die Aufmerksamkeit abzielt. Gezeigt wird das Bild einer Stute, ohne Konzeptbeschreibung. Vermutlich wird der Großteil der Nutzer ihren dialektalen Beleg für das Konzept 'Pferd' eingeben. Findet sich jedoch – trotz gegenteiliger Erwartung – jemand, der den Beleg für 'Stute' eingibt, kann man daraus schliessen, dass es sich um einen sehr aufmerksamen Informanten handelt.
4.2.2 Umgang mit Audio und/oder Video und/oder Bildmaterial
Von der Konzeptbeschreibung abgesehen, wird dem User durch das demonstrieren einer Tätigkeit automatisch klar, dass es sich bei dem gesuchten Wort um ein Verb handeln muss.
Zudem muss bedacht werden, dass der Arbeitsauftrag unklar werden könnte, wenn man Tätigkeiten/Prozesse mit Fotos abbildet (dies könnte bedeuten, dass der User durch die uneindeutige Formulierung des Arbeitsauftrags nicht das gesuchte Verb angibt und somit der Beleg unbrauchbar bzw. nicht mehr vergleichbar wird). Um also Homogenität zu sichern – und somit vergleichbare Antworten – wird durch die verbale Konzeptbeschreibung und dem zusätzlichen Video, die besagte Tätigkeit bzw. der Prozess abgebildet.
Beispiel: Abbildung 17
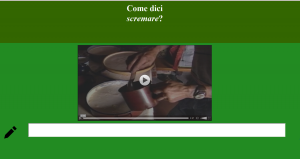
4.2.3 Das Abfragen eines weiteren Dialekts und Feedback
Da VerbaAlpina vom gesamten Wissen des Nutzers profitieren möchte, gibt es nach dem erstmaligen Durchlaufen, die Möglichkeit den Test mit Belegen eines weiteren Dialekts beliebig oft zu wiederholen. Die Idee dahinter ist die folgende: Auch wenn der Nutzer ursprünglich aus einer Gemeinde kommt, kann es trotzdem sein, dass er über Kenntnisse der Nachbargemeinde oder eines anderen Ortes im Erhebungsgebiet verfügt (z.B. durch Arbeits-oder Kindheitsaufenthalte, Kontakte etc.).
Abbildung 18
Klickt man also auf "Sì" startet der Test von neuem.
Abbildung 19

5. Ausblick: Analyse des Pretest
Zur Auswertung aller Daten, die durch die mobile Website erhoben wurden und noch erhoben werden, kommt es im Rahmen der Bachelorarbeit nicht mehr. Die geplanten Parameter die zur Untersuchung der Daten nach einigen Wochen Laufzeit dienen sollen, stehen allerdings schon fest. Vorausgesetzt ist aber die Notwendigkeit der Analyse nach diesen Kriterien. Das bedeutet, zeigt sich diese nicht bei der ersten Betrachtung der Daten, werden jene Kriterien nicht zur Analyse angewandt und durch andere, sinnvollere ersetzt. Daher ist bei der folgenden Auflistung der Parameter immer zu beachten, dass diese auf meinen Erwartungen für mögliche Ergebnisse beruhen.
5.1 Geplante Parameter zur Auswertung
5.1.1 Kongruenz schriftlichter und mündlicher Daten
Der Pretest wird zwei unterschiedliche Funktionen bieten, nämlich die Möglichkeit den Beleg zu schreiben als auch einzusprechen. Allerdings wird diese Soundfunktion von den mobilen Browsern noch kaum unterstützt, weswegen diese Funktion zwar möglich sei wird, allerdings erst zu einem späteren Zeitpunkt, da sich diese Umsetzung schwieriger darstellt, als zu nächst abzusehen war. Sobald diese Funktion realisiert wird, könnte man folglich die Kongruenz bzw. Inkongruenz der schriftlichen und mündlichen Daten untersuchen. Genauer gesagt, könnte man die perzeptive Wahrnehmung der Sprechers untersuchen, d.h. wie der Sprecher seinen Beleg verschriftlicht. Da im besten Fall die Belege in schriftlicher und mündlicher Form vorliegen werden, ließe sich anhand dessen die gewählte Orthographie analysieren und diese mit der der anderen Usern der gleichen Gemeinde vergleichen.
Des Weiteren könnte festgestellt werden, wie die Nutzer der App/mobilen Website die unterschiedlichen Funktionen annehmen. Es wäre denkbar, dass sich Präferenzen herausbilden, welche der beiden Möglichkeit – Verschriftung oder Aufnahme – attraktiver ist oder sie beide gleich stark genutzt werden. Dies suggeriert natürlich, dass es eventuell auch keine Daten zu untersuchen geben wird, im Falle dass die Nutzer einer dieser Art der Erhebung ablehnen.
5.1.2 Auswertung der soziodemographischen Fragen
In der Annahme, dass die User die soziodemographischen Fragen beantworten (Alter und Geschlecht), könnte sich in der Analyse ein soziodemographisches Bild abzeichnen, das das Durchschnittsalter der Informanten zeigt, sowie wie viele Frauen und Männer erreicht wurden. Weiterhin kann man diesbezüglich die Kompetenzen unter Berücksichtigung des Alters und des Geschlechts analysieren.
5.1.2.1 Männersprache vs. Frauensprache
Dieser Parameter wird nur dann in der Praxis Anwendung finden, wenn sich das von mir erwartete Ergebnis bestätigt. Da traditioneller Weise der Senn – also der Experte für Milch- und Käseverarbeitung bzw. Almwesen und somit der wertvollste Informant für VerbaAlpina – ein Mann ist, erwarte ich Unterschiede in der Sachkompetenz zwischen Männern und Frauen, speziell im höheren Alter. Vorstellbar wäre, dass der männliche Senn bei der Produktion und in Bereichen der körperlich anstrengenden Arbeit über größere Sachkompetenz verfügen könnte als die Frauen.
Diese Erwartungshaltung ergibt sich abgesehen von der Tradition auch durch den Umgang mit Karten aus Sprachatlanten wie z.B. die des AIS. Auf diesen finden sich häufig Anmerkungen des Explorators wenn sich die Frau des Senns oder ein weibliches Mitglied des Personals auf der Alm zu einem Stimulus äußert. Daher ist die Interpretation zulässig, dass der Explorator die Notwendigkeit gesehen hat, den Beleg als den eines weiblichen Informanten zu kennzeichnen, in der Annahme, dass es geschlechtsspezifische Unterschiede geben kann. Daher erhoffe ich mir, diese Annahme durch den Pretest widerlegen oder bestätigen zu können.
5.1.2.2 Durchschnittsalter der Informanten und eventuelle Auswirkungen auf die Sachkompetenz
Stets in der Annahme, dass die User bereit sind, ihre soziodemographischen Daten Preis zu geben, wird sich in der Auswertung der Daten ein Durchschnittsalter ergeben. Dies ist ein interessanter Punkt, da – wie schon in Teil zur Personenrecherche erläutert – es bzgl. des Alters eine gewisse Schwierigkeit innerhalb der Zielgruppe zu bewältigen gibt. Der Senn ist tendenziell ein älterer Mensch, während die Menschen, die geübt im Umgang mit den neuen Medien und Crowdsourcing sind, Teil einer jüngeren Generation sind. Daher kann auch hier die Ausgangshaltung widerlegt werden, wenn sich kompetente User im jungen Alter oder weniger kompetente User – sowohl in Bezug auf den Dialekt als auch auf die Sachkompetenz – eines höheren Alters finden. Ferner möchte ich untersuchen, ob mit absteigendem Alter die Sach- und Dialektkompetenz abnimmt oder ob diese an den Nachwuchs weitervermittelt werden.
5.1.3 Feedback
Wie bereits gezeigt, besteht nach den ersten 10 Fragen die Möglichkeit für den Nutzer ein Feedback zu vermitteln. Dies impliziert jedoch, dass der User den Test nach diesen 10 Fragen beendet und sich sein Feedback nur auf die erste Hälfte des Pretests bezieht. Entscheidet sich der User allerdings den gesamten Test durch zuarbeiten, so wird ihm die Möglichkeit des Feedbacks erst zum nach Abschluss angeboten.
In beiden Fällen geschieht die Vermittlung des Feedbacks über zwei Instanzen. Es gibt zunächst einen Fragebogen, in dem pauschal die wichtigsten Fragen gestellt werden.

Abbildung 20
Den größtmöglichen Nutzen würde VerbaAlpina aber aus einem persönlichen Feedback ziehen. Dies ist möglich in dem der Nutzer auf "inviare Feedback personale" klickt. Es öffnet sich ein Fenster, indem der User alles vermitteln kann, was er möchte. Dies wird direkt in einer Email an mich geschickt. Besonders aus dieser Möglichkeit erhofft sich VerbaAlpina die bestmöglichste Gestaltung der App/mobilen Website wie auch die Veränderung oder Anpassung bzgl. Design, sprachlicher Gestaltung, Wahl der Konzepte, Einsatz von Medien etc. zu finden, um den effizientesten Weg der Datenbeschaffung für die Crowdsourcingphase von VerbaAlpina zu finden.
5.2 Analyse am Beispiel von Colle Santa Lucia
Bisher haben sich durch die Erhebungsmethode der mobilen Website 10 Informanten aus dem Ort Colle Santa Lucia gefunden, die den Pretest bearbeitet haben. Es folgt nun eine Beispielanalyse nach den eben genannten Kriterien für diese sog. Minicrowd aus dem gleichen Ort. Wie angenommen bestätigt sich die Annahme heterogener Daten, wie auf folgender Tabelle zu sehen ist.

Tabelle 1
Wie durch die farbliche Markierung sofort ersichtlich ist, hat sich die Annahme der heterogenen Antworten bestätigt. Die Wahl der Farben ergibt sich aus der folgenden Überlegung. Die grün markierten Belege entsprechen durch ihre Häufigkeit dem Ausgangstyp. Je mehr sich die weiteren Belege also vom Ausgangstyp unterscheiden desto dunkler wird die Farbe (orange, braun). Da es sich bei den Fragen 9 und 10 um die Kompetenzfragen handelt, sind die korrekten Antworten dunkelgrün und die falschen Antworten rot markiert. Man erkennt also schnell, dass sich die User bei der Benennung der Konzepte 1-5 relativ einig waren, während sich danach Unterschiede auftun. Außerdem lässt sich gut ablesen, dass die Informanten aus Colle Santa Lucia die Kompetenzfrage 10, in der es nur eine richtige Antwort gab, einheitlich bestanden haben. Bei der Kompetenzfrage 9 standen 3 unterschiedliche Antworten zur Auswahl, wobei maggengo die exakte Antwort gewesen wäre, alpeggio zwar richtig ist, aber das einzelnde Gebäude und nicht die Stufe auf der Alm bezeichnet und cascina diesbezüglich nicht korrekt wäre. 5 der 10 Befragten haben ihr Alter und Geschlecht angegeben. Aus diesen Daten ergibt sich folgendes Profil des "Durchschnittsinformanten" aus Colle Santa Lucia, der durch diesen Pretest erreicht wurde:
- Weiblich
- 35,8 Jahre alt
- Verfügt sowohl über Dialekt- als auch Sachkompetenz
6. Fazit
Im Sinne VerbaAlpinas und besonders im Hinblick auf die Zielsetzung – nämlich die Verbreitung von Bezeichnungen und Bedeutungen – gibt es verschiedene mögliche Szenarien für den Umgang mit den neu erhobenen Daten. Eine Möglichkeit stellt die kartographische Darstellung der dialektalen Daten dar, wie sie in der Dialektographie bzw. Dialektometrie üblich ist. Da das Probandennetz wahrscheinlich sehr dünn sein wird, bietet sich der Umgang mit Voronoi-Diagrammen bzw. mit Thiessen-Polygonen an, besonders dann, wenn sich nach der Analyse einheitliche, also homogene Daten innerhalb eines Ortes zeigen. Im Polygonverfahren gilt als Grundannahme, "dass die Ähnlichkeit des unbekannten Wertes eines Punktes in der Fläche zum bekannten Messwert mit der Entfernung von diesem abnimmt, die Daten also umso unähnlicher sind, je weiter sie auseinander liegen (https://de.wikipedia.org/wiki/Voronoi-Diagramm/06.06.2016)."
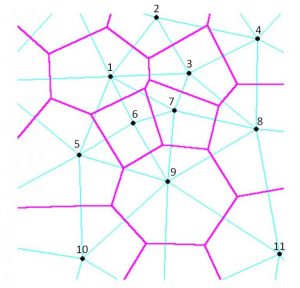
Abbildung 21 (vgl. https://www.dh-lehre.gwi.uni-muenchen.de/?p=29484)
Das heißt, man könnte die dialektale Ähnlichkeit bzw. Unähnlichkeit für die verschiedenen Regionen im Erhebungsgebiet farblich markieren und somit auf den ersten Blick die Zusammenhänge erkennen. Aus diesem Prozedere heraus, wäre die Erstellung eigener VerbaAlpina-Karten möglich.
Weiterhin ließen sich durch den Vergleich der heterogenen Daten (gemeindeunabhängig) diverse Phänomene feststellen, beispielsweise das der Italianisierung bestimmter Wörter im Dialekt. Vergleicht man die erhobenen Belege für ital. ricotta aus diversen Gemeinden, erkennt man, dass bis auf den Beleg eines Informanten immer ein dialektaler Beleg verwendet wurde, der sich nicht auf die morphologische Wurzel ricotta zurückführen lässt.
Bassa Friulana (Palmanova-Udine): le scuète
Colle Santa Lucia und Cortina d'Ampezzo: puina
Ovaro: la scueta
Badia: ciote
Bamboo: rigutta (!)
Durch die Verwendung von Crowdsourcing und speziell mit dieser Art der Erhebung, lassen sich also viele Prozesse wie Dynamik im Ort, Unterschiede in Sach- und Dialektkompetenz, neuer Alpenwortschatz und semantische Verschiebungen feststellen und analysieren. Weiterhin besteht der Vorteil im Gebrauch einer App/mobilen Seite darin, dass ein Automatismus erstellt werden kann, der die gewählten Konzepte ersetzen bzw. "fortlaufen" lassen kann, sodass eine ständige Aktualisierung der mobilen Website möglich ist. Somit ergibt sich daraus eine Anlaufstelle für den motivierten Informanten seinen Beitrag zur Wissenschaft zu leisten.
Diese diversen Möglichkeiten des Datenumgangs lassen sich gut im Kontext einer sogenannten digitalen Forschungsumgebung einbetten, in der sich künftig ein "virtuelles Forschungslabor" befinden soll. Dafür könnte man alle interessierten Informanten, die bereits durch das Crowdsourcing "rekrutiert" wurden, einladen durch die angebotenen Funktionen dieses Labors wie kartographische Darstellungen, Typisierungsstufen und Transkriptionsprogramme ihre eigenen Ergebnisse vorzustellen, Ergebnisse anderer Nutzer oder die VerbaAlpinas zu validieren oder auch zur Weiterentwicklung dieser Forschungsumgebung beizutragen (vgl. Krefeld, Thomas: Eine webbasierte, raumorientierte Forschungsumgebung).
7. Bibliographie
- Anhaiu, Doan/ Ramakrishnan, Raghu/ Halevy, Alon Y. (2011): "Crowdsourcings systems on the world wide web". In: Communications of the ACM. Vol. 54, Nr.4
- Kunzmann, Markus/Oberholzer, Susanne (2015): Projektvorstellung: VerbaAlpina. Würzburg
- Krefeld, Thomas (2013): Morgenröte eines Paradigmenwechsels – im linguistischen Umgang mit einer sprachlichen Variation. München
- Krefeld, Thomas (2016): ALD II: ein ethnographisch uninteressierter Regionalatlas. München
- Krefeld, Thomas (2016): Eine webbasierte, raumorientierte Forschungsumgebung. München
- Mutter, Christina (2015): Flyer_light. München
Internetquellen:
- http://www.grimme-institut.de/imblickpunkt/pdf/IB-Crowdsourcing.pdf
- http://www.gruenderszene.de/lexikon/begriffe/crowdsourcing
- https://www.zooniverse.org/
- http://www.zora.uzh.ch/105442/
- https://pma.gwi.uni-muenchen.de/sql.php?server=7&db=va_xxx&table=gemeinden_ak&pos=0&token=b771d79d949574aff662d3e0cbbf198d
- https://www.verba-alpina.gwi.uni-muenchen.de/wp-admin/admin.php?page=konzeptbaum
- https://de.wikipedia.org/wiki/Voronoi-Diagramm
Bibliographie
- Dialektologentreffen_Würzburg = Eintrag nicht gefunden
- Grimme Institut = Eintrag nicht gefunden
- Review Artciles = Eintrag nicht gefunden
- Mutter 2016 = Mutter, Christina: Flyer-Light