

Die folgenden Ausführungen sind als Ergänzungen zum Vortrag von Thomas Krefeld zu verstehen. Überschneidungen und Wiederholungen sind dabei nicht ganz ausgeschlossen. Der Focus liegt im Folgenden den tendenziell eher quantifizierenden Methoden, die speziell die Datenbank von VerbaAlpina, VA_DB, an die Hand gibt.
Komplementär zur Notwendigkeit, jeden einzelnen Basistypen gewissermaßen qualitativ in der Stratigraphie des alpinen Sprachraums zu lokalisieren, wie im Beitrag von Thomas Krefeld gezeigt werden sollte, lässt sich schon quantitativ grundsätzlich feststellen, dass sämtliche im Alpenraum verbreiteten morpholexikalischen Typen, die unterschiedlichen Sprachfamilien angehören, jedoch auf gemeinsame Basistypen zurückgehen, einen wie auch immer gearteten Sprachkontakt voraussetzen. Dasselbe gilt für alle vorrömischen oder lateinischen Basistypen, die ihren Weg in das Germanische oder Slawische gefunden haben, jedoch natürlich nicht für lateinische Basistypen, die ins Romanische gewandert sind.
Als Basistypen definiert VerbaAlpina den jeweils ältesten fassbaren morpholexikalischen Typen, dem erkennbar eine bestimmte lexematische Wurzel innewohnt. In Betracht kommen dabei im Wesentlichen Wörter aus dem Lateinischen, dem vorrömischen Substrat, dem Griechischen, dem Keltischen, dem Germanischen und dem Slawischen. Sofern möglich, erfolgt eine Identifizierung in einem definierten Referenzwörterbuch, wie z.B. dem lateinischen Wörterbuch von Karl Ernst Georges.
VerbaAlpina verwaltet sämtliche sprachbezogenen Daten in einer Vielzahl von Tabellen, die in ihrer Gesamtheit eine relationale Datenbank bilden. In einer dieser Tabellen sind die Basistypen versammelt. Die Tabelle dokumentiert neben der Orthographie eines Basistypen auch dessen Sprachzugehörigkeit, sowie, demnächst, auch den Verweis auf eventuelle Einträge in einem der Referenzwörterbücher.
Die Zuordnung zu den aktuell im Alpenraum verbreiteten morpholexikalischen Typen erfolgt, wie in relationalen Datenbanken üblich, durch die Zuordnung von Identifikationsnummern, sog. IDs. Im einfachsten Fall sieht eine solche Zuordnung folgendermaßen aus:
Die Tabelle der Basistypen enthält den Eintrag "butyru(m) (lat)":
| ID_Basistyp | Basistyp |
| 128 | butyru(m) (lat) |
Die Tabelle der morpholexikalischen Typen ist ganz ähnlich strukturiert. Auch in ihr ist jeder Eintrag durch eine ID eindeutig identifiziert:
| ID_Morphtyp | Morphtyp |
| 591 | beurre / burro |
Im einfachsten Fall erfolgt die Zuordnung eines Basistypen zu einem Morphtypen durch die Eintragung der ID des Basistypen in ein eigenes Feld in der Tabelle der Morphtypen:
| ID_Morphtyp | Morphtyp | ID_Basistyp |
| 591 | beurre / burro | 128 |
Speziell im Fall der deutschen Komposita kann es vorkommen, dass ein Morphtyp nicht nur einem, sondern auch zwei Basistypen zugeordnet ist. Dies ist z.B. der Fall beim deutschen Wort Alphütte. Es geht zum einen zurück auf den Basistypen "alpes" und zum anderen auf den Basistypen "hutta". In der strukturierten Abbildung im Tabellenformat stellt sich dies wie folgt dar:
| ID_Basistyp | Basistyp |
| 53 | alpes (vor) |
| 48 | hutta (ger) |
| ID_Morphtyp | Morphtyp | ID_Basistyp |
| 7 | Alphütte | 53, 48 |
Die verkettete Eintragung der beiden IDs der Basistypen in der Tabelle der Morphtypen ist ungünstig. Aus diesem Grund erfolgt die Verwendung einer Zwischentabelle, in der die Kombination der Identifikationsnummern eingetragen wird:
| ID_Morphtyp | ID_Basistyp |
| 7 | 48 |
| 7 | 53 |
Die Datenbank erledigt die logische und synoptische Kombination dieser nun insgesamt drei Tabellen, was schließlich zu folgender Darstellung führt:
| ID_Morphtyp | Morphtyp | ID_Basistyp | Basistyp |
| 7 | Alphütte | 53 | alpes (vor) |
| 7 | Alphütte | 48 | hutta (ger) |
Ebenso wie jedem Basistypen ist auch jedem morpholexikalischen Typen eine Sprache zugeordnet. Die jeweilige Zugehörigkeit ist in den Datenbanktabellen als eigenes Merkmal registriert und kann in die gezeigte synoptische Verknüpfung mit eingebunden werden:
| ID_Basistyp | Basistyp | Sprache_Basistyp | ID_Morphtyp | Morphtyp | Sprache_Morphtyp |
| 724 | thûmo | goh | 639 | dûmli(n)ge(n) | ger |
| 336 | caldaria | lat | 2400 | chaudière / caldaia | rom |
| 392 | campus | lat | 525 | ciampei | rom |
| 478 | klětь | sla | 1714 | klet | sla |
| 1165 | prīmus | lat | 6519 | prime / primo | rom |
Die Identifikationsnummern dienen nur der korrekten Zuordnung und können in der Darstellung einfach weggelassen werden, so dass sich ein übersichtlicheres Bild ergibt:
| Basistyp | Sprache_Basistyp | Morphtyp | Sprache_Morphtyp |
| *þūmōn | ger | dûmli(n)ge(n) | ger |
| caldaria | lat | chaudière / caldaia | rom |
| campus | lat | ciampei | rom |
| klětь | sla | klet | sla |
| prīmus | lat | prime / primo | rom |
In dem so strukturierten Datenbestand kann nun gezielt nach Sprachkontaktphänomenen gesucht werden. Die Kriterien sind von Thomas Krefeld bereits vorgestellt worden. In etwas formalisierter Schreibweise lassen sie sich vor dem Hintergrund der soeben vorgestellten Datenstruktur wie folgt darstellen:
Einfaches Muster: Ein Basistyp aus einer Sprachfamilie geht in eine andere Sprachfamilie über:
- lateinisch/romanischer Basistyp -> germanischer Morphtyp
- lateinisch/romanischer Basistyp -> slawischer Morphtyp
- germanischer Basistyp -> slawischer Morphtyp
- slawischer Basistyp -> germanischer Morphtyp
Komplexes Muster: Ein Basistyp aus einer Sprachfamilie geht in mehrere andere Sprachfamilien über:
- lateinisch/romanischer Basistyp -> germanischer und slawischer Morphtyp
- lateinisch/romanischer Basistyp -> romanischer und germanischer und slawischer Morphtyp
Für die Identifizierung dieser Muster im relationalen Datenformat formuliert man die Bedingung, dass die Felder Sprache_Basistyp und im Feld Sprache_Morphtyp bestimmte Werte aufweisen müssen. Die Datenbanksprache SQL basiert dabei auf dem Englischen. Für das Auffinden von lateinischen Basistypen, die ins Germanische gewandert sind, schreibt man z.B.:
... where sprache_basistyp = 'lat' and sprache_morphtyp = 'ger'
Das Ergebnis sieht dann wie folgt aus (Ausschnitt):
| Basistyp | Sprache_Basistyp | Morphtyp | Sprache_Morphtyp |
| *brŏcca | lat | Britschger | ger |
| unguere | lat | Anke | ger |
| cūpella | lat | Kübel | ger |
| caseu(m) | lat | Käsestängel | ger |
| camera | lat | Milchkammer | ger |
| butyru(m) | lat | Butter | ger |
| unguere | lat | Ankentutel | ger |
Selbstverständlich lassen sich die entsprechenden Ergebnisse zählen und damit auch weitere Berechnungen anstellen. So ist es z.B. möglich zu berechnen, wie häufig lateinische Basistypen in germanischen Morphtypen vertreten sind, die einer bestimmten Konzeptdomäne zugeordnet sind. Solche und ähnliche statistische Analysen sind aktuell als Themenvorschläge für Studentenpraktika am Institut für Statistik der Ludwig-Maximilians-Universität ausgeschrieben.
Für die Identifizierung der etwas komplexeren Fälle, in denen ein Basistyp seinen Weg in mehrere andere Sprachfamilien gefunden hat, muss der Datenbestand nach Basistypen gruppiert und die verknüpften morpholexikalischen Typen sowie deren Sprachzugehörigkeit konkateniert abgebildet werden:
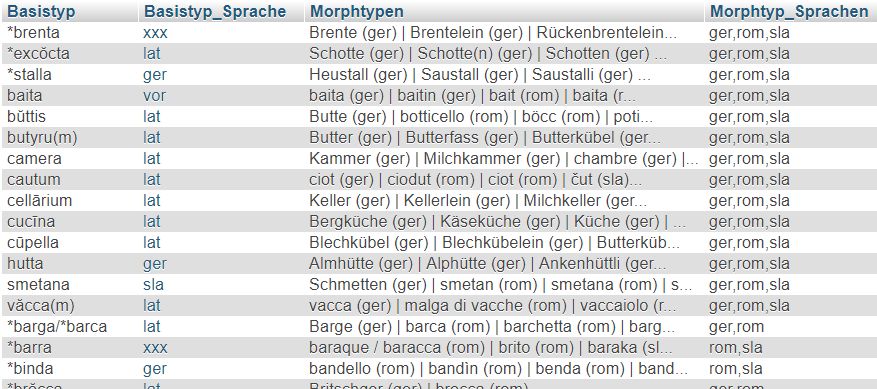
Die präsentierten Beispiele können im Einzelfall durchaus noch Fehler enthalten, die auf inkorrekten Identifizierungen von Basistypen basieren. Diese werden im Laufe der Arbeit am Material beseitigt werden. Es geht hier im Moment nur darum, die Methodik vorzuführen.
Aktuell sind insgesamt 14 Basistypen in allen drei Sprachfamilien vertreten, 32 im romanischen und germanischen Sprachraum, 28 im romanischen und slavischen sowie 7 im germanischen und slavischen. Hinzu kommen derzeit 32 weitere Basistypen, die ausschließlich entweder ins Germanische oder ins Slavische übergegangen sind.
Das bislang von VerbaAlpina verwendete Datenmodell besitzt durchaus noch seine Schwächen. Bislang ist es nur möglich, einen morpholexikalischen Typen an einen bestimmten Basistypen zu binden. Als Beispiel seien der germanische morpholexikalische Typ "Käser" und der romanische Typ "casera" genannt. Die folgende Karte zeigt die Verbreitung des germanischen morpholexikalischen Typen Käser (grün) und des romanischen Typen casera (gelb):
Beide Typen sind zweifelfsfrei vom lateinischen casearius herzuleiten, das seinerseits wiederum mit caseus zusammenhängt. Somit stellt sich die Frage, für welchen Basistypen man sich entscheidet: casearius oder caseus. Derzeit sind beide morpholexikalischen Typen mit dem Basistyp caseus verbunden, was sie mit anderen morpholexikalischen Typen wie z.B. dem deutschen Käse verbindet. Daraus ergibt sich eine gewisse Asymmetrie, besteht doch eine engere Verbindung zwischen Kaser und casera als etwa zwischen Kaser und Käse. Würde man nun Kaser und casera den Basistypen casearia zuweisen, ginge wiederum der offenkundig auch vorhandene Zusammenhang mit Käse verloren. Wie damit umzugehen ist, ist noch nicht entschieden. Eine Möglichkeit bestünde darin, die Abbildung der Basistypen im Datenschema weiter zu differenzieren, also etwa zu dokumentieren, dass das lateinische casearius mit caseus verbunden ist.
Die Grenze zwischen den Verbreitungsgebieten der beiden morpholexikalischen Typen verläuft ziemlich exakt entlang der Grenze zwischen dem germanischen (grün) und dem romanischen (rot). Hinzu kommen weitere Gebiete wie natürlich das slawische sowie eine Reihe von Übergangszonen und Enklaven, in denen aktuell Mehrsprachigkeit herrscht. Die Definition der Sprachzugehörigkeit erfolgt im Datenbestand von VerbaAlpina auf Gemeindeebene. Bislang erfolgte die entsprechende Zuweisung mehr oder minder intuitiv. Demnächst orientiert sich die entsprechende Definition an der Sprachzugehörigkeit der Informanten, von denen die Belege aus einer Gemeinde stammen. Sobald für eine Gemeinde Informanten registriert sind, die unterschiedlichen Sprachfamilien zuzuordnen sind, erhält die entsprechende Gemeinde den Status der Mehrsprachigkeit. Auf diese Weise ist eine transparente und belastbare Regelung für die Feststellung von Ein- oder Mehrsprachigkeit gefunden. Durch die Chronoreferenzierung der von VerbaAlpina gesammelten Daten lassen sich, wenigstens theoretisch, auch Veränderungen im Verlauf der Sprachgrenzen dokumentieren und visualisieren. Die Aussagekraft der entsprechenden Analyseergebnisse hängt aber natürlich von der Dichte und der Homogenität des gesammelten Datenmaterials ab.
Ich möchte die Gelegenheit nutzen und auf neuere Entwicklungen im Projekt VerbaAlpina hinzuweisen.
Seit kurzem ist es möglich, auf der interaktiven online-Karte von VerbaAlpina nicht nur die über das Menü abrufbaren Kategorien kartieren zu lassen, sondern auch nahezu beliebige andere analytische Abfrageergebnisse.
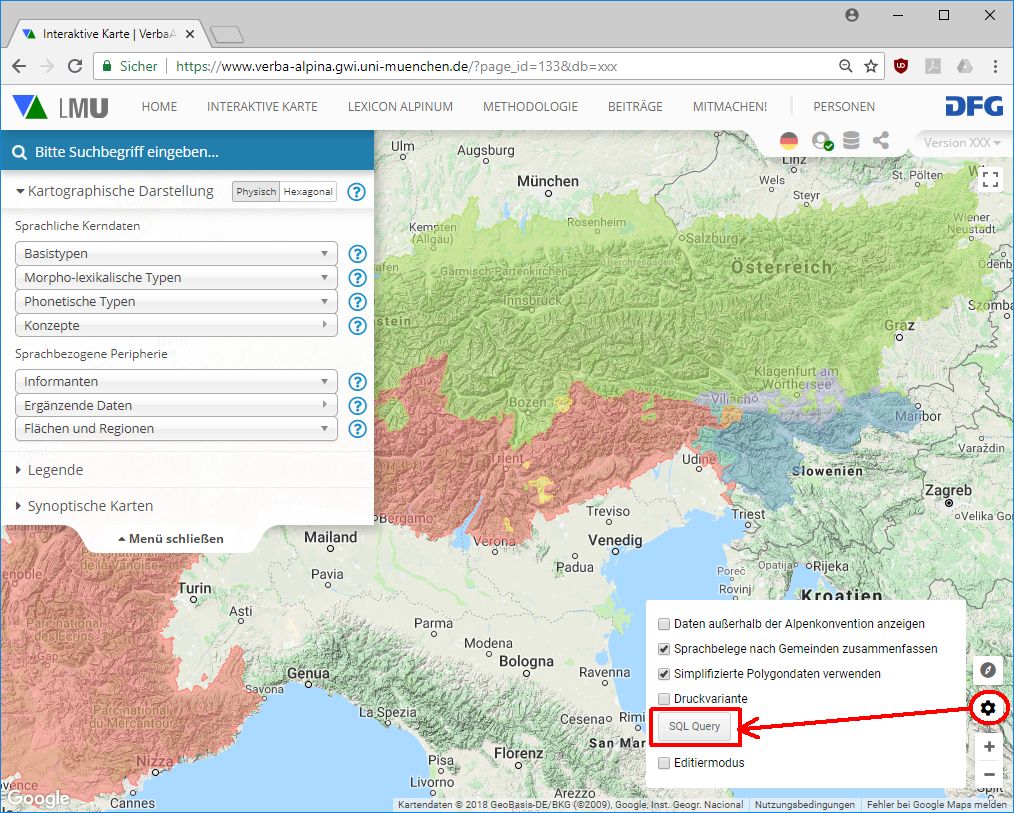
Aufruf des Formulars für die Eingabe von SQL-Statements
Als Beispiel kann hier die Kartierung der morpholexikalischen Typen vorgeführt werden, die mit Basistypen verbunden sind, die sowohl im germanischen wie auch im slavischen Sprachraum verbreitet sind.
⇓
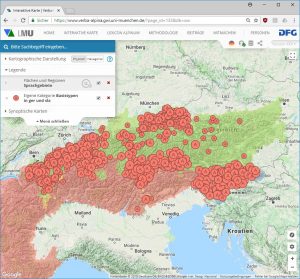
Qualitative Darstellung der Verteilung von morpholexikalischen Typen, denen Basistypen zugrunde liegen, die sowohl im germanischen wie auch slawische Sprachraum verbreitet sind (Link zur Karte: https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=xxx&tk=1533)
Die synoptische Überlagerung der Sprachfamiliengebiete und der Verbreitung der Basistypen kann aufschlussreiche Muster ergeben, muss dies aber natürlich nicht zwingend. Es bietet sich daher an, auf der Suche nach aussagekräftigen Mustern durch Veränderung der Parameter immer neue Kartierungen zu erzeugen. Allerdings stoßen manche Kartierungsversuche an natürliche Grenzen. So ist das System z.B. mit der Kartierung der Verbreitung von morpholexikalischen Typen, die sowohl im romanischen als auch im germanischen Sprachraum verbreitet sind, noch überfordert. Die entsprechende Kartierung auf Basis der Gemeinden, für die entsprechende Belege vorliegen, würde insgesamt über 1400 Kartensymbole umfassen. Der Nutzen einer Kartierung mit einer derart hohen Anzahl von Kartensymbolen wäre ohnehin sehr begrenzt. Eine quantifizierende Darstellung der Ergebnisse, die auf der online-Karte von VerbaAlpina ebenfalls möglich ist, könnte jedoch einen guten Überblick liefern. Die nachfolgende Karte zeigt die quantifizierende Abbildung der oben dargestellten qualitativen Karte auf Basis von Verwaltungseinheiten mittlerer Größe (sog. NUTS3-Regionen). Die Farbgebung der einzelnen Regionen orientiert sich an der Anzahl von Belegpunkten innerhalb der Regionen.
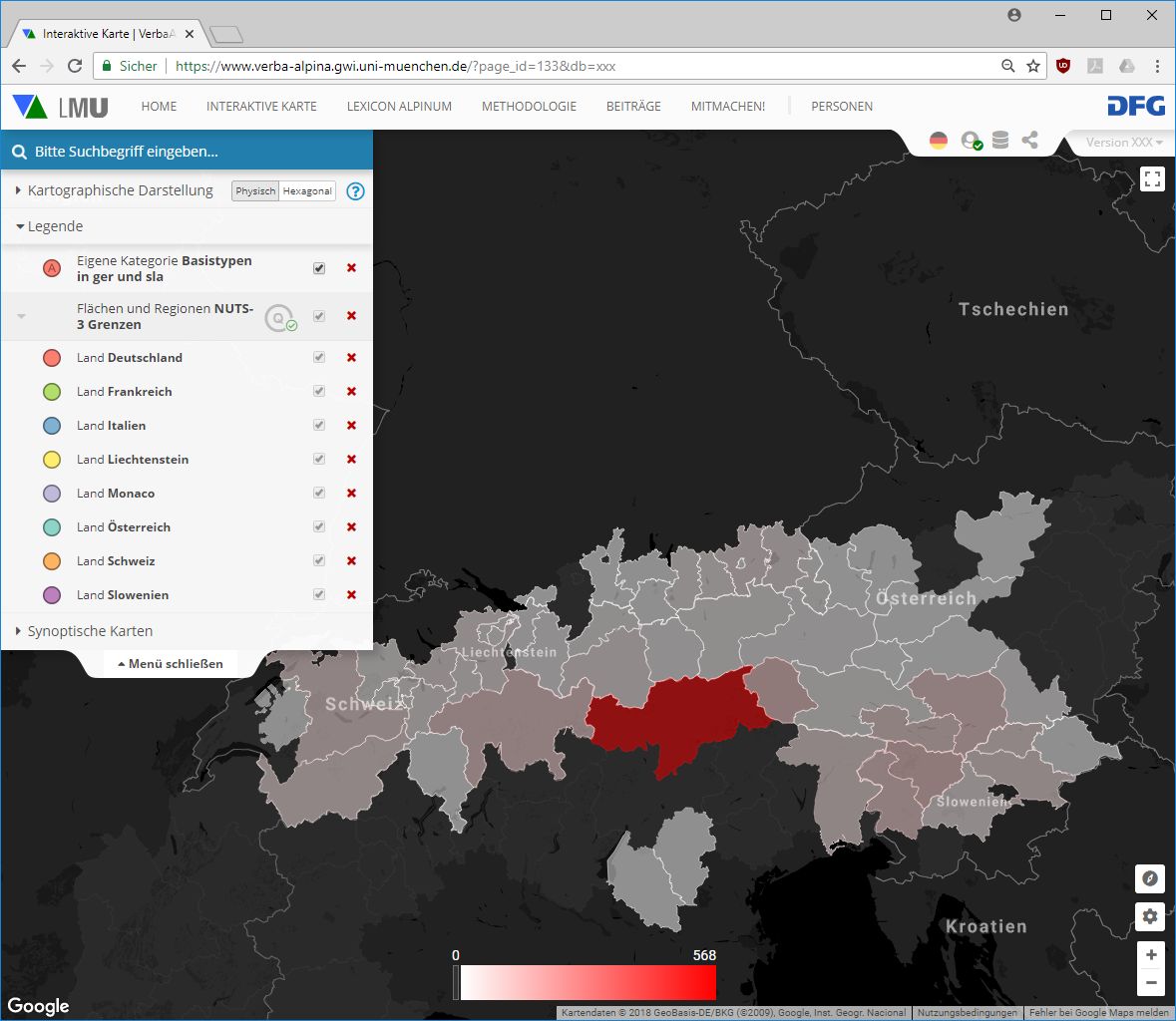
Quantifizierende Darstellung der Verteilung von morpholexikalischen Typen, denen Basistypen zugrunde liegen, die sowohl im germanischen wie auch slawische Sprachraum verbreitet sind (Link zur Karte: https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=xxx&tk=1531)
Neben der kartographischen Abbildung der Analyseergebnisse bietet die Datenbank auch rein arithmetisch-statistische Analysemöglichkeiten. So ließe sich z.B. die Frage stellen, ob ganz bestimmte Konzeptdomänen besonders häufig mit morpholexikalischen Typen verbunden sind, die über die Grenzen von Sprachfamilien hinweg verbreitet sind.
Bereits jetzt sind statistische Analysen dieser Art mit dem Datenbestand in der VerbaAlpina-Datenbank möglich. Aktuell sind dafür noch Kenntnisse in der Abfragesprache SQL nötig. Künftig sollen jedoch auch spezifisch statistische Tools wie z.B. das weit verbreitete Statistikprogramm R zur Verfügung stehen.
VerbaAlpina steht in Verbindung mit den Entwicklern der Platform MAX, die derzeit in Kooperation zwischen der Kunstgeschichte und der Statistik an der LMU entwickelt wird.
Screenshot aus dem statistischen Analysetool MAX (https://dhvlab.gwi.uni-muenchen.de/max/)
MAX soll primär der statistischen Analyse von Museumsbeständen dienen. Das System ist jedoch so ausgelegt, dass damit im Grunde beliebige relational strukturierte Datensätze mit statistischen Methoden untersucht werden können. Innerhalb von VerbaAlpina soll demnächst ein abgeschlossener Bereich entstehen, der den Partnern von VerbaAlpina zur Verfügung gestellt wird. Innerhalb dieses Bereichs können dann neben den VerbaAlpina-Daten auch persönliche Daten und auch beide in Kombination statistisch analysiert und kartographisch visualisiert werden. VerbaAlpina bezeichnet diesen abgeschlossenen Bereich als "Forschungslabor". Eine wesentliche Funktionalität dieses Forschungslabors wird die Möglichkeit zum Teilen von Daten, Visualisierungen und Analysen sein, in etwa in der Art, wie man es schon von zahlreichen Diensten im Internet wie z.B. Google und Facebook kennt. Die im Rahmen des MAX-Projekts entwickelten Funktionalitäten zur statistischen Datenanalyse sollen in das VerbaAlpina-Forschungslabor integriert werden.
Ich danke Ihnen für Ihre Aufmerksamkeit.
-- Verknüpfung zwischen Basis- und Morphtypen select * from basistypen a join vtbl_morph_basistyp b using(id_basistyp) join morph_typen c using (id_morph_typ) ;
-- Morphtypen, die mehr als einem Basistypen zugeordnet sind. select group_concat(distinct c.Orth) as Morphtyp, group_concat(a.Orth) as Basistypen from basistypen a join vtbl_morph_basistyp b using(id_basistyp) join morph_typen c using (id_morph_typ) group by id_morph_typ having count(*) > 1 ;
-- Basistyp butyru(m) und Morphtyp beurre / burro select a.ID_Basistyp, concat(a.Orth, ' (', a.Sprache, ')') as Basistyp, c.ID_morph_Typ as ID_Morphtyp, c.Orth from basistypen a join vtbl_morph_basistyp b using(id_basistyp) join morph_typen c using (id_morph_typ) where c.Orth like '%burro%' limit 1 ;
-- Beispiel für die kombinierte Darstellung von Basistypen und -- morpholexikalischen Typen samt jeweiliger Sprachzuordnung select -- a.ID_Basistyp, a.Orth as Basistyp, a.Sprache as Sprache_Basistyp, -- c.ID_morph_Typ as ID_Morphtyp, c.Orth as Morphtyp, c.Sprache as Sprache_Morphtyp from basistypen a join vtbl_morph_basistyp b using(id_basistyp) join morph_typen c using (id_morph_typ) where a.Orth in ('caldaria','klětь','prīmus','*þūmōn','campus') group by a.Orth -- order by rand() limit 5 ;
-- Anzahl von Basistypen, die in mehreren Sprachfamilien vertreten sind
select morphtyp_sprachen, count(*) as Anzahl from
(
select
a.Orth as Basistyp,
a.Sprache as Basistyp_Sprache,
group_concat(distinct c.Orth, ' (', c.Sprache, ')' order by c.Sprache, c.Orth separator ' | ') as Morphtypen,
group_concat(distinct c.Sprache order by c.Sprache) as Morphtyp_Sprachen
from basistypen a
join vtbl_morph_basistyp b using(id_basistyp)
join morph_typen c using (id_morph_typ)
group by a.Orth, a.Sprache
having group_concat(distinct c.Sprache) like '%,%'
-- order by char_length(group_concat(distinct c.Sprache)) desc, group_concat(distinct c.Sprache)
) sq
group by morphtyp_sprachen
;
-- Vorrömische und lateinische Basistypen, die entweder ins Germanische
-- oder ins Slavische gewandert sind
select
a.Orth as Basistyp,
a.Sprache as Sprache_Basistyp,
group_concat(distinct c.Sprache) as Sprache_Morphtyp,
c.Orth as Morphtyp
from basistypen a
join vtbl_morph_basistyp b using(Id_Basistyp)
join morph_typen c using(ID_morph_Typ)
where
a.Sprache like 'lat'
or a.Sprache like 'vor'
group by a.Orth
having
group_concat(distinct c.Sprache) not like '%rom%'
and group_concat(distinct c.Sprache) not like '%,%'
;
Der öffentlich zugängliche Teil von VerbaAlpina, gleichsam das Schaufenster des Projekts, präsentiert sich auf einem Internet-Portal unter der Adresse www.verba-alpina.gwi.uni-muenchen.de. Dort findet sich mit der interaktiven Online-Karte auch der zentrale Zugang zu dem von VerbaAlpina gesammelten Material. Die Karte erlaubt im Wesentlichen die Visualisierung der Verbreitung bestimmter morpholexikalischer Typen, wobei die Wahlmöglichkeiten auf die technisch implementierten Filterfunktionen beschränkt sind. Die Auswahl kann entweder aus semasiologischer oder aus onomasiologischer Perspektive erfolgen, die Kartierung der Sprachdaten kann außerdem noch kontrastiv ergänzt werden um Daten der "sprachbezogenen Peripherie" wie etwa die Fundstellen antiker lateinischer Inschriften im Alpenraum. Neben der qualitativen Abbildung der Daten ist nach Auswahl einer arealen Gliederung auch die arealbezogene quantifizierende Abbildung der Daten möglich.
Sämtliche auf der Karte darstellbaren Daten werden im Hintergrund in einer relationalen MySQL-Datenbank verwaltet. Diese Datenbank bietet eine Vielzahl an Möglichkeiten der Datenanalyse, die deutlich über die Optionen hinausgehen, die auf der Karte zugänglich sind. Der unmittelbare Zugang zur VerbaAlpina-Datenbank (VA_DB) erfolgt u.a. über ein generisches Web-Interface (PhpMyAdmin). Daneben sind auch andere, teils komfortablere und schnellere Zugangsarten möglich, etwa unter Verwendung sog. Client-Programme wie z.B. MySQL-Workbench oder HeidiSQL. Die direkte Nutzung von VA_DB ist den Kooperationspartnern von VerbaAlpina vorbehalten. Von Vorteil ist die Kenntnis einer speziell für relationale Datenstrukturen entwickelten Programmiersprache namens SQL. Erst der souveräne Umgang mit dieser Sprache gestattet es, das Potential des VerbaAlpina-Datenbestands voll auszuschöpfen. Im Folgenden soll anhand exemplarischer Analysen, die speziell auf die Dimension des Sprachkontakts fokussieren, eine Vorstellung von den Möglichkeiten gegeben werden.
VA_DB enthält unter anderem zwei Tabellen, in denen die ansonsten hauptsächlich aus informatischen und technischen Gründen auf eine Vielzahl von Detailtabellen verteilten Daten gleichsam wie in einem Brennglas gebündelt sind. Eine der beiden Tabellen enthält die Sprachdaten, die andere die der sprachbezogenen Peripherie. Beide Tabellen repräsentieren Instanzen der Schnittstelle VAP (= VA ⇒ Partner) und tragen den Namen vap_ling_de bzw. vap_geo_de. Jede der beiden Tabellen liegt in mehreren Sprachversionen vor (vap_ling_it, vap_ling_fr, vap_ling_slo ...).

Ausschnitt aus der Schnittstelle vap_ling_de
Die Schnittstelle vap_ling ist eine Tabelle mit einer Vielzahl an Spalten, die sich bezüglich ihres Inhalts in sechs Gruppen unterteilen lassen:
-- 1) Referenzsystem: Angaben zur Herkunft eines Sprachbelegs Id_Beleg Beleg Quelle_Beleg Sprache_Informant Publikationsjahr Erhebungsjahr -- 2) Bedeutung des Belegs: Konzeptzuweisung Name_Konzept Beschreibung_Konzept -- 3) Typisierung: Klassifizierung der Sprachbelege (Morpholexikalischer Typ, phonetischer Typ) Art_Typ Typ Sprache_Typ Wortart Affix Genus Referenz_Typ Quelle_Typisierung -- 4) Ursprung des Typs Basistyp Basistyp_Unsicher Etymon Sprache_Etymon -- 5) Georeferenzierung Breitengrad Laengengrad Gemeinde -- 6) Sonstiges Bemerkungen
Die Gruppe 1) enthält das sog. Referenzsystem, das in erster Linie Angaben zur Herkunft des in der Spalte `Beleg` gespeicherten Einzelbelegs beinhaltet. Generell stammen alle bislang in VA_DB gesammelten Einzelbelege aus Sprachatlanten, georeferenzierten Wörterbüchern oder von der sog. Crowd, also von Informanten, die Sprachdaten über das im Internet zugängliche Crowd-Sourcing-Tool beigesteuert haben. Die Einzelbelege werden nach Möglichkeit in IPA-Gestalt, der phonetischen Referenztranskription von VA, abgebildet. Die Daten in dieser Gruppe 1) enthalten auch Informationen zur Chronoreferenzierung, die schließlich für Analysen im Hinblick auf den Sprachwandel von großem Interesse sein können. In den meisten Fällen ist diese Chronoreferenzierung von den Publikationsjahren der Sprachatlanten und Wörterbücher bzw. von den Zeitpunkten der dahinterstehenden Erhebungen abgeleitet, die von sehr unterschiedlicher Genauigkeit sein können. Im Fall des AIS z.B. sind die Erhebungsdaten häufig auf den Tag genau dokumentiert, in anderen Fällen lassen sich lediglich Zeiträume von mehreren Jahren feststellen.
Die Gruppe 2) dient der Dokumentation des Konzeptes, das mit dem Einzelbeleg im konkreten Fall bezeichnet wird. Die Gruppen 3) bis 5) enthalten dem Einzelbeleg von den Mitarbeitern von VerbaAlpina zugewiesene sprachliche Klassifizierungen. Im Mittelpunkt steht dabei die Identifizierung der morpholexikalischen Typen, die über die Attribute "Orthographie" (= Typ), "Sprachzugehörigkeit", "Wortart", "Affigierung" und "Genus" definiert sind. Im Feld `Referenz_Typ` sind Verweise auf Lemmata in bestehenden Wörterbüchern wie etwa dem Duden, dem schweizerdeutschen Idiotikon oder auch der italienischen Treccani eingetragen.
Die Gruppe 4) enthält Informationen zur Herkunft eines morpholexikalischen Typs. Die Kategorie "Basistyp" wurde eingeführt, weil es vielfach nicht möglich ist zu entscheiden, auf welchem Weg ein offenkundiger lexikalischer Vorläufer eines morpholexikalischen Typs schließlich in diesen eingeflossen ist. Grundsätzlich kann dabei das klassische Szenario im Sinne eines Etymons vorliegen, ein Typ sich also über die Zeit in einer homogenen Sprachgemeinschaft aus einer älteren Vorstufe entwickelt haben. Daneben besteht jedoch auch die Möglichkeit der Entlehnung im Rahmen einer Sprachkontaktsituation. Auch die unabhängige Entwicklung zweier offenkundig miteinander verwandter morphlexikalischer Typen in unterschiedlichen Sprachfamilien aus einem gemeinsamen Vorläufer gehört hierher. Die Kategorie Basistyp lässt eine Entscheidung in dieser Hinsicht bewusst offen.
Die Gruppe 5) schließlich leistet die geographische Verankerung der sprachlichen Einzelbelege.
Die hier aufgespannte und kurz skizzierte Matrix bietet nun eine Vielzahl von Ansätzen für analytische Berechnungen, die u.a. mit der Datenbanksprache SQL durchgeführt werden können. Vor dem Hintergrund der Frage nach Sprachkontaktphänomenen und ihren Reflexen in den VerbaAlpina-Daten bietet sich zunächst eine Analyse der sprachgrenzüberschreitenden Verbreitung der bislang registrierten Basistypen an.
Die Dimension des Sprachkontakts spiegelt sich in den VerbaAlpina-Daten zunächst in der Zuweisung von Sprachfamilien auf den folgenden Ebenen. So ist
- jeder Gemeinde,
- jedem Informanten
- und jedem morpholexikalischen Typ
eine bestimmte Sprachfamilie zugeordnet. VerbaAlpina unterscheidet nicht zwischen Einzel- bzw. Nationalsprachen. Es existieren insgesamt 7 unterschiedliche Kategorien von Sprachgebieten. Zu den drei "homogenen" Gebieten des Romanischen, Germanischen und Slawischen gesellen sich insgesamt vier Kategorien von Mischgebieten, die sich entweder entlang der Sprachgrenzen verteilen oder auch als Exklaven isoliert innerhalb eines fremden Sprachgebiets liegen. Die Zuweisung der einzelnen Gemeinden zu diesen Kategorien ist kaum objektiv durchführbar und ist im Einzelfall sicher diskussionswürdig. Dies gilt hauptsächlich für die erwähnten Mischkategorien, in denen Mehrsprachigkeit vorliegt, bzw. überhaupt für Regionen in der Nähe der Sprachgrenzen. So ist durchaus zu hinterfragen, weshalb die zimbrische Enklave von Lusern als rein germanisches Sprachgebiet klassifiziert ist, während die benachbarten Sette Comuni als romanisch-germanisches Mischgebiet gelten. Auch die Kategorisierung von Sappada als rein germanisches Sprachgebiet dürfte Widerspruch hervorrufen.
Die Zuweisung eines Informanten zu einer bestimmten Sprachfamilie basiert im Fall der retrodigitalisierten Sprachatlas- und Wörterbuchdaten entweder auf der Ausrichtung der Publikation oder auf spezifizierten Angaben innerhalb der Publikation. In den allermeisten Fällen gehören sämtliche Informanten eines Atlas' oder eines Wörterbuchs genau einer Sprachfamilie an. Einzige Ausnahme ist der ASLEF, dessen Informanten unterschiedlichen Sprachfamilien angehören, die jeweils angegeben sind (ger: 2 | rom: 140 | sla: 7). VerbaAlpina nutzt für den Ausgleich von Dateninkonsistenzen das sog. Crowdsourcing-Verfahren. In diesem Fall legen die sog. "Crowder" ihre Sprachzugehörigkeit selbst fest.
Die Zuordnung eines morpholexikalischen Typs zu einer bestimmten Sprachfamilie ergibt sich unmittelbar aus der Sprachfamilienzugehörigkeit des Informanten, von dem der morpholexikalische Typ stammt. Eine abweichende Sprachfamilienzugehörigkeit zwischen Informant und seinen Äußerungen ist demnach nicht möglich.
Sosehr also die Zuweisung von Sprachfamilien auf einer der vorgestellten Ebenen im Einzelfall und speziell in der Nähe von Sprachgrenzen prekär sein mag, so nützlich ist diese Kategorisierung aufs Ganze gesehen und vor allem abseits der Übergangsregionen, also gleichsam im "Kernland" der jeweiligen Sprachfamilien als Variable, deren Ausprägung als Parameter bei Datenanalysen Berücksichtigung finden kann.
Unabhängig von der vorgeführten Kategorisierung spiegelt sich die Dimension des Sprachkontakts vor allem auf der Ebene der sogenannten Basistypen wieder, die im Rahmen der Identifizierung der morphosyntaktischen Typen durch VerbaAlpina vorgenommen wird. Das Konzept des Basistyps erlaubt die Identifizierung einer lexematischen Basis, wie sie auch bei der Feststellung eines Etymons erfolgt, lässt dabei aber die Details des Zusammenhangs zwischen dem morpholexikalischen Typ und der lexematischen Basis zunächst offen. Als Beispiel seien die folgenden morpholexikalischen Typen genannt, die alle die lexematische Basis baita enthalten:

Die hier gelisteten insgesamt zwölf morpholexikalischen Basistypen enthalten offenkundig die selbe lexematische Basis. Die Aufstellung lässt jedoch nicht erkennen, ob sich einzelne der Vertreter direkt aus den anderen entwickelt haben, oder ob alle der gelisteten morpholexikalischen Typen auf einen gemeinsamen Vorläufer zurückgehen.
Fragen dieser Art lassen sich also zumindest mit der aktuell vorliegenden Datenstruktur in der VerbaAlpina-Datenbank nicht beantworten. Auf der anderen Seite ist es mit Hilfe der Datenbank jedoch möglich, sämtliche Basistypen aufzufinden, die mit morpholexikalischen Typen aus mehr als einer Sprachfamilie verknüpft sind. Die entsprechende Abfrage lautet:
-- SQL-Statement: Zeige alle Basistypen, die morphlexikalischen Typen in
-- unterschiedlichen Sprachfamilien zugeordnet sind
select
a.Basistyp,
group_concat(distinct a.Sprache_Typ) as Sprachfamilien,
group_concat(distinct concat_ws(',',a.Typ, a.Sprache_Typ, a.Wortart, a.Affix, a.Genus) separator ' | ') as Morphtypen
from vap_ling_de a
where
a.Art_Typ like 'morph_typ'
and a.Basistyp is not null
group by a.Basistyp
having sprachfamilien like '%,%'
;
Das Ergebnis umfasst derzeit (Juni 2018) insgesamt 78 verschiedene Basistypen. Eine Gruppierung nach vorhandenen Sprachfamilienkonstellationen zeigt, dass zehn Basistypen in allen drei Sprachfamilien, 7 im germanischen und slavischen, 30 im romanischen und germanischen sowie 31 im romanischen und slavischen Sprachraum verbreitet sind.
Bei der Interpretation dieser und aller anderen errechneten Zahlen ist natürlich stets die Zufälligkeit des bislang von VerbaAlpina erfassten Materials und die bestehende Beschränkung auf bestimmte Konzeptdomänen zu bedenken.
Die strukturierte Erfassung des Datenmaterials erlaubt weitergehende Gruppierungen. So kann z.B. festgestellt werden, welche Konzepte mit den sprachraumübergreifenden Basistypen verbunden sind.
Manche der Elemente der obigen Auflistung mögen auf den ersten Blick irritieren. So erscheint z.B. der aus dem Lateinischen stammende Basistyp mulgere neben der Kategorie der TÄTIGKEITEN, der man dieses Verb primär zuordnen würde, auch in den Kategorien GEBÄUDE und GEFÄßE. Dies erklärt sich bisweilen durch die Einbindung der Einzelelemente in Mehrwortlexien wie hier z.B. in bidone a mungere (EIMER). mulgere steckt jedoch auch in einer germanischen Bezeichnung für den VIEHSTALL AUF DER ALM, melchster, was das Auftreten von mulgere in der Kategorie GEBÄUDE erklärt.
select a.Beleg, a.Art_Typ, a.Typ, a.Wortart, a.Affix, a.Genus, a.Referenz_Typ from vap_ling_de a group by a.Beleg, a.Art_Typ, a.Typ, a.Wortart, a.Affix, a.Genus, a.Referenz_Typ ;
select * from z_ling where id_instance in
(
select id_beleg from vap_ling_de
where basistyp in
(
select
a.Basistyp
-- group_concat(a.Beschreibung_Konzept separator ' | '),
-- group_concat(distinct a.Sprache_Typ) as Sprachfamilien,
-- group_concat(distinct concat_ws(',',a.Typ, a.Sprache_Typ, a.Wortart, a.Affix, a.Genus) separator ' | ') as Morphtypen
from vap_ling_de a
where
a.Art_Typ like 'morph_typ' collate utf8mb4_general_ci
and a.Basistyp is not null
group by a.Basistyp
-- , a.Beschreibung_Konzept
having group_concat(distinct a.Sprache_Typ) like 'rom,ger' or group_concat(distinct a.Sprache_Typ) like 'ger,rom'
)
and art_typ like 'morph_typ' collate utf8mb4_general_ci
group by gemeinde
)
group by id_community