


| Cette traduction est ajournée par rapport à la version originale de Krefeld/Lücke 2021; elle a été réalisée à l'occasion de la rencontre de Villejuif (Campus CNRS, 5 – 6 avril 2023), organisée par Nicolas Quint. |
|
Vue d'ensemble I. Remarque préliminaire : trois générations d'atlas linguistiques 1. données numériques structurées comme base de travail Appendice : Un exemple d'agrégation et d'imbrication des genres scientifiques |
I. Remarque préliminaire: Trois générations d'atlas linguistiques
Les principes présentés ci-dessous sont le résultat de 16 années de travail commun sur quatre projets géolinguistiques, qu'il faut d'abord positionner brièvement dans l'histoire des atlas linguistiques. Pour cela, il est utile de distinguer trois générations ; celles-ci se distinguent :
- dans la modélisation de la variation diatopique ;
- dans l'idée de la représentativité des données linguistiques en face de la selection des informateurs, des lieux et des procédures d'élicitation ;
- dans la conception et la réalisation médiatiques.
Le paradigme de la première génération est unidimensionnel et se base sur l'axiome de l'informateur unique représentatif ; l'œuvre prototypique, pionnière dans le domaine des langues romanes et même au-delà, est le AIS.
La deuxième génération est pluridimensionnelle et étudie la variation diatopique dans plusieurs dimensions ; il fait que les données linguistiques dépendent de l'informateur individuel ainsi que du type d'élicitation devient le centre méthodologique du travail. Ce paradigme a été fondé de manière exemplaire par le ADDU.
Dans la troisième génération, on travaille systématiquement avec la technologie web ; dans la conception et la réalisation, les aspects linguistiques et médiatiques sont indissociables. L'émergence de ce paradigme n'est donc pas exclusivement scientifique, car elle est conditionnée par le progrès des technologies de l'information (cf. Communication scientifique sur le web).
La métaphore de la génération est fondée sur l'échelonnement historique des trois types ; elle n'est toutefois pas idéale dans la mesure où, même aujourd'hui – dans la phase de la troisième génération – des projets ont été et sont toujours lancés en suivant les règles des deux générations précédentes (par exemple, l'atlas en ligne VIVALDI suit le paradigme de la première génération). Les méthodes de travail numériques peuvent répondre aux exigences des trois générations, mais les objectifs de la troisième génération ne peuvent être atteints que par des moyens numériques. Notre propre travail reflète le passage de la deuxième à la troisième génération, à laquelle se réfèrent les principes formulés ici. Ils ont un caractère général, indépendamment des exigences thématiques spécifiques des projets particuliers, mais ils sont illustrés justement par des projets particuliers, notamment notre projet actuellement en cours VerbaAlpina .
| 2. Generation | 3. Generation | |
| AsiCa | → | Asica 2.0 |
| ASD | ||
| Metropolitalia | ||
| VerbaAlpina | ||
| les projets géolinguistique des auteurs | ||
II. Huit principes pour la troisième génération
1. Des données numériques structurées comme base de travail
Le terme 'numérisation' est loin d'être univoque ; pour différencier les exigences, nous distinguons plusieurs degrés de numérisation. Pour l'analyse et la visualisation électronique des données sous une forme telle que celle présentée par VerbaAlpina, il faut des données structurées correspondant au degré D3 au sens du schéma suivant:
| degré de numérisation |
annot., alargiss., liens | export des données | |||
| D3 | tabelle | db csv |
texte électronique structuré | → | XML SQL CSV txt ... HTML PS papier |
| D2 ↑ | fichier texte | txt doc |
texte électronique linéarisé | ← praat | |
| D1 ↑ | doc. scanné | jpg | code binaire | wav, mp3 | |
| D0 ↑ | papier | écriture/image | audio |
La base D3 est toutefois exigeante et, selon la source, il existe différentes manières, plus ou moins complexes, d'élever les données à ce niveau ; parfois, ce n'est même pas possible.
L'exigence est double : les données doivent être numériques *et* structurées. La dimension purement technique de la numérisation est relativement facile à gérer :
- texte imprimé sur papier ⇒ OCR ou dactylographie ⇒ texte électronique
- Fichier audio ⇒ ASR (automatic speech recognition ; STT : speech to text) ou dactylographie (Praat) ⇒ texte électronique (ASR jusqu'ici utilisable uniquement pour la langue standard)
Particulièrement important : la structuration des données
Structuration signifie toujours : production de métadonnées (variables "type", "source", "lieu", "signification" ...) et leur attribution aux données (en tant que valeurs de caractéristiques).
| données analogique | données numériques | données numériques et structurées | ||||||||
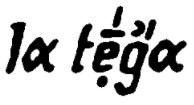 |
tˈeːʥɑ |
|
attestation: AIS 1192 (LA CASCINA DI MONTAGNA), lieu 5 (Ems) (VA-Beleg S293; Discover@UB)
| structuré | ASLEF-tableaux | VerbaAlpina |
| non/part. structuré | VALTS | Idiotikon, WBOe |
| analogue | numérique |
Pour des structurations existantes, une restructuration est souvent nécessaire : Structure A ⇒ Structure B
Selon le degré de structuration et de numérisation, la saisie des données s'avère plus ou moins complexe. Les APIs sont idéales pour l'échange de données, la mise en réseau et la réutilisation.. Ce n'est que peu à peu que les API sont mises en œuvre dans les ressources lexicographiques en ligne. Un exemple est le "Digitales Wörterbuch der Deutschen Sprache" (dictionnaire numérique de la langue allemande) (DWDS; API: https://www.dwds.de/d/api), qui, en tant que source, ne joue toutefois qu'un rôle secondaire pour VerbaAlpina. VerbaAlpina a mis en place une API pour sa base de données (https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=8844&db=211).
Quelques exemples de sources saisies par VA, dans le contexte de la numérisation et de la structuration
Effort en partie réduit: les tableaux de l'ASLEF

Tableau 45 du ASLEF. Sous chaque concept sont listées les désignations spécifiques aux localités. Les chiffres devant les documents individuels représentent les localités respectives. Les listes de ce type peuvent, du moins en théorie, être saisies de manière au moins partiellement automatisée par des procédés OCR. Il faut cependant toujours se demander si le développement d'un tel procédé apporte effectivement un gain de temps. VerbaAlpina a jusqu'à présent renoncé à de tels développements.
Exemple d'atlas linguistique : Vorarlberger Sprachatlas mit Einschluss des Fürstentums Liechtenstein (VALTS; Atlas linguistique du Vorarlberg avec inclusion de la Principauté du Liechtenstein)
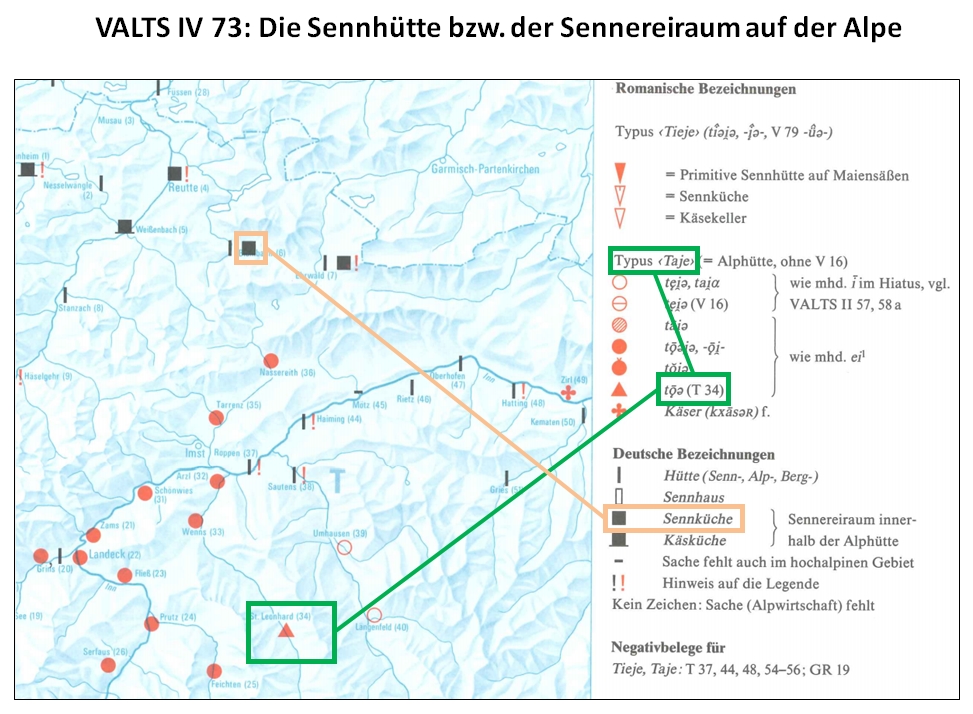
carte IV 73 du VALTS: données analogiques mixtes (types et attestations)
Exemple de dictionnaire : Schweizerdeutsches Idiotikon (Vocabulaire de l'allemand suisse)

Comme dans le cas du VALTS, il s'agit ici d'un mélange d'entités différentes qui ne peut pas être saisi par une machine. Ici aussi, la saisie des données n'est possible que grâce à l'intervention de personnel et est donc coûteuse.
Un exemple positif est le WBOe (Dictionnaire des parlers bavarois de l'Autriche)

Ce projet doit faire face au fardeau de ses débuts précoces. La saisie des données était purement analogique et le matériel collecté se présente sous la forme d'environ 3,6 millions de fiches. Entre-temps, le matériel est structuré dans des fichiers XML qui servent de base pour la publication en ligne dans le cadre du LIÖ ("Lexikalischen Informationssystems Österreich"; voir https://www.oeaw.ac.at/de/acdh/sprachwissenschaft/projekte/wboe/materialbasis, "Digitalisierung des Handzettelkatalogs"). On peut se demander seulement pourquoi les fichiers XML ne semblent pas être mis à la disposition du public dans leur totalité. VerbaAlpina évite le format XML car, selon notre estimation et notre expérience, il est compliqué à convertir et à analyser. En interne, VerbaAlpina utilise exclusivement le format de données relationnel et organise donc son matériel linguistique dans des tableaux. L'exportation au format XML est toutefois possible (exemple: entrées VA pour le concept C1, CHALET de la version VA 211).
Outils développés par VerbaAlpina pour la numérisation et la saisie structurée des données
Pour le 'passage' au niveau D3, il peut être nécessaire de développer des outils appropriés. VerbaAlpina a développé à cet objectif deux outils principaux, implémentés sous forme de plugins WordPress :
L'outil de transcription (Link)
L'outil de transcription de VerbaAlpina
L'outil de transcription gère la saisie des données en indiquant au transcripteur (généralement des étudiants assistants) quelles entrées d'une carte linguistique particulière doivent être saisies. De cette manière, le risque d'erreur est réduit et une approche systématique est favorisée. Par défaut, le système ne présente que les nouvelles entrées qui n'ont pas encore été saisies. Il peut toutefois être utilisé de manière ciblée pour saisir à nouveau des données déjà saisies et identifier ainsi les transcriptions potentiellement erronées. La transcription s'effectue selon les règles du Beta code, qui permet de saisir des systèmes d'écriture complexes à l'aide d'un clavier standard. Le bêta-code est très facile à apprendre et n'exige pas une connaissance approfondie du système d'écriture transcrite.
L'outil pour regrouper les attestations par types morpho-lexicaux (Link)

L'outil de VerbaAlpina qui sert à attribuer des types aux données des sources analogiques. L'exemple montre dans la case supérieure, marquée en rouge, une série d'attestations transcrites de la carte AIS 1218_1,'il siero del formaggio ; il siero della ricotta – petit-lait', qui peuvent être attribuées au type lexical 'lacciata' (f.) (roa.).
L'outil de regrouper par types permet aux collaborateurs (généralement des linguistes diplômés) d'attribuer plus facilement à un même type lexical plusieurs attestations répertoriées sur une carte linguistique et de les grouper ainsi comme de variantes de ce même type lexical. L'outil permet également de créer de nouveaux types lexicaux ou de modifier ceux qui existent déjà.
Géoréférencement
Un attribut obligatoire de toutes les données linguistiques est le géoréférencement, afin de pouvoir créer des cartes virtuelles (voir ci-dessous) ; dans le cas de nombreux dictionnaires dialectaux, les coordonnées correspondantes peuvent être attribuées aux lieux documentés. Les grands dictionnaires suisses en sont de très bons exemples, le Glossaire des patois de la Suisse romande (GPSR), le Vocabolario dei dialetti della Svizzera italiana (VSI) et le Dicziunari Rumantsch Grischun (DRG). Les données ont été relevées à la manière d'un atlas dans un réseau de lieux bien identifiés, comme le montre la carte suivante:
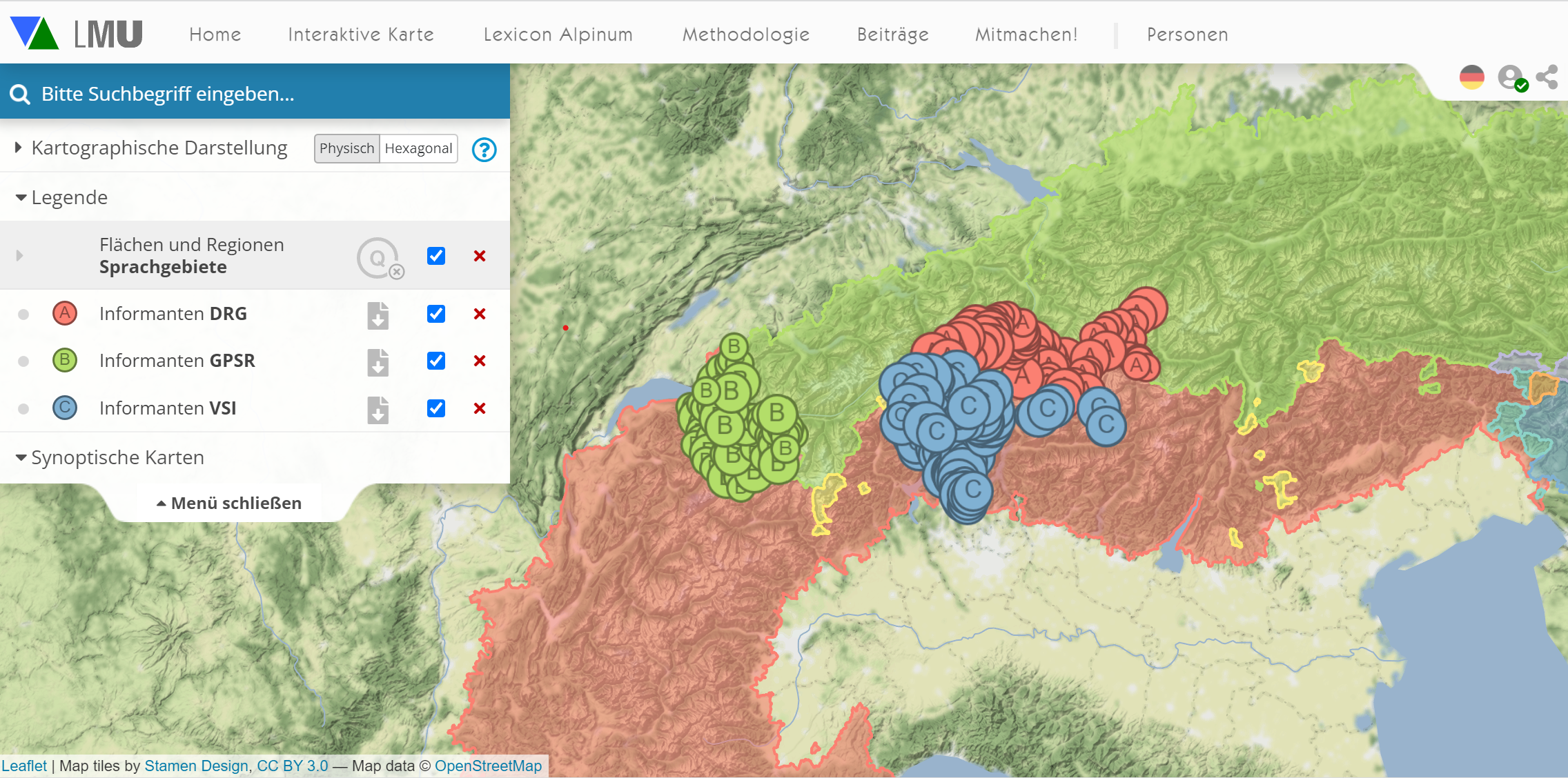
Réseaux locaux du DRG, du GPSR et du VSI (original interactif)
Pour VerbaAlpina, l'unité géographique de référence est la commune politique. Les données correspondantes ont été collectées peu après le début du projet et ne sont pas mises à jour ; elles constituent un cadre de référence géographique stable. Par défaut, les attestations linguistiques sont référées à la grille des communes politiques. Le géoréférencement se fait par l'enregistrement de coordonnées WGS84. Pour chaque commune, la base de données de VerbaAlpina contient le tracé des frontières communales, ainsi que des coordonnées de points qui indiquent le centre géométrique des territoires communaux. Il est également possible de localiser des documents linguistiques au mètre près, indépendamment de la géometrie communale.
2. Référence des données linguistiques aux notices d'autorité non linguistiques
Les données linguistiques et leurs catégories descriptives ont toujours été liées à la réalité extralinguistique, même si c'est de manière plus ou moins explicite. Entre-temps, la référence peut être opérationnalisée au sens technique, car des notices d'autorité persistantes sont disponibles.
Les identificateurs du projet Wikidata possèdent un grand potentiel qui est loin d'être exploité. Ils offrent un niveau de référence très différencié et fiable qui, d'une part, sert de base à la saisie complémentaire et comparative de plusieurs langues et, d'autre part, fournit des filtres de recherche appropriés pour la consultation des désignations respectives des différentes langues. La sémasiologie et l'onomasiologie sont ainsi nettement séparées. Voir la recherche de concepts :
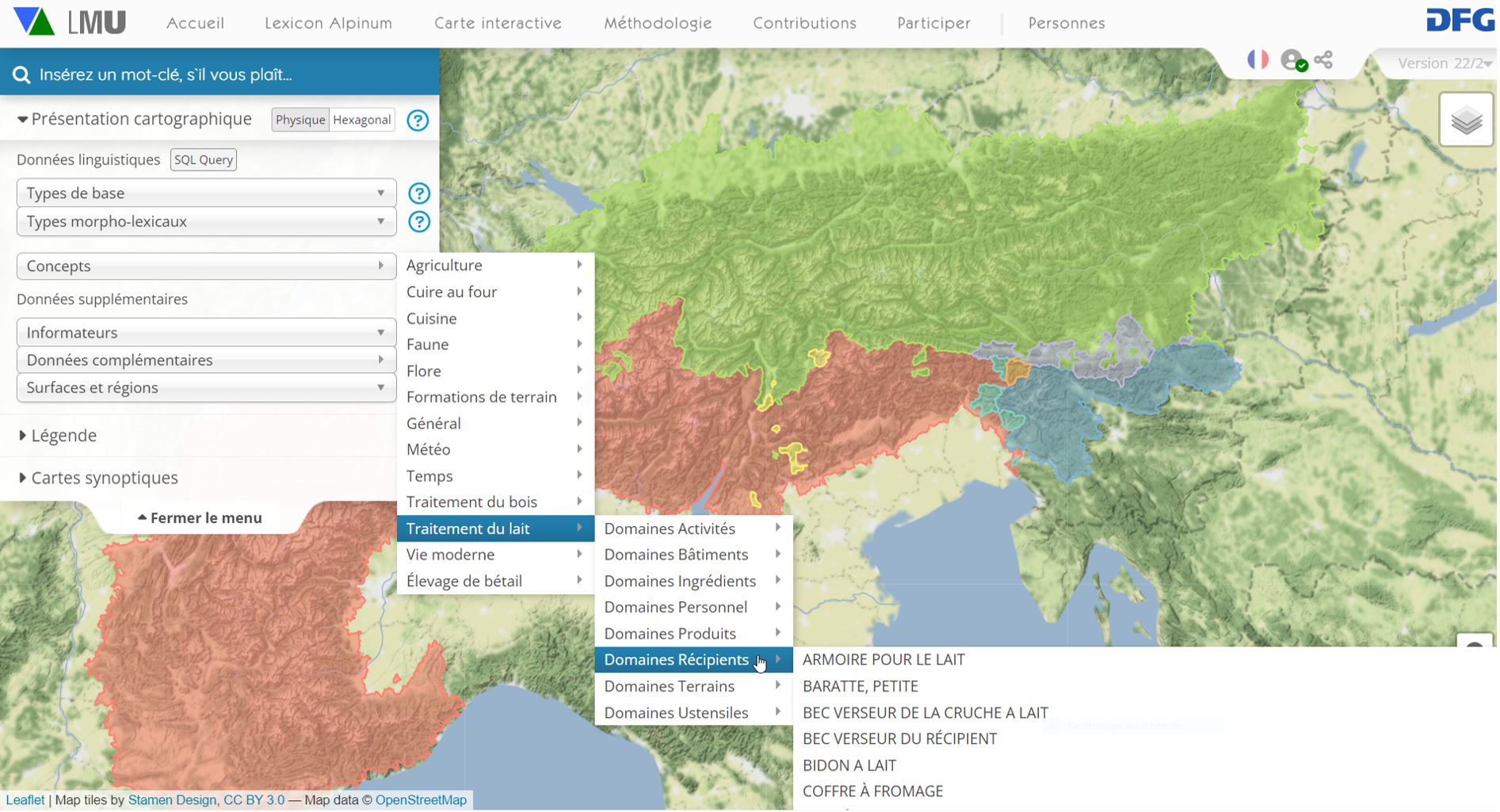
Recherche de concept onomasiologique dans VA
completer Wikidata. VerbaAlpina, par exemple, est identifiée de manière univoque par le Q-ID Q66817486 (https://www.wikidata.org/wiki/Q66817486).
Outre les notices d'autorité de Wikidata, VerbaAlpina intègre également les identificateurs du projet Geonames, spécialisé dans les entités géographiques. L'accès aux pages de notices d'autorité externes est possible à partir de la carte en ligne de VerbaAlpina; il suffit de cliquer sur un symbole de la carte et de consulter la fenêtre qui s'ouvre:
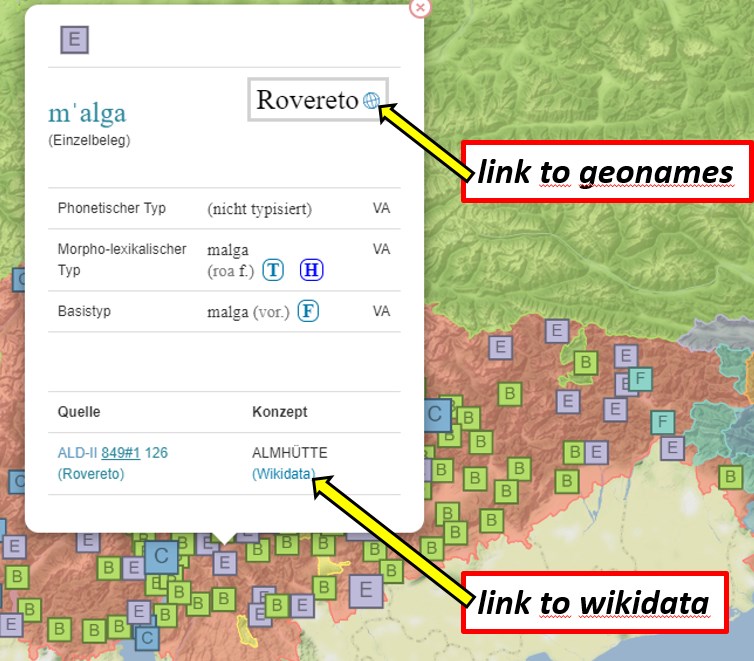
Intégration de notices d'autorité externes dans une fenêtre de la carte en ligne
La connexion à des systèmes de notices d'autorité externes est importante, notamment pour trouver les données VerbaAlpina depuis l'extérieur. Jusqu'à présent, les QID de Wikidata ne sont reliés que de façon interne aux identifiants propres de VerbaAlpina. Il est prévu d'exporter les données VA dans Wikidata et de leur attribuer la 'propriété' spécifique (VerbaAlpina ID). De cette manière, les données de VerbaAlpina feront partie du web sémantique. Les projets "Kaiserhof", une base de données qui saisit les courtisans des Habsbourg, et BMLO, le "Bayerisches Musikerlexikon Online" (dictionnaire bavarois des musiciens en ligne), également situés à l'ITG, en fournissent le modèle conceptuel. Les identificateurs de ces deux bases de données peuvent être consultés dans Wikidata à l'aide du langage de requête SPARQL. Nous envisageons la même chose pour VerbaAlpina.
Il est également prévu d'exporter les données linguistiques compilées par VA vers la section lexicographique de Wikidata; exemple lexèmes qui désignent une couleurs).
3. Gestion des données de recherche (FDM)
Orientation selon les critères FAIR
L'acronyme FAIR a été formé à partir des lettres initiales de quatre critères directeurs, dénommés en anglais findable 'trouvable', accessible, interoperable et reusable 'réutilisable' ; leur mise en œuvre a déjà été décrite à plusieurs reprises et de manière détaillée (voir Lücke, Krefeld/Lücke 2020 et Krefeld 2018 g).
Une orientation selon les critères FAIR implique le respect des initiatives libre acces (Open Access) et code source ouvert (Open Source) et le renoncement au développement et à l'utilisation d'outils propriétaires.
Contact avec des institutions qui mettent en œuvre la gestion des données de recherche
La durabilité dépend en grande partie du fait que des institutions ayant des perspectives d'existence à durée indéterminée assument la responsabilité de la conservation des résultats des projets. C'est pourquoi VerbaAlpina a cherché à entrer en contact avec la bibliothèque universitaire de la LMU depuis un certain temps déjà. En principe, les bibliothèques semblent être les partenaires idéaux pour la gestion des données de recherche, essentiellement pour deux raisons :
- La conservation des acquis scientifiques a toujours été la mission centrale des bibliothèques.
- Les bibliothèques d'État et universitaires ont en général une perspective d'existence à durée indéterminée.
VerbaAlpina est également un projet pilote dans le cadre du projet "eHumanities – interdisciplinär", financé par le gouvernement bavarois, qui se consacre aux défis de la gestion des données de recherche dans le contexte de la numérisation toujours en cours.
En collaboration avec la bibliothèque universitaire de la LMU, il a été possible de transférer deux versions sélectionnées des données de VerbaAlpina (19/1 et 19/2) dans le dépôt informatique de la bibliothèque universitaire. Les données ont également été intégrées dans le portail de recherche "Discover", où il est désormais possible d'y accéder sous différentes formes. Il est ainsi possible de référencer ou de télécharger des versions complètes. De plus, il est possible d'adresser des documents individuels, des types morpho-lexicaux ou des localités avec le matériel linguistique qui leur est associé. Le système permet de générer des DOI spécifiques pour des paquets de données sélectionnés, un référencement univoque est en outre possible grâce à des identificateurs persistants propres à la BU.
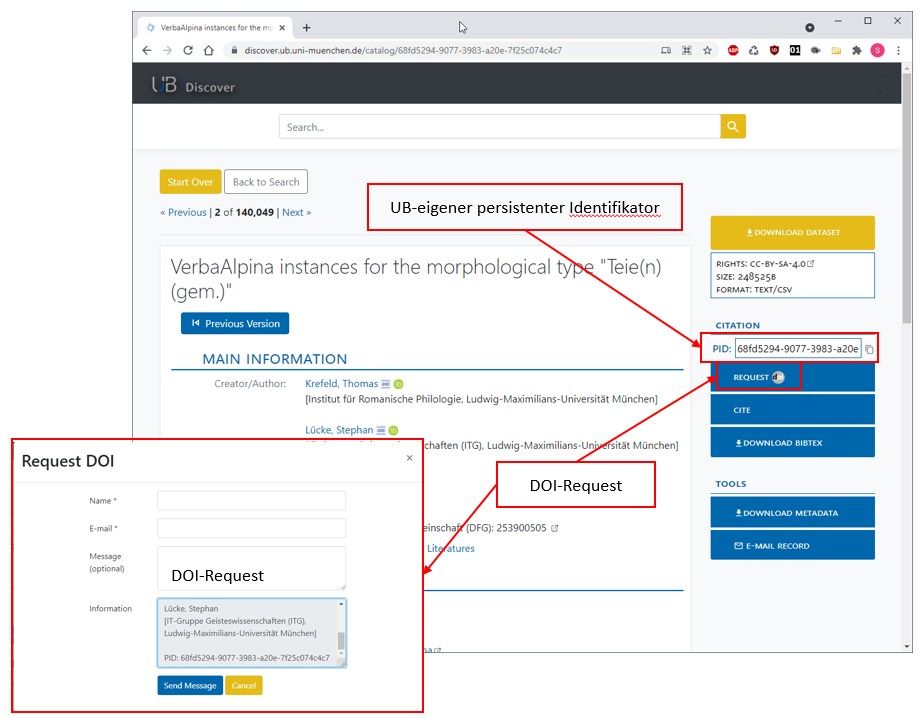
Portail "Discover" (BU de la LMU). Le système permet entre autres de créer un DOI qui référence sur un type morpho-lexikal de VerbaAlpina
4. Adressage et engagement interactif d'un large public (crowdsourcing)
L'accessibilité générale des contenus publiés sur Internet a pour conséquence de s'adresser à un très large public qui appartient à des univers de connaissances très différents. En font partie – du moins potentiellement – les spécialistes de la linguistique, les amateurs intéressés et les communautés de locuteurs, y compris certains informateurs. Il va de soi que toutes les informations ne présentent pas le même intérêt pour tous les utilisateurs, de sorte qu'il ne semble pas nécessaire de tout exprimer dans un langage courant compréhensible au maximum. Cela ne serait pas non plus compatible avec la précision conceptuelle nécessaire, qui ne peut pas se passer de terminologie. Toutefois, la compréhension de l'interface est facilitée par l'utilisation de nombreuses infobulles, c'est-à-dire des fenêtres d'information qui s'ouvrent lorsque l'on déplace la flèche de la souris dessus. Voci un exemple:
Exemple d'infobulle (original interactif)
- Chacun peut apporter des formes linguistiques, qu'il soit expert ou non, et il est également possible de compléter des concepts manquants (voir https://www.verba-alpina.gwi.uni-muenchen.de/fr/en/?page_id=1741).
- Les utilisateurs qui fournissent des preuves/concepts peuvent s'enregistrer et rester ainsi accessibles pour le projet ; cela est utile pour d'éventuelles questions. #Combien de % le font ?
- Chaque utilisateur peut générer de manière interactive des cartes synoptiques en combinant n'importe quel contenu, les fixer et les proposer pour la publication. Ces propositions ne sont toutefois pas automatiquement mises à disposition de tous, mais examinées au préalable par les responsables du projet.
- Une prise de contact directe est possible via les médias sociaux du projet ainsi que via des adresses e-mail (voir Home).
- Les projets scientifiques Partenaires peuvent fournir autant de données pertinentes qu'ils le souhaitent et les héberger dans leur propre base de données, qui fait partie de l'architecture du projet.
5. Des bases de données ouvertes et dynamiques
La possibilité d'enrichir continuellement les données disponibles présuppose que l'on travaille en principe avec des bases de données ouvertes et dynamiques. L'idée idéale, c'est-à-dire illusoire, d'exhaustivité empirique devient ainsi obsolète. Toutefois, dans un souci de transparence et de vérifiabilité, il est absolument nécessaire de garantir une fiabilité empirique afin que les résultats des projets puissent également être cités. Cette condition fondamentale est remplie par une gestion des versions régulière des données. D'un point de vue purement technique, le versionnement est réalisé par la création d'une copie de la base de données. La copie reçoit un nom qui renvoie à la date de création (191 : milieu de l'année 2019 ; 192 : fin de l'année 2019). La copie de la base de données est figée, il n'est plus possible de modifier les données qu'elle contient. Sur le portail du projet, une liste déroulante permet de passer d'une version à l'autre :
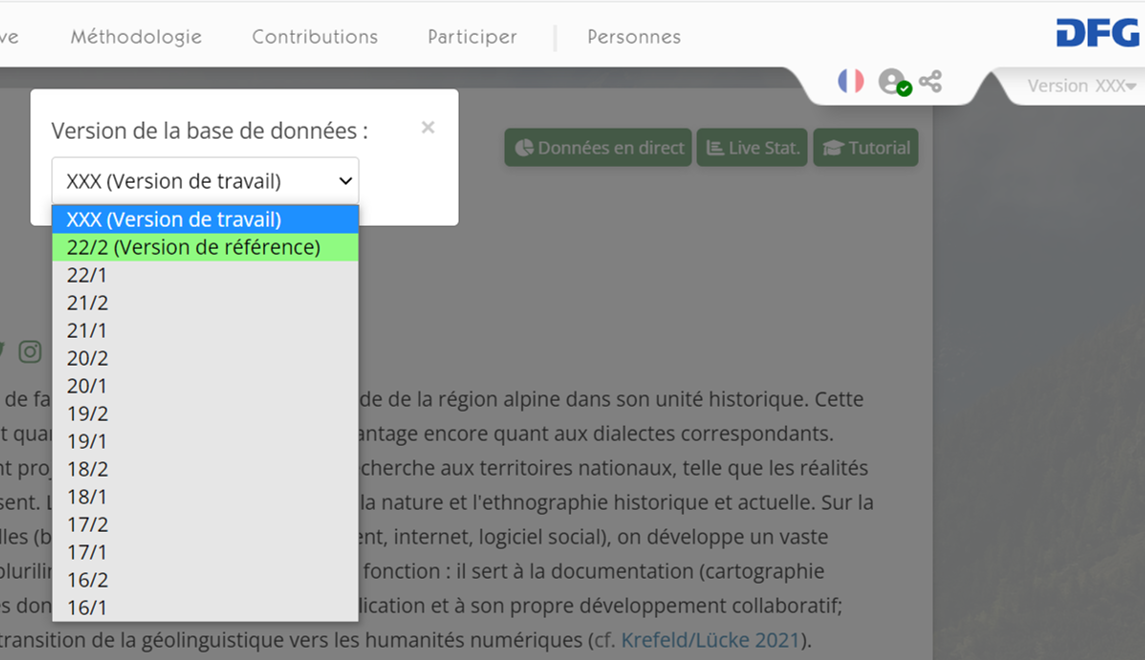
Les versions de VA disponibles en avril 2023
Le numéro de version fait également partie de la plupart des URL qui renvoient aux ressources VerbaAlpina. A titre d'exemple, on peut citer l'URL qui renvoie au type morpho-lexical L2599/tegia (roa f.) dans le Lexicon Alpinum, version VA 211 :
Un relevé de toutes les versions disponibles à ce jour se trouve sur la page d'accueil de VerbaAlpina sous le bouton "Timeline". Un clic sur l'une des images de version ouvre une fenêtre qui montre la progression du projet (bouton 'Détails) dans la version correspondante :
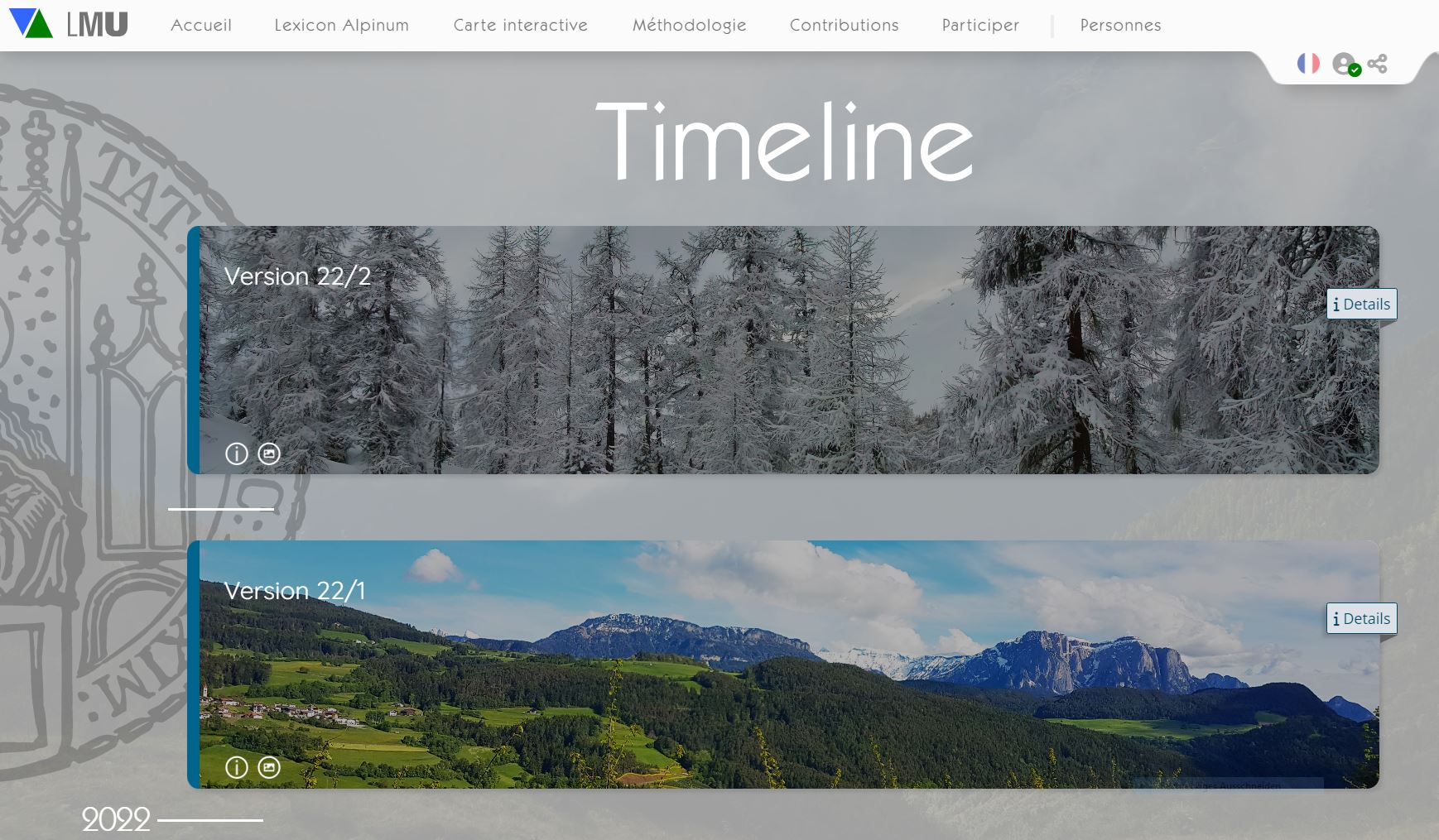
La 'Timeline' donne des informations sur l'avancement du projet
Prochainement, la timeline contiendra également d'autres informations sur la progression de la version selctionnée par rapport aux versions précédentes. Il s'agira surtout de réalisations non quantifiables, telles que les textes analytiques publiés, le développement de nouveaux outils ou des changements dans le design ou la maniabilité.
6. Cartographie virtuelle sur base géoréférencée
Dans le sens d'une exploitation cohérente de la technologie web, on renonce à utiliser des cartes graphiques. La cartographie purement virtuelle présente plusieurs avantages ; elle permet de proposer à l'utilisateur des surfaces cartographiques très différentes (avec/sans relief, avec/sans inscription, carte/image satellite, etc.) en option :
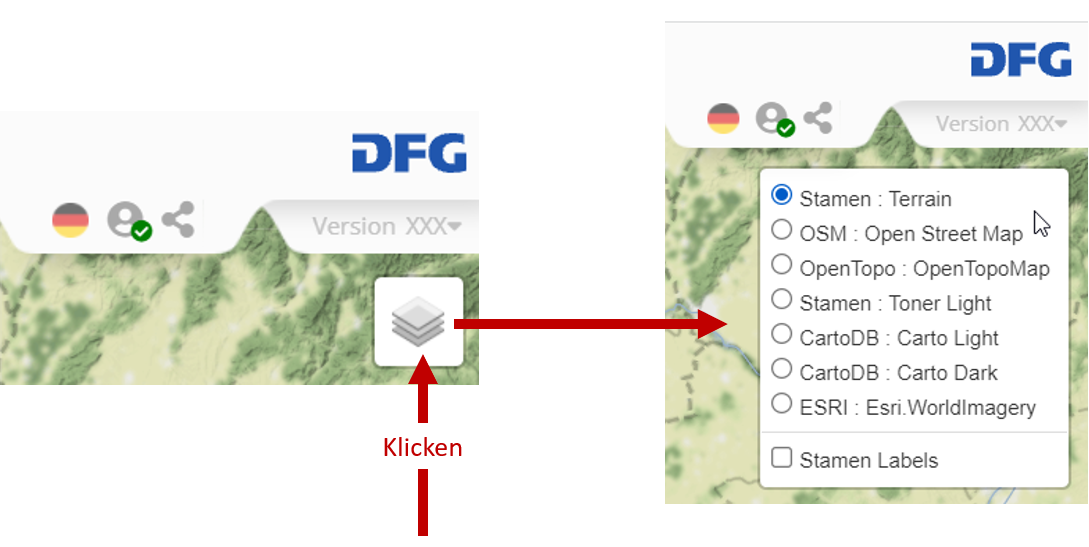
surfaces cartographiques optionnelles (original interactif)
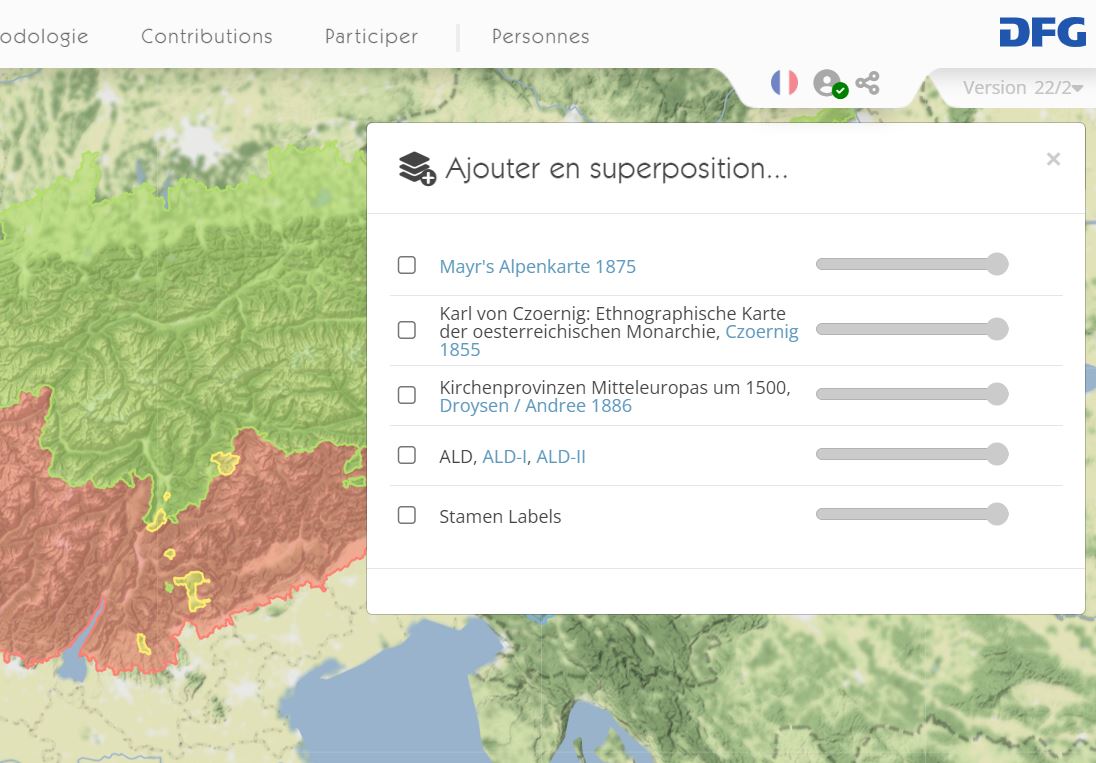
Trois cartes historiques en superposition (original interactif)
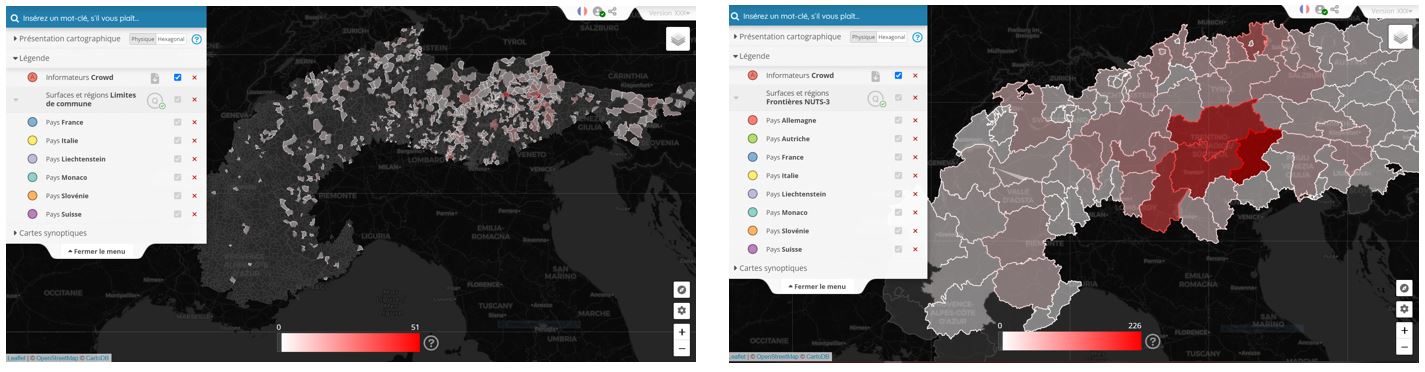
Visualisation optionnelle avec référence aux territoires communaux (à gauche, original interactif) et aux régions NUTS 3 (à droite, original interactif)
7. Possibilité d'inclure des données contextuelles non linguistiques
Pour l'interprétation des constellations géolinguistiques, il est indispensable de disposer d'informations démographiques et historiques sur le lieu attesté ; VA a donc lié les 5771 noms de communes de l'espace alpin aux entrées correspondantes du service geonames.org. Dans le cas de la ville de Garmisch-Partenkirchen, ce service nous amène des informations multiples d'ordre topographique, administratif et encyclopédique (voir le symbole de Wikipedia):
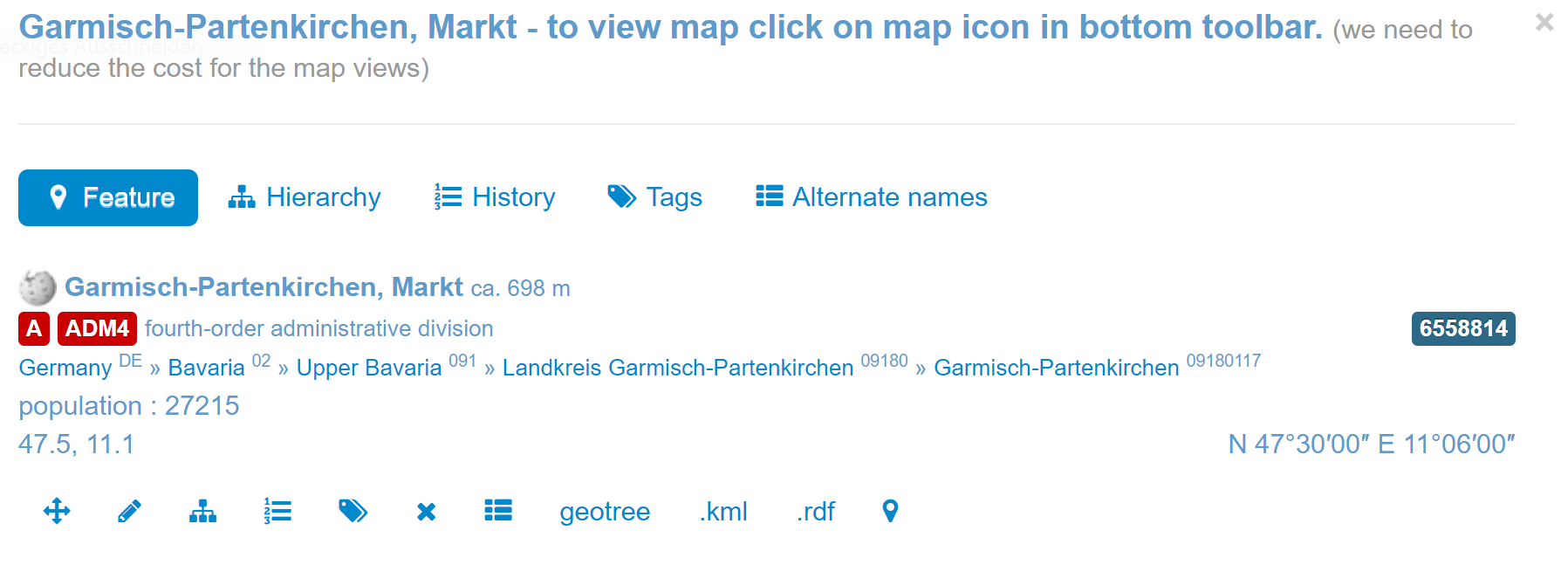
Informations accessibles via geonames.org (exemple de Garmisch-Partenkirchen – source)
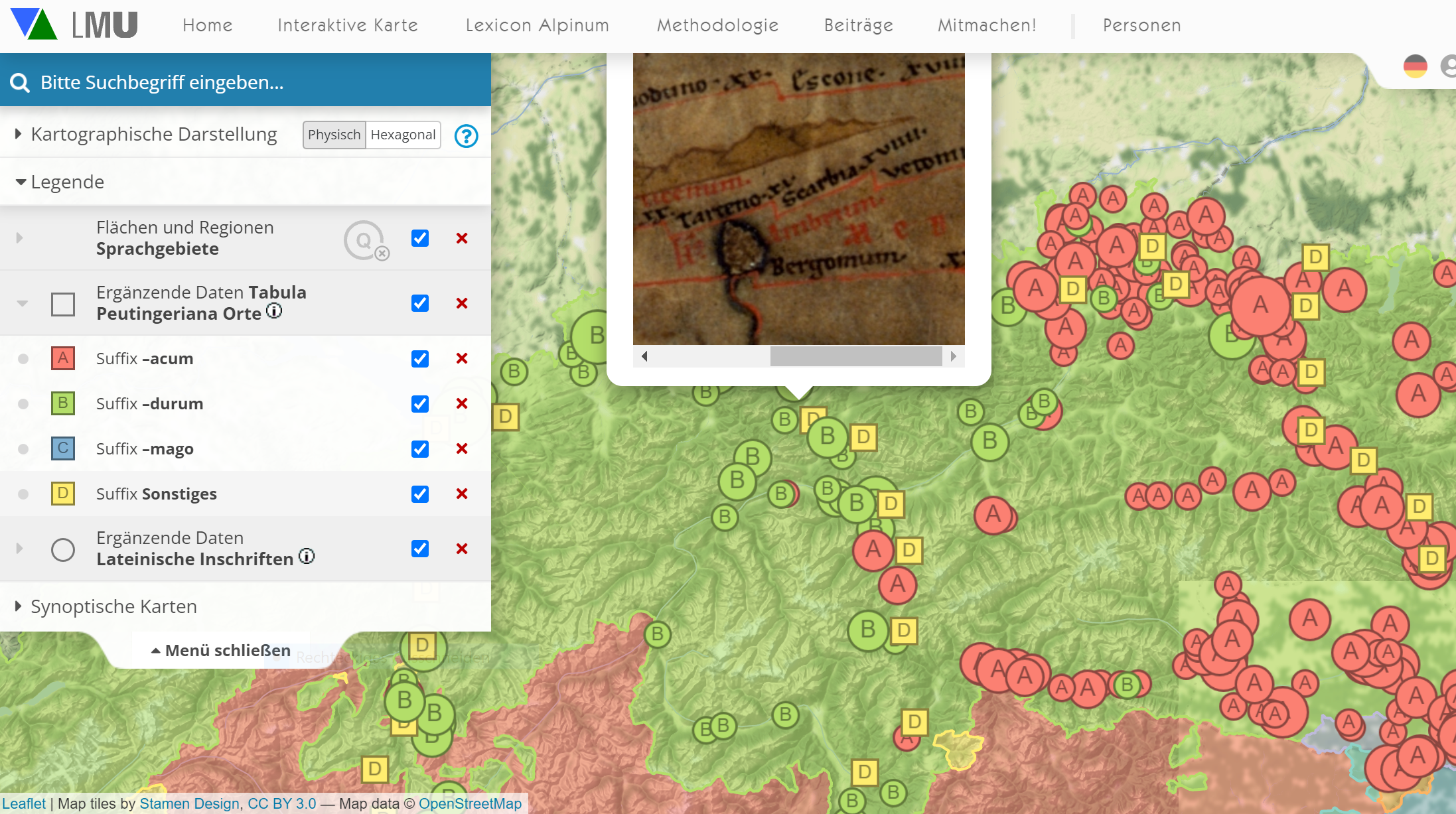
Attestation de 'Parten(kirchen)' (Tarteno ⇒ <P>arteno) sur la 'Tabula Peutingeriana' (original interactif )
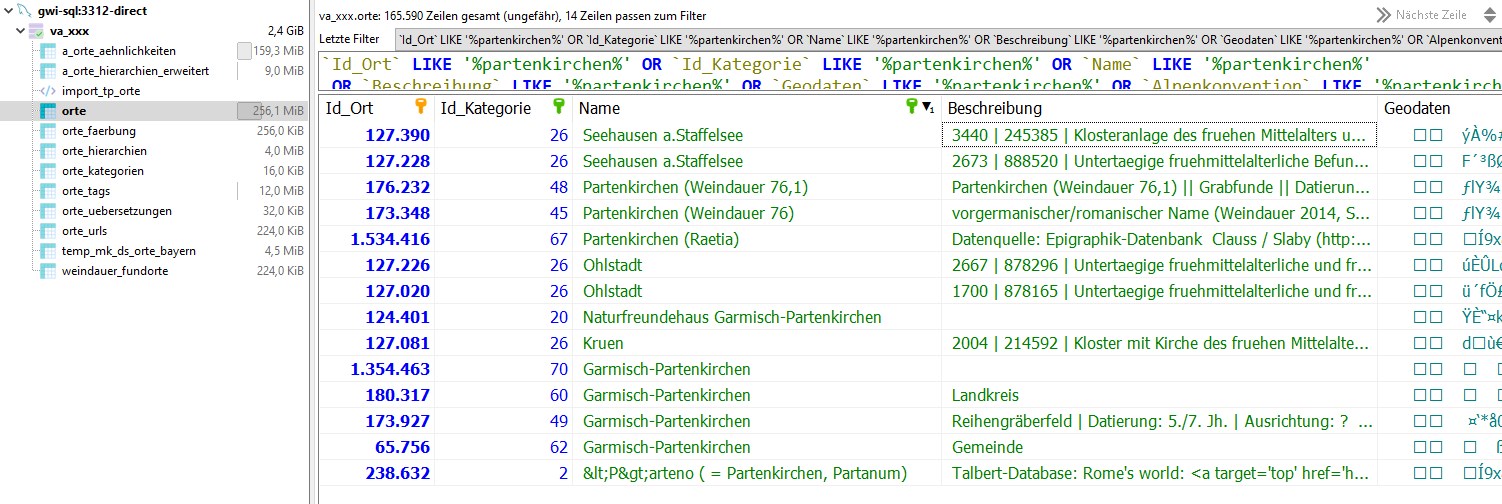
Extrait du tableau 'lieus' de la base de donées VA avec des entrées liées avec 'Partenkirchen'
Le tableau "Lieux" contient actuellement environ 175000 entrées et a un volume de plus de 250 MB. Les entrées de ce tableau sont classées dans 47 catégories. Outre les données de la Tabula Peutingeriana, il s'agit par exemple des catégories suivantes :
monastères (1317) ; champs_de_fouilles_lombards (120) ; communautés walser (77) ; inscriptions rhétiques (36) ; ...
8. Incorporation de l'atlas, du dictionnaire et du texte analytique
Les genres traditionnels dans lesquels les résultats de la recherche géolinguistique ont été publiés (monographie locale, atlas, dictionnaire, corpus) poursuivent chacun des objectifs spécifiques et doivent donc être considérés comme complémentaires. Dans le cadre des médias numériques, il n'y a toutefois plus de raison de les séparer catégoriquement. C'est justement en raison de leur complémentarité qu'il est logique de les relier entre eux de manière organique, comme cela a été entrepris dans VerbaAlpina. Le site web du projet fournit sous l'onglet méthodologie des discussions théoriques sur des concepts linguistiques et informatiques centraux ; cette composante conceptuelle est étroitement liée aux deux fonctionnalités principales, à la PAGE NOT FOUND! et au Lexicon Alpinum. Ces deux composantes ont à leur tour été conçues en quelque sorte en symbiose, puisque chaque entrée du Lexicon peut être visualisée sur une carte en cliquant, et depuis la carte, on accède en cliquant aux entrées correspondantes du Lexicon :
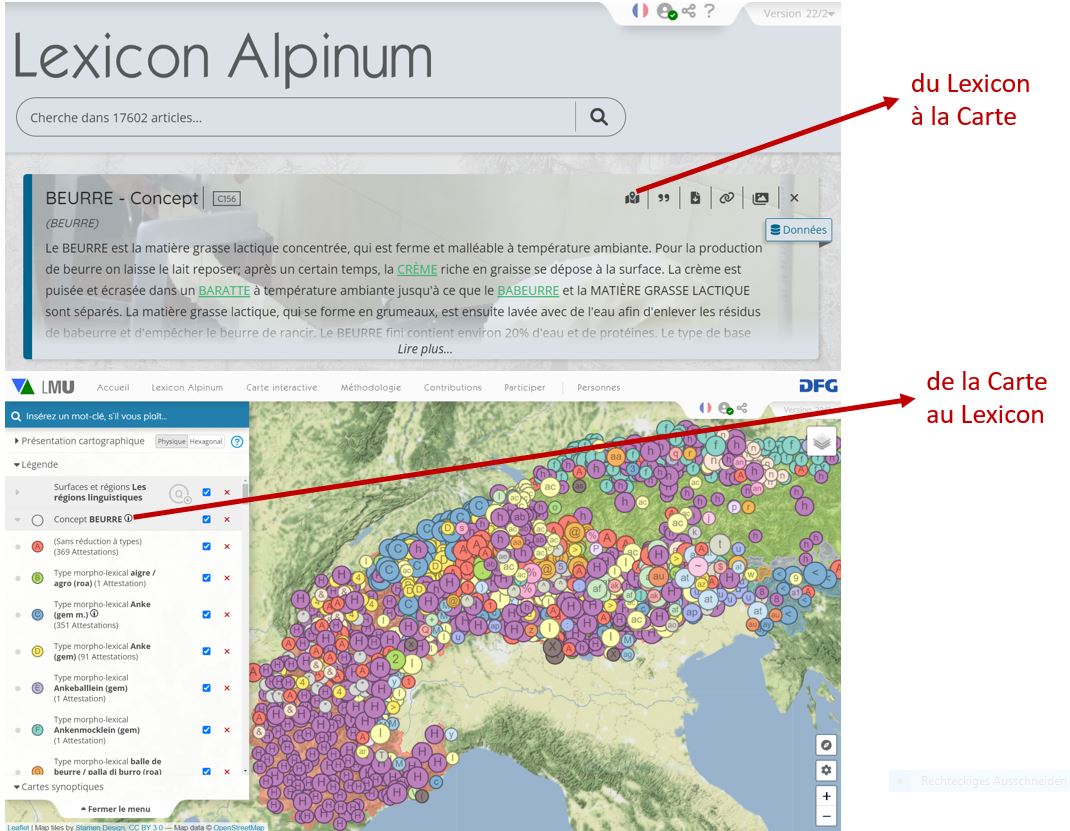
Imbrication d'informations cartographiques et lexicographiques
Enfin, le corpus de données peut également être interrogé directement à partir du texte discursif ou de la carte interactive. Les utilisateurs ont la possibilité d'envoyer des requêtes individuelles à la base de données à partir de la carte interactive en cliquant sur le bouton 'SQL Query' et de consulter ainsi les résultats sur la carte même.
L'utilisation de la fonction SQL nécessite des connaissances du langage d'interrogation SQL. Les informations nécessaires sur la structure et le contenu du tableau interrogeable peuvent être obtenues en cliquant sur le petit point d'interrogation à côté du mot-clé "WHERE" :
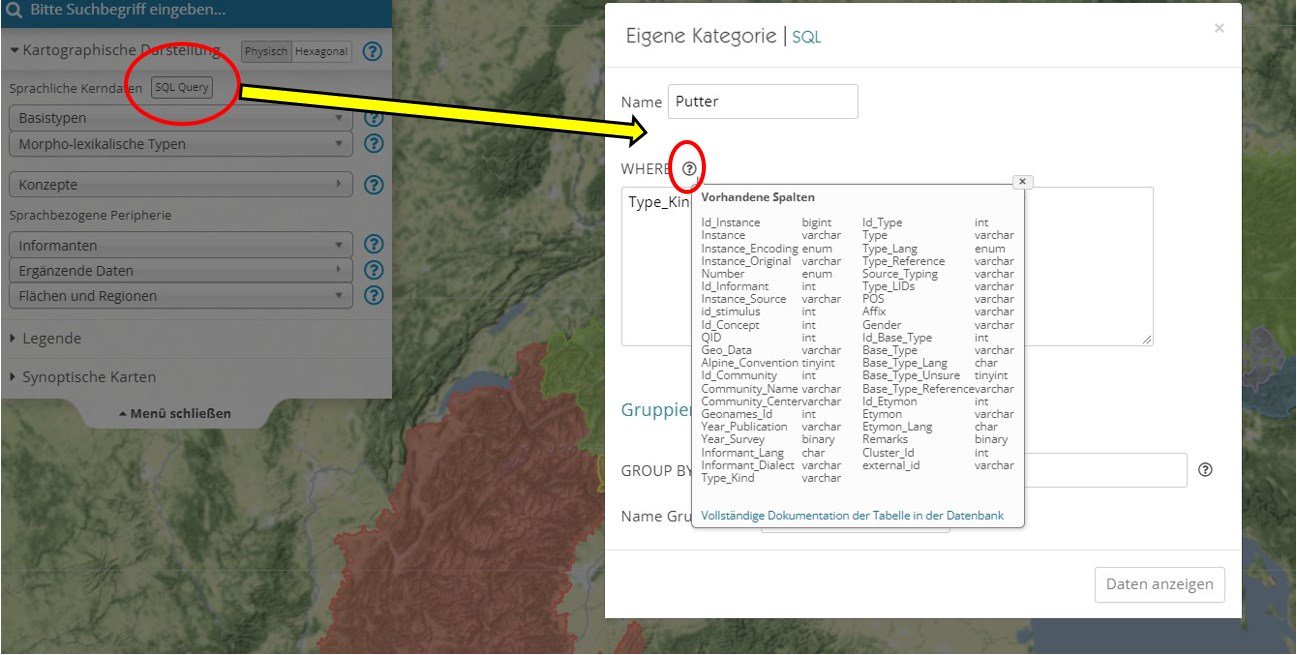
Fenêtres et cases pour requêtes individuelles. Une info-bulle présente les champs du tableau et les catégories de donnée.
Un lien en bleu en bas de l'info-bulle renvoie à une page spécifique contenant des informations détaillées sur les champs de la base de données et leur contenu.
Exemple : attestations avec le type de base "butyru(m)" :
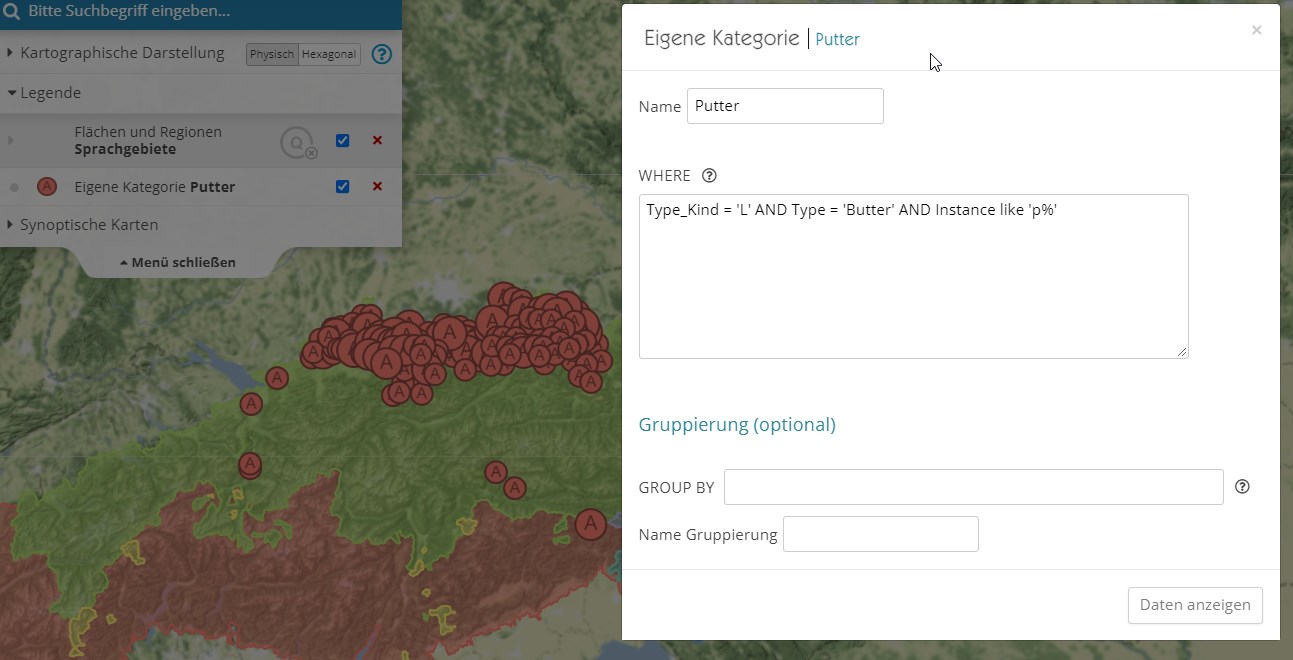
Cartographie des attestations du type lexical Butter avec p-initial. Un clic droit sur la légende permet de modifier la requête SQL-Abfrage (boîte de dialogue droite).
Un exemple d'agrégation et d'imbrication des genres scientifiques
Enfin, l'agrégation de différentes types de sources et l'imbrication des genres seront illustrées de manière un peu plus détaillée. Le point de départ de la présentation est l'article chaschöl du dictionnaire de référence du roman des Grisons DRG (Link). Les formes qui y sont mentionnées apparaissent sur la carte chaschöl 'fromage' en association avec celles d'autres sources, comme le montre le marquage représentatif des lieux du VSI.:
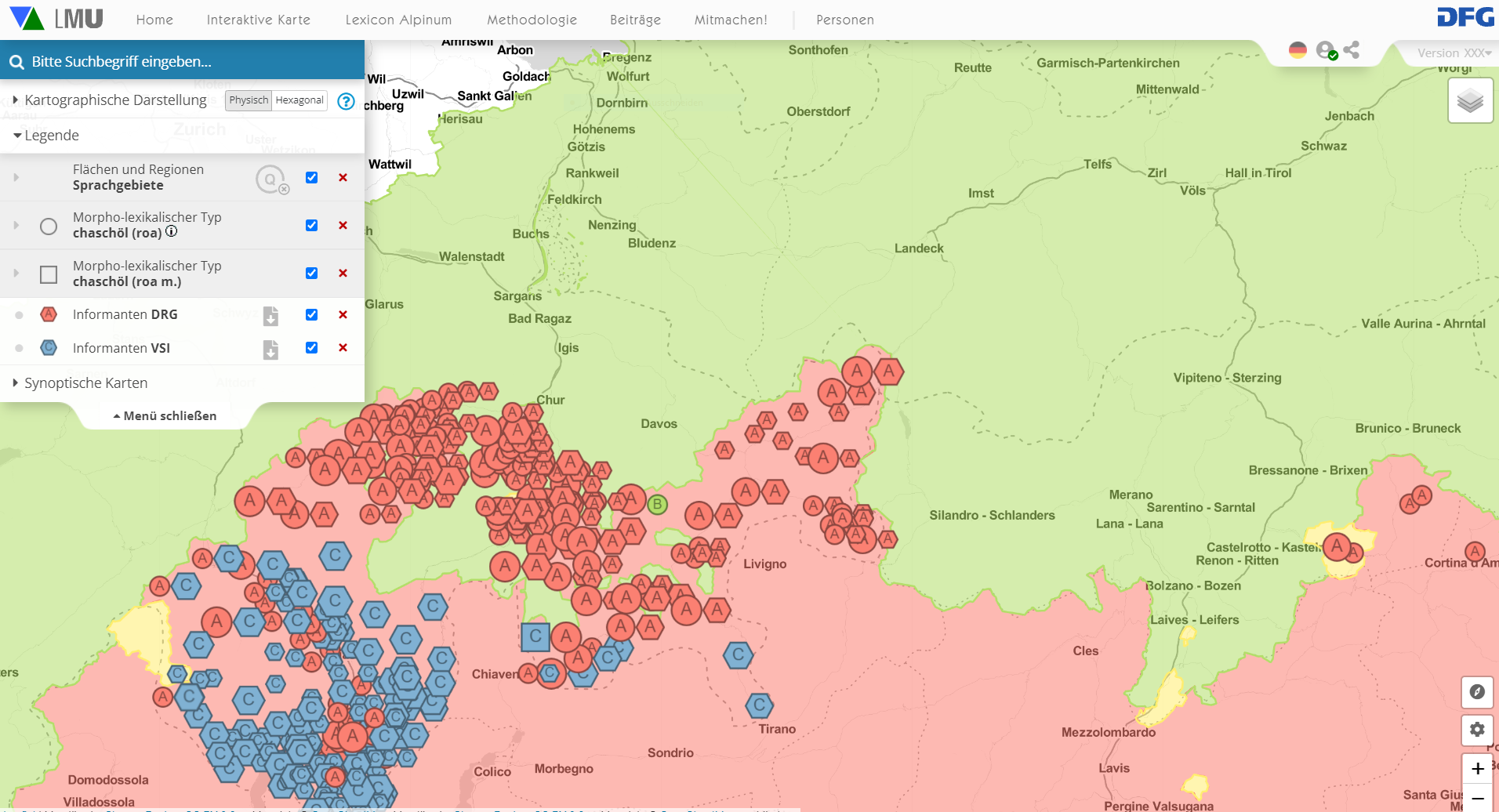
Diffusion du typ chaschöl (< lat. caseolus) selon deux sources agrégées, interaktives Original
Bibliographie
- ADDU = Thun, Harald / Elizaincín, Adolfo (2000-): Atlas lingüístico diatópico y diastrático del Uruguay, Kiel, Westensee
- AIS = Jaberg, Karl / Jud, Jakob (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz, Zofingen, vol. 1-7
- ASD = Krefeld, Thomas / Lücke, Stephan / Mages, Emma (2016): Audioatlas Siebenbürgisch-Sächsischer Dialekte , München, Ludwig-Maximilians-Universität. Link
- ASLEF = Pellegrini, Giovan Battista (1974-1986): Atlante storico-linguistico-etnografico friulano, Padova, vol. 1-6
- AsiCa = Krefeld, Thomas / Lücke, Stephan (2006-2017): Atlante sintattico della Calabria, München. Link
- Asica 2.0 = Krefeld, Thomas / Lücke, Stephan (2019): Atlante sintattico della Calabria. Rielaborato tecnicamenta da Veronika Gacia e Tobias Englmeier, München. Link
- DRG = De Planta, Robert/ Melcher, Florian/ Pult, Chasper/ Giger, Felix (1938ff.): Dicziunari Rumantsch grischun, Chur, Inst. dal Dicziunari Rumantsch Grischun. Link
- DWDS = Berlin-Brandenburgische Akademie der Wissenschaften (Hrsg.) (2004-): Das Digitale Wörterbuch der deutschen Sprache, Berlin. Link
- GPSR = Gauchat, Louis (Hrsg.) (1924ff.): Glossaire des patois de la Suisse romande, Genève [u.a.], Droz [u.a.]
- Idiotikon = (1881 ff.): Schweizerisches Idiotikon. Schweizerdeutsches Wörterbuch, Basel. Link
- Krefeld 2018 g = Krefeld, Thomas (2018): I principi FAIR nel progetto VerbaAlpina, ossia il trasferimento della geolinguistica alle Digital Humanities. Link
- Krefeld/Lücke 2020 = Krefeld, Thomas / Lücke, Stephan (2020): 54 Monate VerbaAlpina – auf dem Weg zur FAIRness, in: Ladinia, vol. XLIII, 139-156. Link
- Krefeld/Lücke 2021 = Krefeld, Thomas / Lücke, Stephan (2021): (Unsere) Prinzipien der virtuellen Geolinguistik. Link
- Metropolitalia = Krefeld, Thomas / Lücke, Stephan / Bry, François (2010-2013): Metropolitalia. Social Language Tagging, München. Link
- VALTS = Gabriel, Eugen (1985-2004): Vorarlberger Sprachatlas mit Einschluss des Fürstentums Liechtenstein, Westtirols und des Allgäus , vol. 1-5, Bregenz, vol. 1-5, Vorarlberger Landesbibliothek
- VIVALDI = Kattenbusch, Dieter/ Tosques, Fabio (1998-2016): VIVALDI: Vivaio Acustico delle Lingue e dei Dialetti d'Italia. Aktustischer Sprachatlas der Dialekte und Minderheitensprachen Italiens., Berlin, Humboldt-Universität Berlin, Institut für Romanistik. Link
- VSI = Sganzini, Silvio (1952ff): Vocabolario dei dialetti della Svizzera italiana, Lugano, Tipografia la Commerciale
- VerbaAlpina = Krefeld, Thomas / Lücke, Stephan (2014-): VerbaAlpina. Der alpine Kulturraum im Spiegel seiner Mehrsprachigkeit, München. Link
- WBOe = Bauer, Werner/ Kranzmayer, Eberhard. Institut für österreichische Dialekt- und Namenlexika (Hrsg.) (1970–): Wörterbuch der bairischen Mundarten in Österreich, Wien, Verl. der Österr. Akad. der Wiss.