

2. Das Konzept Crowdsourcing
2.1 Was ist Crowdsourcing?
Der aus den englischen Wörtern crowd und outsourcing zusammengesetzte Neologismus crowdsourcing (dt. Schwarmauslagerung), bezeichnet eine heutzutage meist webbasierte Form der Arbeitsteilung, bei der Arbeits- und Kreativprozesse, Problemlösungen und Finanzierungsprojekte (crowdfounding) an eine undefinierte Masse von Internetnutzern ausgelagert werden. Dies funktioniert zumeist in Form eines Aufrufs auf einer Internetplattform, auf der die Nutzer freiwillig mitarbeiten können. Dabei ist ein besonderes Augenmerk auf den Mehrwert sowohl für die Institution, die ihre Crowd sucht, als auch für die Crowd selbst, zu legen (vgl. Review Artciles ).
Den Begriff Crowdsourcing beansprucht ein Journalist namens Jeff Howe im Jahr 2006 in einem Artikel für das US Magazin "Wired" geprägt zu haben. Seine These beinhaltet die konzeptionelle Unterscheidung des traditionellen Outsourcings, was bedeutet, dass Unternehmen Aufträge an Zulieferer vergibt, während das Crowdsourcing die Vergabe der Aufgaben an die Öffentlichkeit bezeichnet.
Da es normalerweise für die Arbeit der Crowd keine Bezahlung gibt, gilt es durch Bekanntheit, Anerkennung oder das Gefühl etwas Nützliches getan zu haben, die Masse zu belohnen. Ein passendes Beispiel dafür ist die Online-Enzyklopädie Wikipedia: Hier wird die Crowd zum Autor bzw. Redakteur einzelner oder mehrerer Artikel, ohne eine Vergütung zu erhalten. Wikipedia ist jedem online zugänglich und somit können alle davon profitieren. Die "Belohnung" für die Crowd ist also hierbei das Teilen ihres Wissens, wodurch sie eine Art Expertenstatus erhalten, sowie die Publikation ihrer Artikel. Der Erfolg dieses Prinzips ist unverkennbar, da fast jeder Internetnutzer die Enzyklopädie kennt und zu Rate zieht (vgl. Crowdsourcing Begriff ).
Im Fall von VerbaAlpina handelt es sich um eine Form des Crowdsourcings, die sich collective knowledge nennt. Unter diesem Begriff versteht sich die Sammlung, Organisation und Filterung von Wissen. Es geht dabei weniger um die Kompetenzen des Einzelnen, sondern eher um die Intelligenz der Masse und den gegenseitigen Austausch, sodass Daten und Informationen immer besser und präziser werden (vgl. Grimme Institut ).
2.2 Bereits angewendete Crowdsourcingsysteme
Als eines der erfolgreichsten Crowdsourcinginitiativen darf Zooniverse an dieser Stelle nicht fehlen.
"The Zooniverse is the world’s largest and most popular platform for people-powered research. This research is made possible by volunteers—hundreds of thousands of people around the world who come together to assist professional researchers. Our goal is to enable research that would not be possible, or practical, otherwise. Zooniverse research results in new discoveries, datasets useful to the wider research community, and many publications."
Mit seiner Plattform, auf der verschiedene Projekte zu finden sind, hat es Zooniverse geschafft Hunderttausende von Menschen zu motivieren, mobilisieren und zu sog. researcher zu machen. Ohne einen besonderen akademischen Hintergrund oder ein erwünschtes Profil sucht sich der User eines der vielen Projekte aus und kann durch das Beantworten einfacher Fragen den Forschern helfen und kann sich selbst in verschiedensten Bereichen wie Tiere und Natur, Geschichten, Galaxien, Literatur u.v.m. an der Forschung beteiligen.
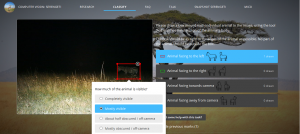
Abbildung 1 (vgl. https://www.zooniverse.org/about) Screenshot: 17.05.2016
2.3 Crowdsourcing und Linguistik
Bereits 1879 wurde von Crowdsourcing Gebrauch gemacht um die Linguistik voranzutreiben. Mit großen Erfolg kam die Technik des Crowdsourcings im Zuge der Produktion des Oxford English Dictionnary zum Einsatz. Der englische Philologe James Murray startete einen Aufruf an die gesamte anglophone Leserschaft mit der Bitte, ihm Belegstellen für alltägliche und ungewöhnliche Wörter zuzusenden. Der Erfolg ist unübersehbar, denn bis heute gilt das Oxford English Dictionnary als das Standardwörterbuch des Englischen (vgl. Grimme Institut ).
Durch die neue Medientechnologie ist eine enorme Erweiterung dieser simplen Idee möglich geworden. Wie Wikipedia, Yahoo! oder Linux u.A. beweisen, ermöglicht die 'Weisheit von vielen' unabhängig vom geographischen Standort, eine schnelle globale Vernetzung von Akteuren, sog. User und zudem die Aktivierung großer Massen. Als modernere Beispiele der erfolgreichen Verbindung von Linguistik und Crowdsourcing sind die Dialäkt Äpp von Adrian Lehmann und das Dialekt-Quiz des Atlas zur deutschen Alltagssprache anzuführen.
Die Dialäkt Äpp wurde so konstruiert, dass die dem User zwei unterschiedliche Funktionen bietet. Zum einen kann die Crowd ihren Schweizer Dialekt lokalisieren, indem die Aussprache von 16 Wörtern analysiert wird. Zum anderen kann der User Dialektwörter einsprechen und auch die Aufnahmen der anderen User hören und somit das dialektale Spektrum der deutschsprachigen Schweiz erforschen (vgl. Voice Äpp ).
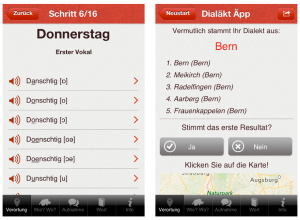
Abbildung 2 (vgl. Voice Äpp )
Das Quiz des Atlas zur deutschen Alltagssprache Moin, Grüezi, Servus: Sagen Sie uns wie Sie sprechen, und wir sagen Ihnen, woher Sie stammen ähnelt in seiner Funktionalität dem vorangegangen Beispiel. Nach dem Prinzip 'Wie sagst du zu..?' werden diverse Antwortmöglichkeiten, die morphologische Typen aus dem deutschsprachigen Raum aus Deutschland, Österreich und der Schweiz abbilden, angeboten. Am Ende des Quiz werden einige potenzielle Herkunftsgebiete des Users – nach Analyse seiner Antworten – angegeben, die, wie Erfahrungswerte zeigten, oft zutreffend waren.
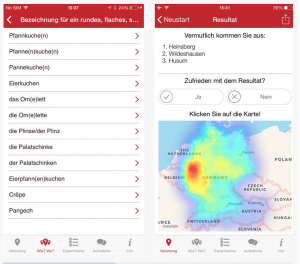
Abbildung 3 (vgl. Gruezi, Moin, Servus )
Allerdings ist hier keine Lokalisierung bzw. Georeferenzierung auf Dorfebene möglich, was jedoch als Untersuchungskriterium sehr interessant wäre, da sich trotz geographischer Nähe die Dialekte aus Nachbardörfern sehr unterscheiden können.
Dies nutzt VerbaAlpina durch die Verwendung einer Strategie, die erlaubt, die Dialektverortung zumindest bis auf Gemeindeebene zurück zu verfolgen. Im Crowdsourcing von VerbaAlpina geht es vor Allem darum, ein Sprach-und Sachwissen zu nutzen, dessen wissenschaftlicher Wert den Nutzern oft nicht bewusst ist. Somit können Lücken der Sprachatlanten, wie z.B. im AIS oder im ALI gefüllt werden, da diese nur selten den sehr spezifischen Alpenwortschatz erfasst haben. Durch die Vorgehensweise des geplanten Crowdsourcings können wir also vom unschätzbaren „Laien-Wissen“ profitieren.
Auf der folgenden Bildschirmaufnahme der interaktiven Karte der Website von VerbaAlpina ist graphisch eine "Datenlücke", die sich wegen mangelnder bzw. für VerbaAlpina nicht zungänglicher Datenbestände in Österreich abzeichnet, abgebildet und demonstriert daher die Notwendigkeit des Crowdsourcings.
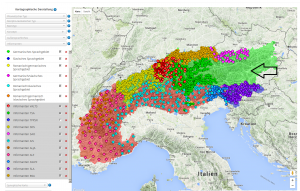
Abbildung 4
2.4 Grenzen und Möglichkeiten im Umgang mit Crowdsourcing
Die prinzipiellen Herausforderungen, die sich beim Gebrauch von Crowdsourcing stellen, sind die folgenden: Das Rekrutieren motivierter User und deren Beibehaltung, das sinnvolle Vereinen ihrer Beiträge, das Verteilen von Aufgaben, das Sicherstellen ihrer Kompetenzen, der Balanceakt zwischen Transparenz und Qualität sowie das Verhindern von Missbrauch (vgl. Review articles) (vgl. Review Articles ).
Dies erfordert eine genaue Strukturierung der Arbeitsaufträge, was sich allein schon in der Formulierung widerspiegelt. Abschreckend wissenschaftliche oder zu abstrakte Formulierungen sind daher dringlich zu vermeiden, aber auch zu spielerisch darf es nicht konzipiert sein, da ansonsten die Seriösität und somit das Ziel der Datenbeschaffung verloren geht. Die Ausgewogenheit zwischen Ernsthaftigkeit und Unterhaltungswert gilt es also auch zu berücksichtigen. Allgemein lässt sich sagen, dass die Schwächen des Crowdsurcing "viele Beliebigkeiten, Laienhaftigkeit und mangelnde Verlässlichkeit" (vgl. VerbaAlpina, Crowdsourcing) sind.
Die Stärken des Crowdsourcings sind ohne Frage Kreativität, Kollektivität und das Teilen der "Schwarmintelligenz". In Verbindung mit dem Web 2.0 sind schnell enorme Massen mobilisiert, die Basis für einen regen Wissensaustausch geschaffen und im positiven Fall folgt die Entstehung eines Schneeballsystem, welches ständige Informationen und eine wachsende Crowd garantieren kann. Je mehr User aktiviert werden, desto größer wird die Plattform und somit der Informationsfluss. Die Semantik des Begriffs User ist an dieser Stelle genau zu differenzieren: der User soll im Crowdsourcing ein Informant, ein Nutzer der Daten und auch ein Autor sein. Dies lässt sich gut an folgenden Graphiken veranschaulichen, die widerspiegeln, wie sich das Kommunikationsverhältnis zwischen Informanten und Autor durch das Nutzen des Crowdsourcing und somit im Sinne der Digital Humanities verändert.
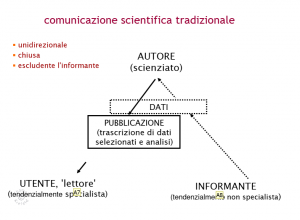
Abbildung 5 (vgl. Krefeld, Thomas (2013): Morgenröte eines Paradigmenwechsels)
Wie auf Abbildung 5 zu sehen, entsteht durch das bisherige Kommunikationsmodell zwischen Informant, Autor und Nutzer ein unidirektionaler Informationsfluss: vom Informanten zum Autor und vom Autor werden die verarbeiteten Daten für den User zugänglich gemacht.
Auf der folgenden Abbildung 6 werden nun die Veränderungen durch den Umgang mit Crowdsourcing deutlich erkennbar: ab jetzt kann ein reger Informationsaustausch in alle Richtungen erfolgen. Angewandt auf VerbaAlpina würde dieses neue Kommunikationsmodell Folgendes ergeben: der Informant vermittelt VerbaAlpina dialektale Daten, mittels Crowdsourcing landen diese direkt in der VerbaAlpina Datenbank, werden aufbereitet, d.h. transkribiert und typisiert und danach für die User zugänglich gemacht. Ein ebenso nützliches und wünschenswertes Szenario wäre, dass der linguistisch motivierte oder bewanderte User seine Daten gleich selbst transkribieren kann. Um auf den Begriff des Users zurückzukommen, ist hier nun zu sehen wie der Nutzer alle kommunikativen Funktionen übernehmen kann und soll. Der "Idealnutzer" VerbaAlpinas ist ein Dialektsprecher, also ein Informant, der aber auch die Daten, die von VerbaAlpina kommen, kommentieren, verändern oder validieren kann, also ein Autor, und das Datenmaterial auch zu eigenen Zwecken verwenden kann, folglich ein Nutzer. In jedem Fall ist der Austausch zwischen Autoren, Usern und Informanten aller Art durch die "Öffnung" der VerbaAlpinaplattform möglich und erwünscht.
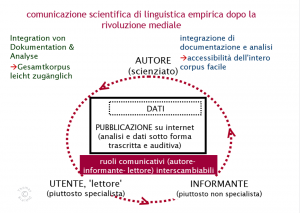
Abbildung 6 (vgl. Krefeld, Thomas (2013): Morgenröte eines Paradigmenwechsels)
Einmal auf der VerbaAlpinaplattform angekommen, geht es anschließend um die Arbeitsteilung. Bei der Vermittlung der Arbeitsaufträge und bei der darauffolgenden Filterung der Informationen zeichnen sich jedoch gewisse Herausforderungen ab.
Es muss die Frage gestellt werden, nach welchen Kriterien gefiltert wird. Das bedeutet, dass der Auftrag der Crowd so unmissverständlich wie möglich gestellt werden muss, sodass keine Missverständnisse o.Ä. auftreten können. Zudem sollte aber auch Raum für zusätzliche Informationen bedacht werden, damit der User soviel von seinem Wissen teilen kann wie er möchte, denn auch davon kann man ungeahnt profitieren. Zudem müssen bereits bei der Personenrecherche für die Crowd Einschränkungen gemacht werden; es muss zunächst ein Kriterienkatalog erstellt werden, nach dem passende User rekrutiert werden. Weiterhin darf die Genauigkeit nicht verloren gehen; im Falle des Collecitve Knowledge sollte nicht außer Acht gelassen werden, dass die Informationen so konkret wie möglich abgefragt werden müssen, damit die Ergebnisse verwertbar bleiben.
Die bereits aufgeführten Kriterien und alle weiteren, die in der Realisierung des Pretests Anwendung fanden, werden im folgenden Teil der Arbeit zur Methodik und Vorgehensweise sowie zur Realisierung zusammengetragen.
Bibliographie
- Crowdsourcing Begriff = Eintrag nicht gefunden
- Grimme Institut = Eintrag nicht gefunden
- Gruezi, Moin, Servus = Eintrag nicht gefunden
- Review Artciles = Eintrag nicht gefunden
- Voice Äpp = Eintrag nicht gefunden
- Review Articles = Anhaiu, Doan/ Ramakrishnan, Raghu/ Halevy, Alon Y. (2011): Crowdsourcing Systems on the World-Wide Web, in: Review articles: Communications of the ACM, vol. 54, 86-96. Link