


| Dieser Beitrag wurde für den Workshop Neue Wege der romanischen Geolinguistik Vers. 2.0 (2021) verfasst (Schneefernerhaus, 4.-5.11.2021). Für die Einladung mitzumachen danken wir Joachim Steffen (Augsburg). |
| Übersicht I. Vorgeschichte: Drei Generationen von Sprachatlanten II. Unsere 8 Prinzipien für die dritte Generation 1. Strukturierte digitale Daten als Arbeitsgrundlage Appendix: Ein Beispiel für Aggregation und Gattungsverschränkung |
I. Vorgeschichte: Drei Generationen von Sprachatlanten
Die im Folgenden vorgestellten Prinzipien sind das Ergebnis von 16 Jahren gemeinsamer Arbeit an vier geolinguistischen Projekten, die vorab kurz in der Geschichte der Sprachatlanten positioniert werden sollen. Dafür ist es hilfreich, drei Generationen zu unterscheiden; sie unterscheiden sich:
- in der Modellierung räumlicher Variation;
- im Verständnis der Repräsentativität sprachlicher Daten vor dem Hintergrund der selektierten Informanten, Orte und Elizitationsverfahren;
- in der medialen Konzeption und Realisierung.
Das Paradigma der ersten Generation ist eindimensional und dem Axiom des repräsentativen Einzelinformanten verpflichtet; das prototypische, in der Romanistik und auch darüber hinaus wegweisende Werk ist der AIS.
Die zweite Generation ist pluridimensional und untersucht die räumliche Variation in mehreren Dimensionen; die Abhängigkeit der sprachlichen Daten vom Sprecher und von der Art der Elizitation rückt ins methodologische Zentrum der Arbeit. Exemplarisch begründet wurde dieses Paradigma durch den ADDU.
In der dritten Generation wird konsequent mit Webtechnologie gearbeitet; in der Konzeption und und Durchführung sind sprachwissenschaftliche und mediale Aspekt untrennbar miteinander verflochten. Die Entstehung dieses Paradigmas ist also nicht nur wissenschaftsintern zu sehen, da ihre Voraussetzungen durch den informationstechnischen Fortschritt geliefert wurden (vgl. Wissenschaftskommunikation im Web).
Die Generationsmetapher ist in der historischen Staffelung der drei Typen begründet; sie ist allerdings insofern nicht ideal, als auch heute – in der Phase der dritten Generation – durchaus noch Projekte auf den Weg gebracht wurden und werden, die den Regeln der beiden vorhergehenden Generationen folgen (z.B. folgt der Online-Atlas VIVALDI dem Paradigma der 1. Generation). Den Anforderungen aller drei Generationen können digitale Arbeitsweisen entsprechen, allerdings kann man den Zielen der dritten Generation ausschließlich mit digitalen Mitteln gerecht werden. Unsere eigene Arbeit reflektiert den Übergang von der zweiten zur dritten Generation, auf die sich die hier formulierten Prinzipien beziehen. Sie zielen auf Generelles, unabhängig von den speziellen thematischen Anforderungen der Einzelprojekte, werden jedoch an Einzelprojekten illustriert, vor allem am aktuell noch laufenden Projekt VerbaAlpina.
| 2. Generation | 3. Generation | |
| AsiCa | → | Asica 2.0 |
| ASD | ||
| Metropolitalia | ||
| VerbaAlpina | ||
| geolinguistische Projekte der Autoren | ||
II. Prinzipien für die dritte Generation
1. Strukturierte digitale Daten als Arbeitsgrundlage
Der Ausdruck ‘Digitalisierung’ ist keineswegs eindeutig; um die Anforderungen zu differenzieren, unterscheiden wir mehrere Digitalisierungsgrade. Für die elektronische Datenanalyse und Visualisierung in einer Form, wie VerbaAlpina sie präsentiert, sind strukturierte Daten erforderlich, die der Stufe D3 im Sinne des folgenden Schemas entsprechen:
| Grad der Digitalisierung |
Etikett., Erweit., Verknüpf. | Daten- export |
|||
| D3 | Tabelle | db csv |
strukturierter elektronischer Text | → | XML SQL CSV txt ... HTML PS Papier |
| D2 ↑ | Textdatei | txt doc |
linearisierter elektronischer Text | ← praat | |
| D1 ↑ | Scan | jpg | binärer Code | wav, mp3 | |
| D0 ↑ | Papier | Schrift/Bild | Audio |
Die Grundlage D3 ist jedoch anspruchsvoll, und je nach Quelle gibt es unterschiedliche, vor allem unterschiedlich aufwändige Arten, wie die Daten überhaupt erst auf dieses Niveau gehoben werden können; gelegentlich ist das auch nicht möglich.
Die Anforderung ist eine doppelte: Die Daten müssen digital *und* strukturiert sein. Mit der rein technischen Dimension der Digitalisierung ist vergleichsweise leicht umzugehen:
- auf Papier gedruckter Text ⇒ OCR oder Abtippen ⇒ elektronischer Text
- Audiodatei ⇒ ASR (automatic speech recognition; STT: speech to text) oder abtippen (Praat) ⇒ elektronischer Text (ASR bislang nur bei Standardsprache brauchbar)
Besonders wichtig: Die Datenstrukturierung
Strukturierung bedeutet stets: Erzeugung von Metadaten (Merkmale "Typ", "Quelle", "Ort", "Bedeutung" ...) und deren Zuordnung zu den Daten (als Merkmalsausprägungen)
| Daten analog | Daten digital | Daten digital und strukturiert | ||||||||
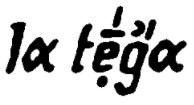 |
tˈeːʥɑ |
|
Beleg: AIS 1192 (LA CASCINA DI MONTAGNA), Ort 5 (Ems) (VA-Beleg S293; Discover@UB)
| strukturiert | ASLEF-Tafeln | VerbaAlpina |
| nicht/teil- strukturiert | VALTS | Idiotikon, WBOe |
| analog | digital |
Bei gegebenen Strukturierungen ist häufig eine Umstrukturierung erforderlich: Struktur A ⇒ Struktur B
Je nach Strukturierungs- und Digitalisierungsgrad gestaltet sich die Datenerfassung mehr oder weniger aufwendig. Optimal für Datenaustausch, Vernetzung und Nachnutzung sind sog. APIs. Erst allmählich werden APIs in lexikographischen online-Ressourcen implementiert. Ein Beispiel ist das "Digitale Wörterbuch der Deutschen Sprache" (DWDS; API: https://www.dwds.de/d/api), das allerdings für VerbaAlpina als Quelle nur eine Nebenrolle spielt. VerbaAlpina hat für seinen Datenbestand eine API eingerichtet (https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=8844&db=211).
Einige Beispiele für Quellen, die von VA erfasst werden, vor dem Hintergrund von Digitalisierung und Strukturierung
Teilweise geringer Aufwand: ASLEF-Tafeln

Tafel 45 des ASLEF. Unter jedem Konzept sind die ortstypischen Bezeichnungen gelistet. Die Zahlen vor den Einzelbelegen stehen für die jeweiligen Ortschaften.
Beispiel für einen Sprachatlas: Vorarlberger Sprachatlas mit Einschluss des Fürstentums Liechtenstein (VALTS)
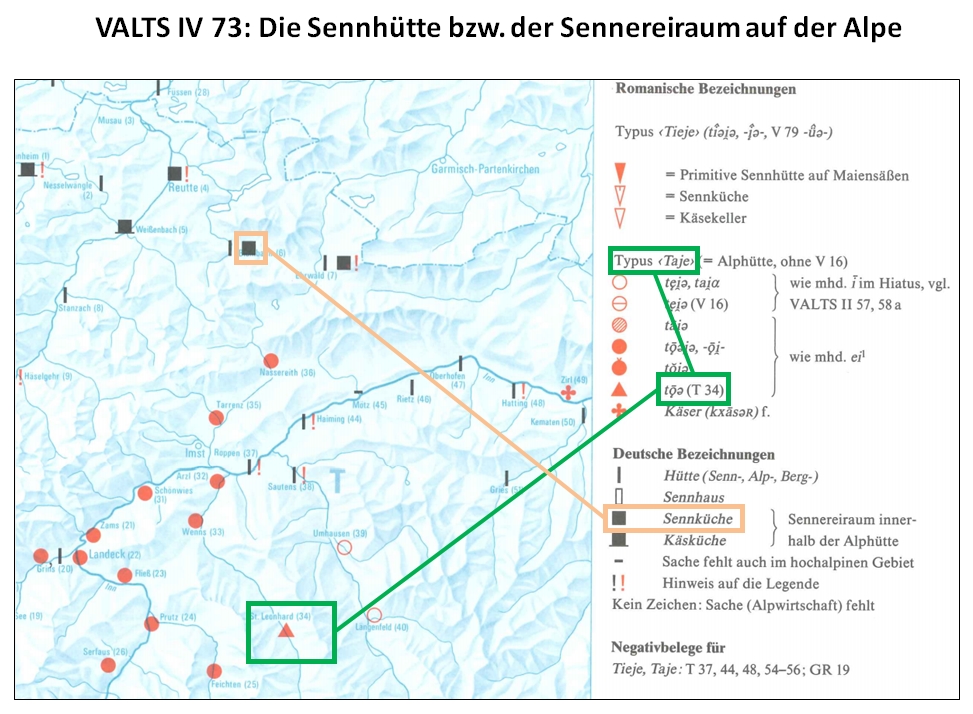
Karte IV 73 des VALTS: Mischung
Beispiel für ein Wörterbuch: Schweizerdeutsches Idiotikon

Ähnlich wie im Fall des VALTS liegt hier eine maschinell nicht erfassbare Mischung unterschiedlicher Entitäten vor. Auch hier ist die Datenerfassung nur durch Personaleinsatz möglich und entsprechend aufwendig.
Ein positives Beispiel ist das WBOe.
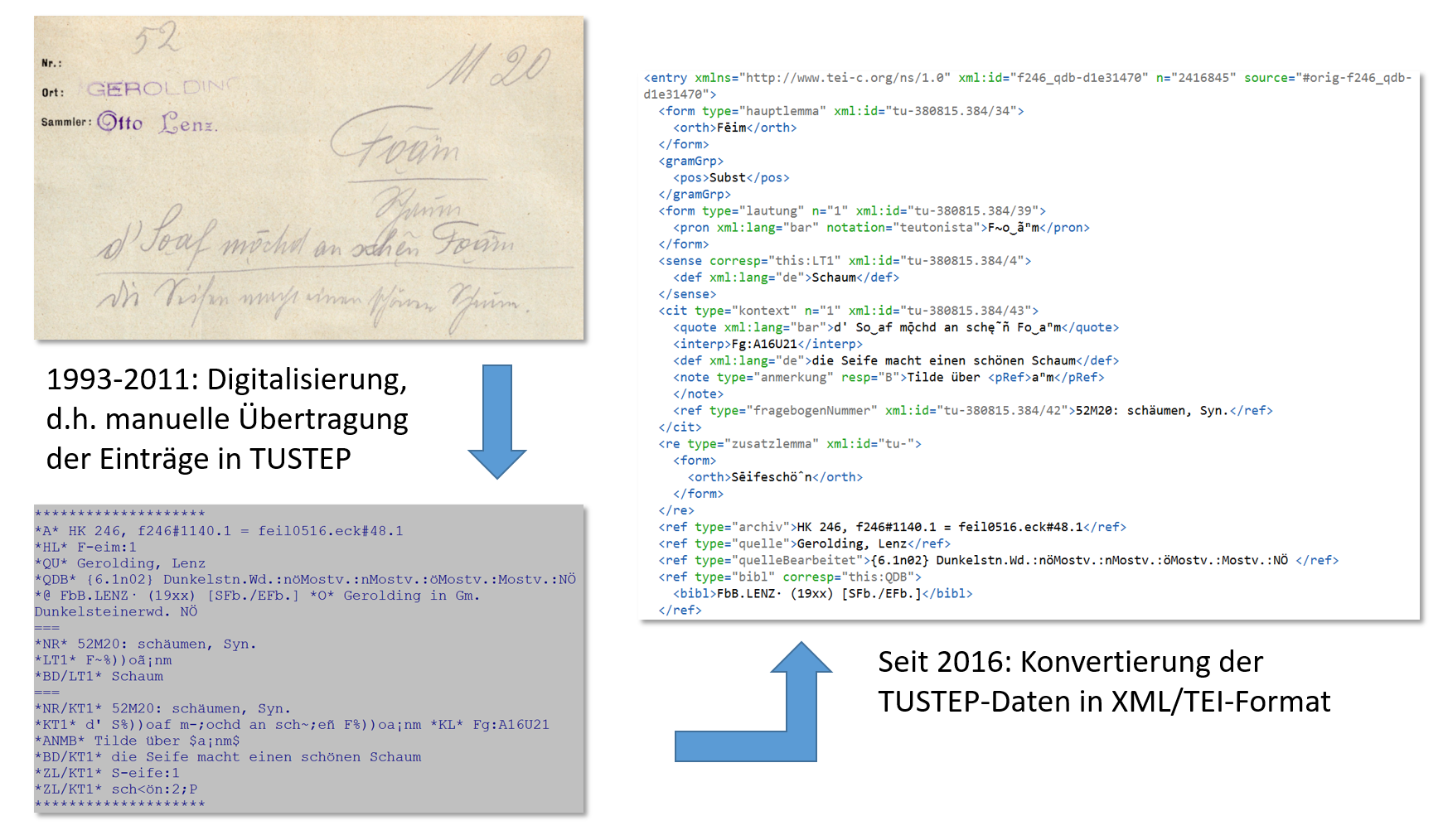
Digitalisierung der analogen Handzettel durch das Projekt WBOE. Nach einer Zwischenstation mit TUSTEP liegt das Material jetzt im XML-Format vor.
Dieses Projekt hat mit der Last seiner frühen Entstehungszeit zu kämpfen. Die Datenerfassung erfolgte rein analog, das gesammelte Material liegt in Form von ca. 3,6 Millionen Handzetteln vor. Mittlerweile liegt das Material strukturiert in XML-Dateien vor, die wiederum gleichsam als Backend für die online-Publikation im Rahmen des "Lexikalischen Informationssystems Österreich", LIÖ, dient (s. https://www.oeaw.ac.at/de/acdh/sprachwissenschaft/projekte/wboe/materialbasis, "Digitalisierung des Handzettelkatalogs"). Zu fragen bleibt allenfalls, warum die XML-Dateien anscheinend nicht in ihrer Gesamtheit der Öffentlichkeit zur Verfügung gestellt werden. VerbaAlpina vermeidet das XML-Format, da es nach unserer Einschätzung und Erfahrung umständlich bei Konvertierung und Analyse ist. VerbaAlpina nutzt intern ausschließlich das relationale Datenformat, organisiert sein Sprachmaterial also in Tabellen. Ein Export im XML-Format ist jedoch möglich (Beispiel: VA-Einträge zum Konzept C1, SENNHÜTTE der VA-Version 211).
Von VerbaAlpina entwickelte Tools zur Digitalisierung und strukturierten Datenerfassung
Für die ‘Hebung’ auf D3 müssen u.U. erst geeignete Tools entwickelt werden. VerbaAlpina hat zu diesem Zweck im wesentlichen zwei, als WordPress-Plugins implementierte, Hilfsmittel entwickelt:
Das Transkriptionstool (Link)
Das Transkriptionstool von VerbaAlpina
Das Transkriptionstool steuert die Datenerfassung, indem es dem Transkriptor (meist Hilfskräfte) vorgibt, welche Eintragungen auf einer Sprachatlaskarte jeweils erfasst werden sollen. Auf diese Weise wird die Fehleranfälligkeit reduziert und ein systematisches Vorgehen begünstigt. In der Grundeinstellung präsentiert das System nur neue, noch nicht erfasste Eintragungen. Es kann jedoch gezielt auch zur erneuten Eingabe bereits erfasster Daten genutzt werden, um auf diese Weise potentiell fehlerhafte Transkriptionen zu identifizieren. Die Transkription erfolgt nach den Regeln des sog. Betacodes, der die Eingabe auch komplexer Schriftsysteme unter Verwendung einer Standardtastatur erlaubt. Der Betacode ist sehr leicht zu erlernen und verlangt von den Transkriptoren keinerlei vertiefte Kenntnisse des von ihnen transkribierten Schriftsystems.
Das Typisierungstool (Link)

Das VerbaAlpina-Tool zur Typisierung von Daten aus analogen Quellen. Das Beispiel zeigt im oberen markierten Feld eine Reihe von transkribierten Einzelbelegen der AIS-Karte 1218_1, "il siero del formaggio; il siero della ricotta", die dem lexikallischen Typ lacciata (f.) (roa.) zugeordnet werden können.
Das Typisierungstool erleichtert den Bearbeitern (in der Regel graduierte Sprachwissenschaftler) die Zuweisung mehrerer auf einer Sprachatlaskarte verzeichneter Einzelbelege, die jeweils Varianten ein und desselben lexikalischen Typs sind, eben diesem zuzuordnen. Das Tool erlaubt überdies die Neuanlage von lexikalischen Typen bzw. die Bearbeitung bereits vorhandener.
Georeferenzierungen
Ein obligatorisches Merkmal aller objektsprachlichen Daten sind Georeferenzierungen, damit virtuelle Karten (s.u.) erstellt werden können; im Fall zahlreicher Dialektwörterbücher können den Belegorten entsprechende Koordinaten zugeordnet werden. Sehr gute Beispiele sind die großen schweizerischen Wörterbücher, der Glossaire des patois de la Suisse romande (GPSR), der Vocabolario dei dialetti della Svizzera italiana (VSI) und der Dicziunari Rumantsch Grischun (DRG), für die die Daten in der Manier eines Atlas in einem genau identifizierten Netz von Orten erhoben wurden, wie folgende Karte zeigt:
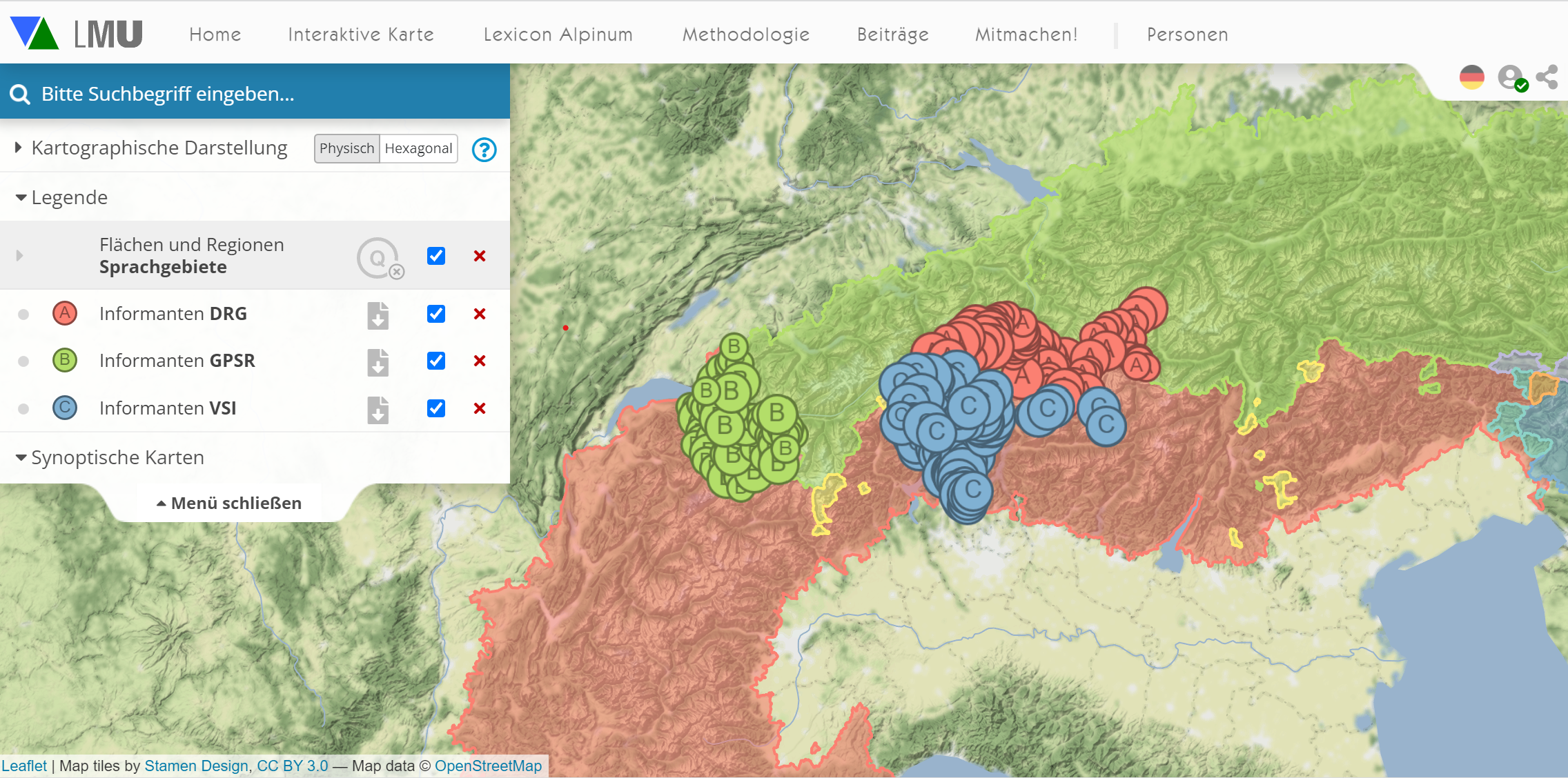
Ortsnetze des DRG, GPSR und VSI (interaktives Original)
Geographische Bezugseinheit sind bei VerbaAlpina die politischen Gemeinden. Die zugrundeliegenden Daten wurden bald nach Projektbeginn gesammelt und werden nicht aktualisiert, sie bilden einen stabilen geographischen Referenzrahmen. Standardmäßig werden aus den Quellen gesammelte Sprachbelege jeweils auf das Referenzraster der politischen Gemeinden bezogen. Die Georeferenzierung erfolgt über die Registrierung von WGS84-Koordinaten. Für jede Gemeinde sind in der Datenbank von VerbaAlpina die Grenzverläufe der Gemeindegrenzen hinterlegt, hinzu kommen Punktkoordinaten, die jeweils auf den geometrischen Mittelpunkt der Gemeindeflächen weisen. Es besteht außerdem die Möglichkeit, Sprachbelege quasi metergenau und zunächst unabhängig von der Gemeindelogik zu verorten.
2. Bezug der sprachlichen Daten zu außersprachlichen Normdaten
Sprachliche Daten und ihre Beschreibungskategorien waren immer schon – wenngleich in unterschiedlicher Explizitheit – auf die außersprachliche Wirklichkeit bezogen. Mittlerweile kann der Bezug im technischen Sinn operationalisiert werden, denn es stehen persistente Normdaten zur Verfügung. Großes, bei weitem (noch) nicht ausgeschöpftes Potential besitzen die Identifikatoren des Wikidata-Projekts. Sie bieten eine sehr differenzierte und verlässliche Referenzebene, die einerseits Grundlage für die komplementäre und vergleichende Erfassung mehrerer Sprachen ist und andererseits geeignete Suchfilter für die Abfrage der jeweiligen einzelsprachlichen Bezeichnungen liefert. Dadurch werden Semasiologie und Onomasiologie scharf getrennt. Vgl. die Konzeptsuche:
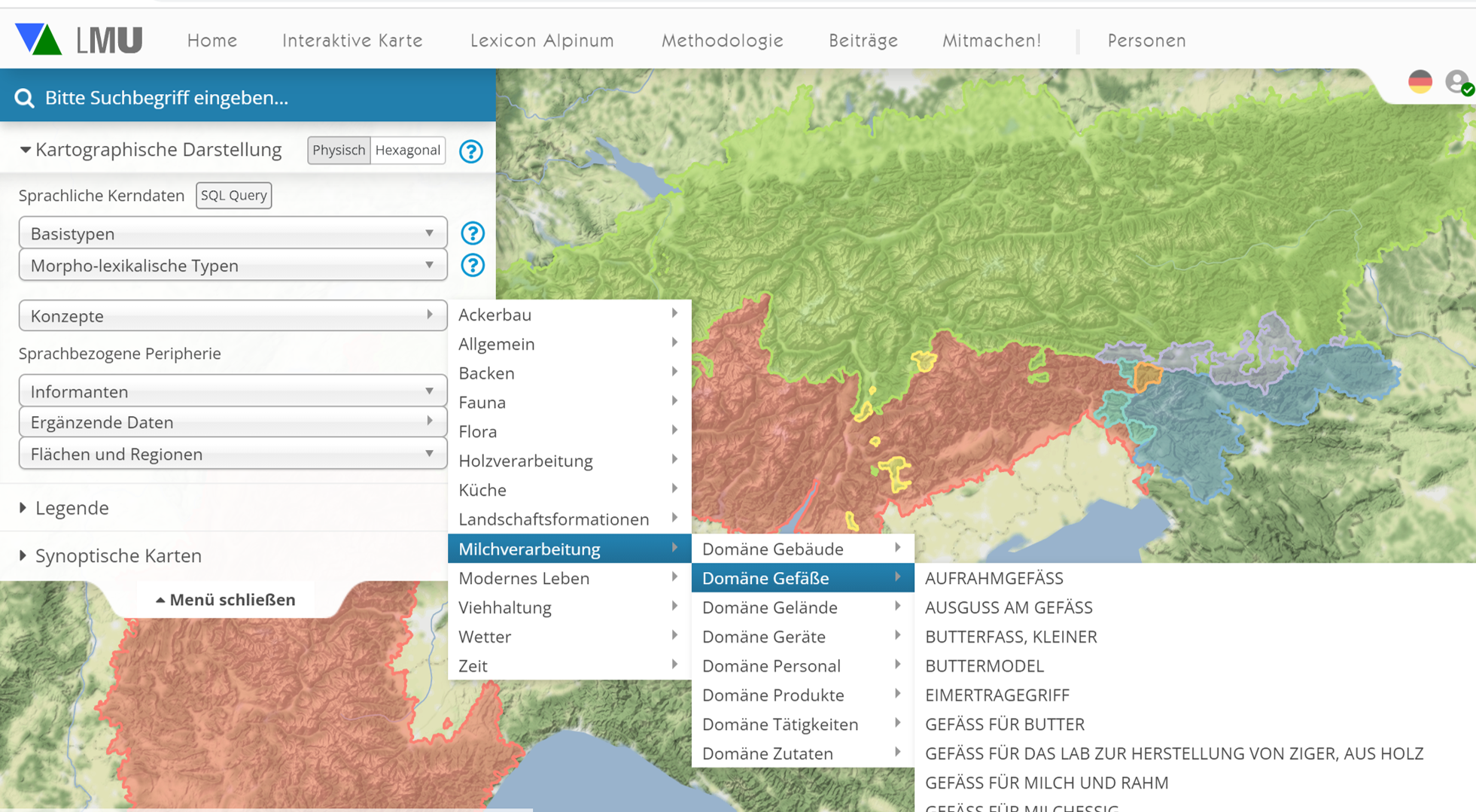
Onomasiologische Konzeptsuche in VA
Von Vorteil ist auch, dass die Wikidata grundsätzlich von jedermann gepflegt und erweitert werden kann. So können z. B. fehlende Konzepte in Wikidata nachgetragen werden. VerbaAlpina z. B. ist über die Q-ID Q66817486 eindeutig indentifiziert (https://www.wikidata.org/wiki/Q66817486).
Neben den Normdaten von Wikidata integriert VerbaAlpina auch die Identifikatoren des auf geographische Entitäten spezialisierten Geonames-Projekts. Der Zugriff auf die externen Normdatenseiten ist innerhalb der VerbaAlpina-online-Karte über die Belegfenster möglich, die sich beim Anklicken der Kartensymbole öffnen:
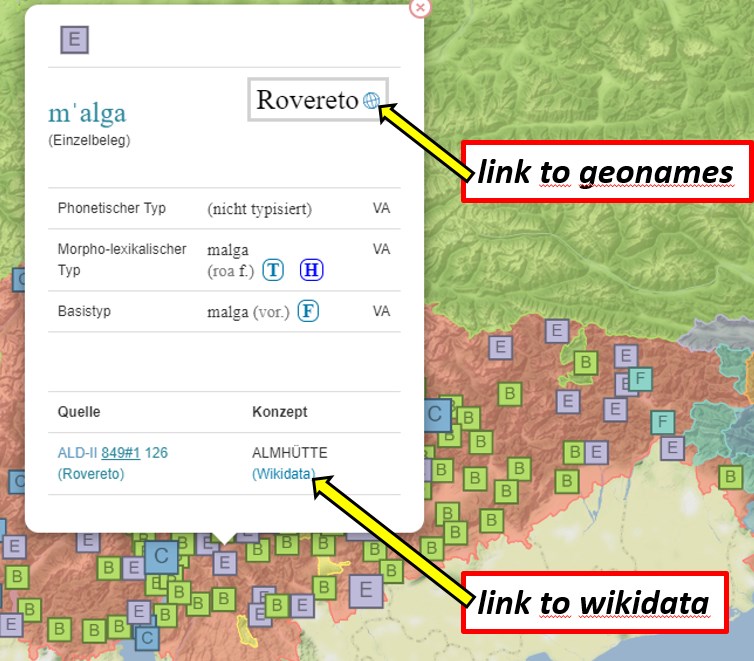
Integration externer Normdaten in einem Belegfenster der Online-Karte
Die Anbindung an externe Normdatensysteme ist nicht zuletzt für die Auffindbarkeit von VerbaAlpina-Daten von außen von Bedeutung. Bislang sind die Wikidata-QIDs nur intern mit den VerbaAlpina-eigenen Identifikatoren verknüpft. Es ist beabsichtigt, die VA-Daten in nach Wikidata zu exportieren und sie mit einer eigenen "Property" (VA-ID) zu versehen. Auf diese Weise werden die VerbaAlpina-Daten zum Teil des Semantic Web. Konzeptionelles Vorbild sind die, auch an der ITG angesiedelten, Projekte "Kaiserhof", einer Datenbank, die die habsburgischen Höflinge erfasst, und BMLO, das "Bayerische Musikerlexikon Online". Die Identifikatoren dieser beiden Projektdatenbanken können in Wikidata mit Hilfe der Abfragesprache SPARQL abgerufen werden. Ähnliches schwebt uns auch für VerbaAlpina vor.
Konkret angedacht ist auch der Export der von VA gesammelten Sprachdaten in die Lexikographie-Sektion von Wikidata(Beispiel: Lexeme, die eine Farbe bezeichnen).
3. Forschungsdatenmanagment (FDM)
Orientierung an den FAIR-Kriterien
Das Akronym FAIR wurde aus den Anfangsbuchstaben der vier - letztlich forschungsethischen - Leitkriterien findable, accessible, interoperable und reusable gebildet; ihre Umsetzung wurde bereits mehrfach und auch im Detail beschrieben (vgl. vor allem Lücke, Krefeld/Lücke 2020 und Krefeld 2018 g).
Die Ausrichtung an den FAIR-Kriterien impliziert die Einhaltung der Open Access und Open Source-Richtlinien und den Verzicht auf die Entwicklung und den Einsatz proprietärer Werkzeuge.
Kontakt zu FDM-Institutionen
Nachhaltigkeit hängt zu einem nicht unwesentlichen Teil davon ab, ob Institutionen mit unbefristeter Existenzperspektive die Verantwortung für die Bewahrung der Projektergebnisse übernehmen. VerbaAlpina hat deswegen schon vor längerer Zeit den Kontakt zur UB der LMU gesucht. Grundsätzlich erscheinen die Bibliotheken als die idealen Partner für das Forschungsdatenmanagement, im wesentlichen aus zwei Gründen:
- Die Bewahrung wissenschaftlicher Erträge ist seit jeher die zentrale Aufgabe der Bibliotheken
- Staats- und Universitätsbibliotheken besitzen in aller Regel eine unbefristete Existenzperspektive
VerbaAlpina ist überdies Pilotprojekt im von der Bayerischen Staatsregierung finanzierten FDM-Projekt "eHumanities – interdisziplinär", das sich mit den Herausforderungen des Forschungsdatenmanagements vor dem Hintergrund der immer noch fortschreitenden Digitalisierung auseinandersetzt.
In Zusammenarbeit mit der UB der LMU ist es mittlerweile gelungen, zunächst zwei ausgewählte Versionen des VerbaAlpina-Datenbestands (19/1 und 19/2) in das Forschungsdatenrepositorium der UB zu übertragen. Die Daten sind dort außerdem in das Recherche-Portal "Discover" eingeflossen, wo auf sie nun in unterschiedlicher Granulierung zugegriffen werden kann. So ist es etwa möglich, vollständige Versionen zu referenzieren oder herunterzuladen. Zusätzlich können Einzelbelege, morpholexikalische Typen oder ganze Ortschaften samt dem ihm zugeordneten Sprachmaterial adressiert werden. Das System erlaubt die Erzeugung spezifischer DOIs für ausgewählte Datenpakete, eine eindeutige Referenzierung ist überdies durch UB-eigene persistente Identifikatoren möglich.
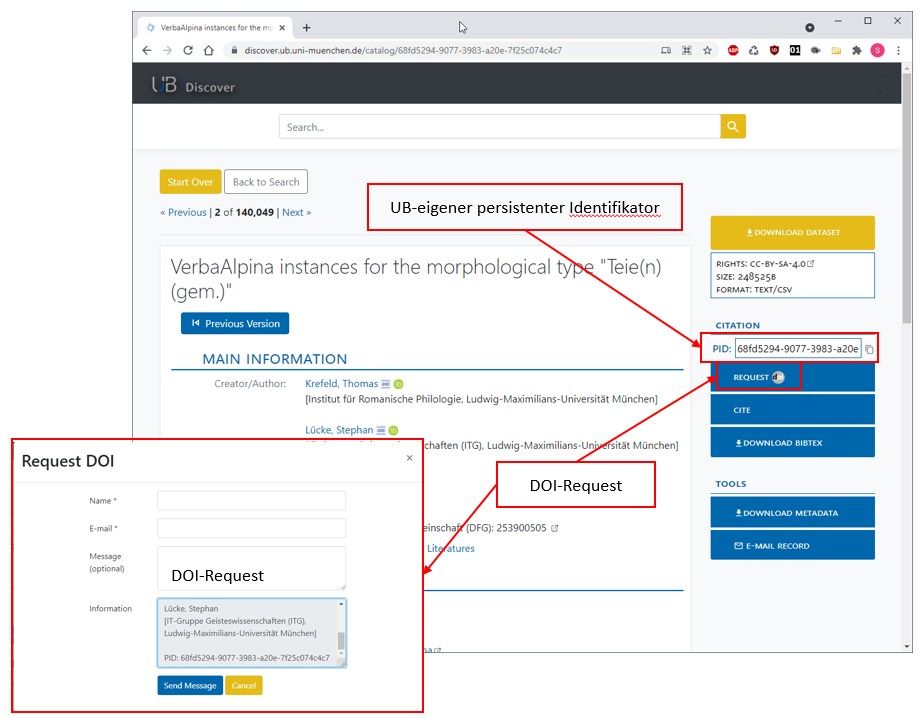
Portal "Discover" der UB der LMU. Das System erlaubt u. a. die Erzeugung von DOIs, die auf einzelne morpholexikalische Typen von VerbaAlpina verweisen.
4. Adressierung und interaktive Einbindung eines breiten Publikums (Crowdsourcing)
Die allgemeine Zugänglichkeit von Inhalten, die im Internet publiziert werden, führt dazu, dass grundsätzliche ein sehr breites Publikum angesprochen wird, das sich in durchaus unterschiedlichen Wissenswelten bewegt. Dazu gehören – wenigstens potentiell – die sprachwissenschaftliche Fachwelt, interessierte Laien und die Sprechergemeinschaften inklusive mancher Informanten. Selbstverständlich sind nicht aller Informationen für alle Nutzer gleichermaßen interessant, so dass es nicht nötig erscheint, alles in maximal verständlicher Alltagssprache auszudrücken. Das wäre auch nicht im Sinne er erforderlichen begrifflichen Schärfe, die auf Terminologie nicht verzichten kann. Allerdings wird die Verständlichkeit der Oberfläche durch den Einsatz zahlreicher Informationsfenster erleichtert, die sich öffnen, wenn der Mauspfeil darauf bewegt wird (so genannte Tooltips). Hier ein Beispiel:
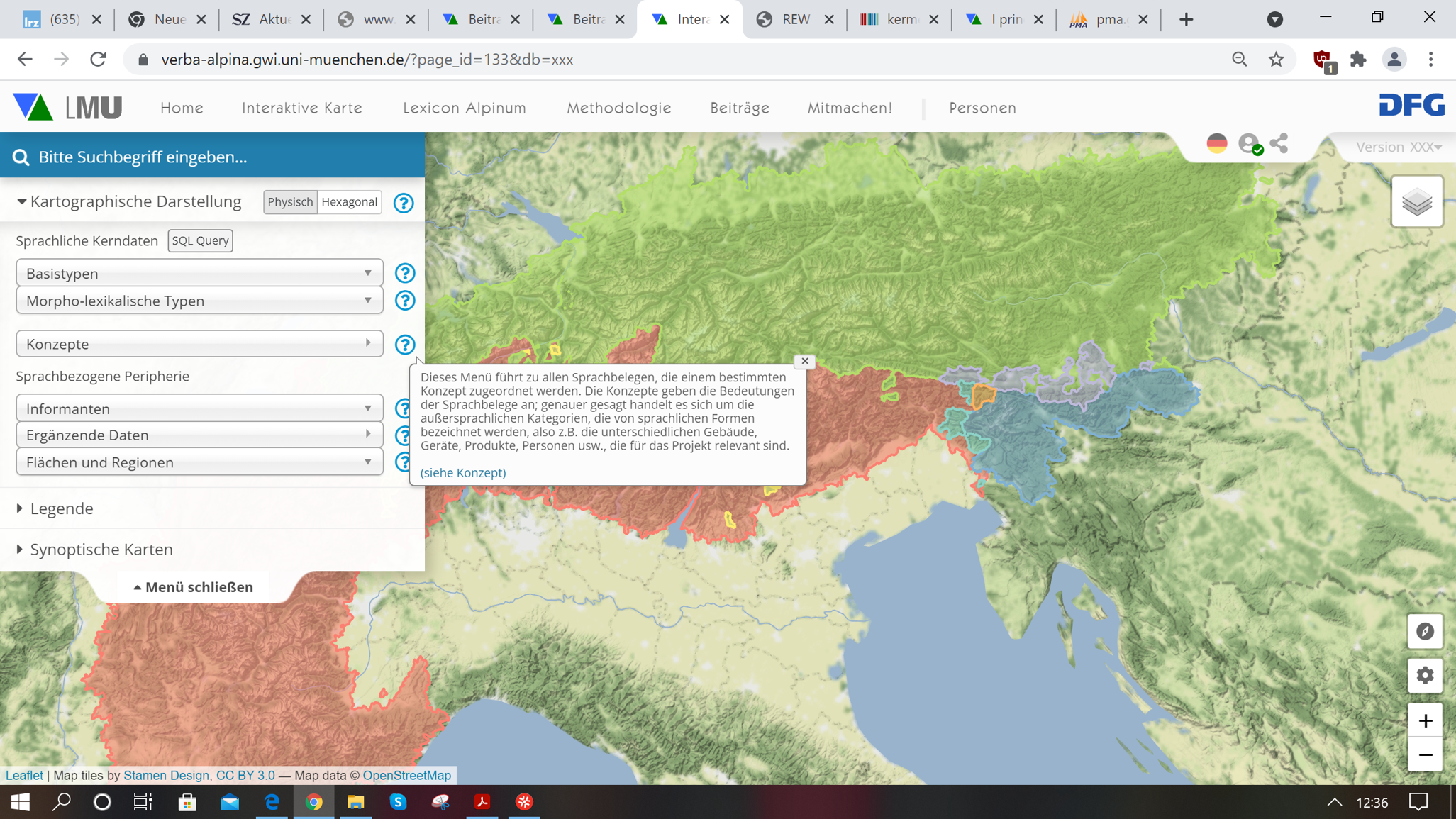
Beispiel für einen Tooltip (interaktives Original)
- Jeder kann unabhängig von seinem Experten- oder Laientum sprachliche Formen beisteuern; darüber hinaus ist es auch möglich, fehlende Konzepte zu ergänzen.(vgl. https://www.verba-alpina.gwi.uni-muenchen.de/en/?page_id=1741.
- Nutzer, die Belege/Konzepte beisteuern, können sich registrieren und so für das Projekt erreichbar bleiben; das ist nützlich für eventuelle Rückfragen. #wieviel % machen das?#
- Jeder Nutzer kann interaktiv durch Kombination beliebiger Inhalte synoptische Karten generieren, fixieren und zur Veröffentlichung vorschlagen. Diese Vorschläge werden jedoch nicht automatisch allgemein zu Verfügung gestellt, sondern vorher durch die Projektverantwortlichen geprüft.
- Ein direkte Kontaktaufnahme ist über die Social Media-Auftritte des Projekts ebenso möglich, wie über E-Mail-Adressen (vgl. Home).
- Wissenschaftliche Partnerprojekte können beliebig viele relevante Daten liefern und in einer eigenen Datenbank, die Teil der Projektarchitektur ist, hosten.
5. Offene und dynamische Datenbestände
Die Möglichkeit kontinuierlicher Anreicherung der verfügbaren Daten setzt voraus, dass grundsätzlich mit offenen und dynamischen Datenbeständen gearbeitet wird. Es erübrigt sich so die ideale, d.h. illusionäre Vorstellung empirischer Vollständigkeit. Allerdings ist es im Sinne der Transparenz und Nachprüfbarkeit unbedingt notwendig, eine empirische Verlässlichkeit zu garantieren, damit die Projektergebnisse auch zitierbar sind. Diese fundamentale Bedingung wird durch eine regelmäßige Versionierung der Daten erfüllt. Rein technisch wird die Versionierung durch die Anfertigung einer Kopie der Datenbank erreicht. Die Kopie erhält einen Namen, der auf den Zeitpunkt der Erzeugung verweist (191: Jahresmitte 2019; 192: Jahresende 2019). Die Kopie der Datenbank ist "eingefroren", Änderungen an den darin enthaltenen Daten ist nicht mehr möglich. Auf dem Projektportal ist über ein Drop-Down-Menü der Wechsel zwischen den verschiedenen Versionen möglich:
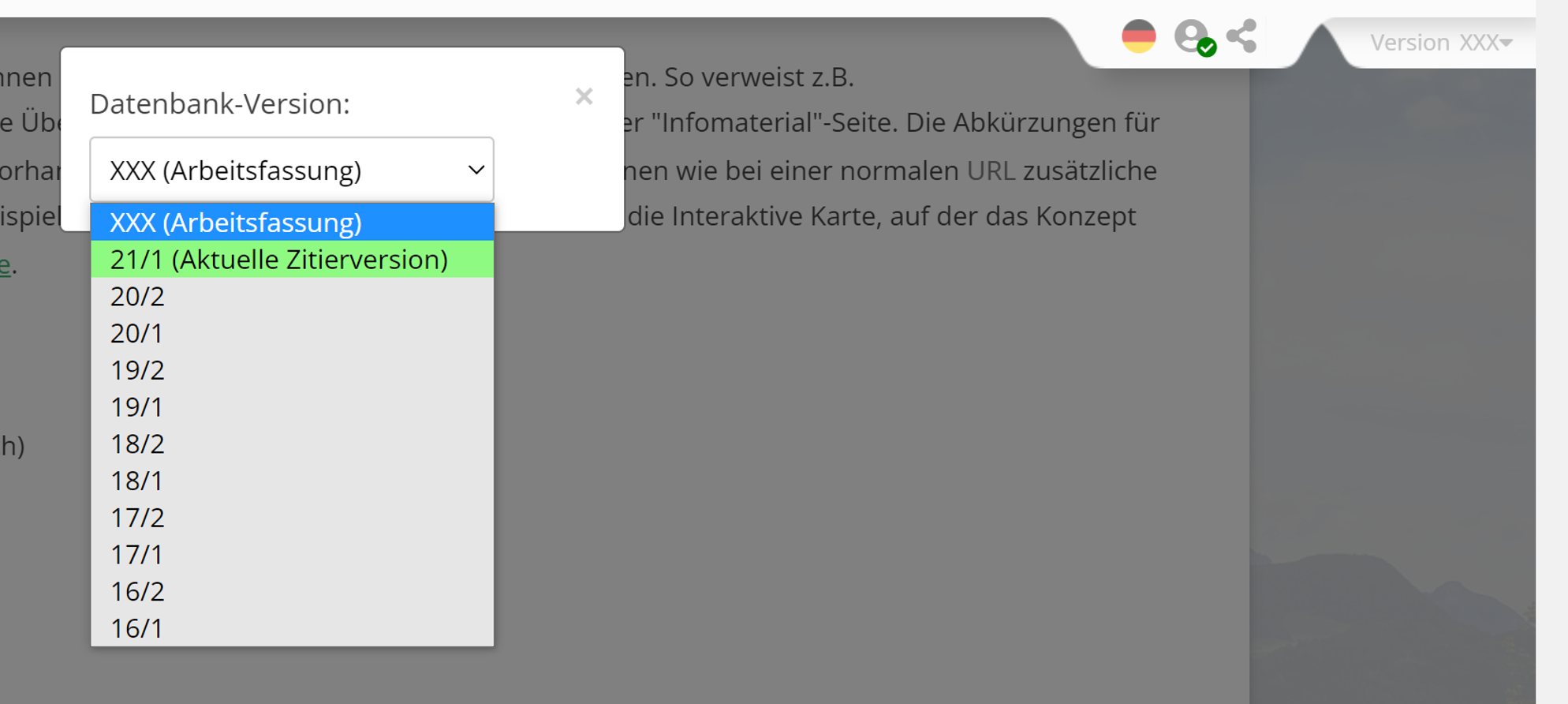
Verfügbare VA-Versionen
Die Versionsnummer ist auch Teil der meisten URLs, die auf VerbaAlpina-Ressourcen verweisen. Als Beispiel sei hier die URL genannt, die auf den Morpholexikalischen Typ L2599/tegia (roa f.) im LexikonAlpinum in der VA-Version 211 verweist:
Eine Übersicht über sämtliche bislang vorhandenen Versionen findet sich auf der Startseite von VerbaAlpina unter dem Button "Timeline". Ein Klick auf eines der Versionsbilder öffnet eine Statistik, die den Datenzuwachs in der jeweiligen Version anzeigt:
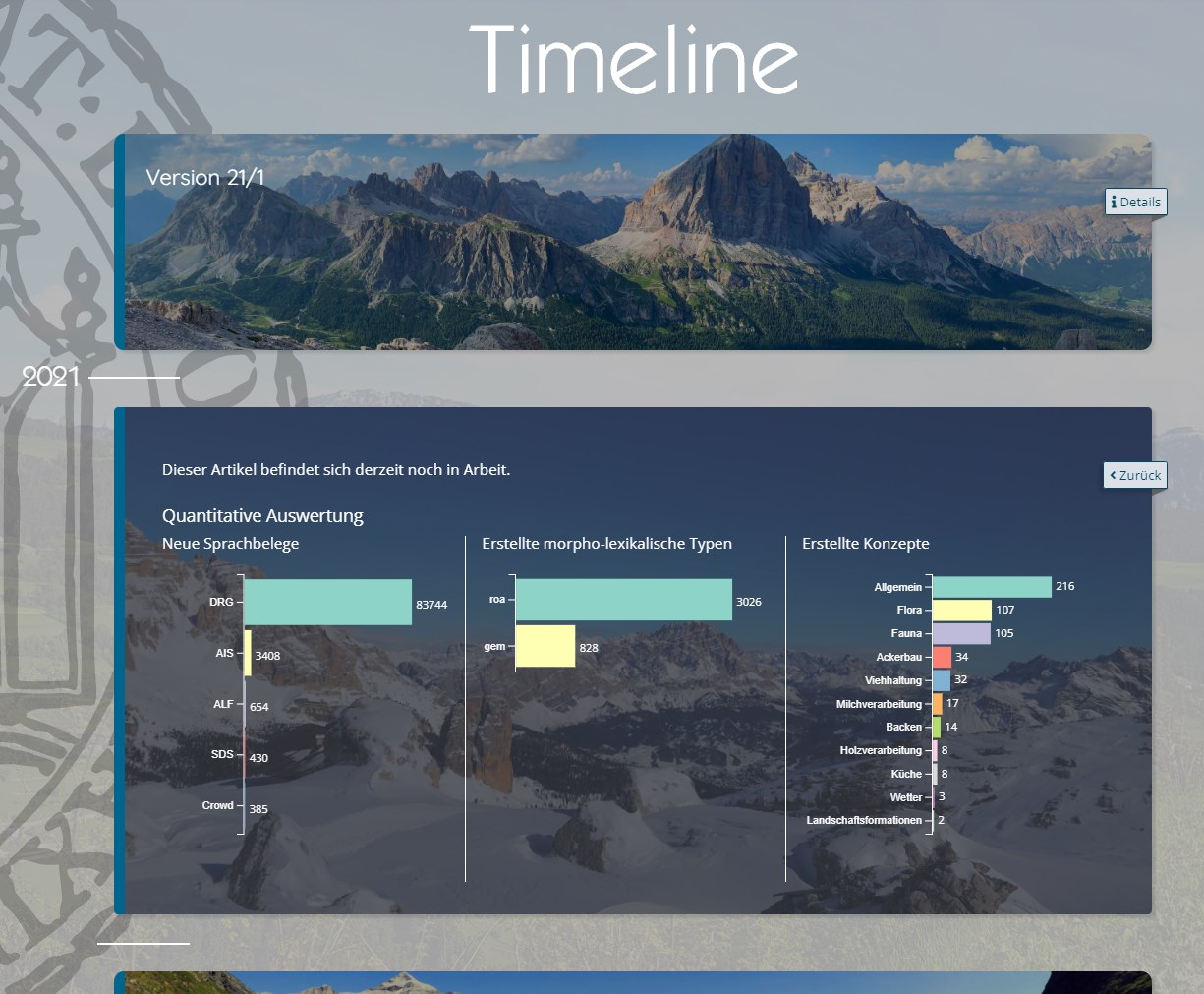
VerbaAlpina "Timeline" mit statistischen Daten zur VerbaAlpina-Version 2021
Künftig wird die Timeline-Übersicht auch noch weitere Informationen zu Veränderungen gegenüber den Vorgängerversionen enthalten. Dabei wird es vor allem um nicht quantifizierbare Errungenschaften wie etwa die Entwicklung neuer Tools oder Veränderungen in Design oder Usability gehen.
6. Virtuelle Kartographie auf georeferenzierter Grundlage
Im Sinne einer konsequenten Nutzung von Webtechnologie ist der Verzicht auf den Einsatz einer graphischen Grundkarten. Rein virtuelle Kartierung bietet mehrere Vorteile; sie erlaubt es dem Nutzer optional ganz unterschiedliche Oberflächen anzubieten (mit/ohne Relief, mit/ohne Beschriftung, Karte/Satellitenbild usw.):
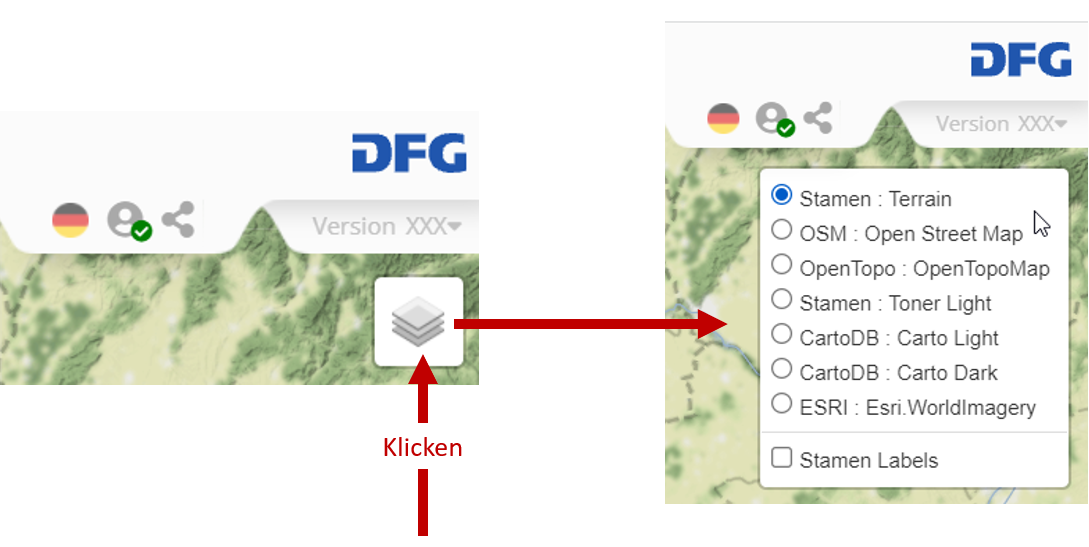
Optionale Kartenoberflächen in VA (interaktives Original)
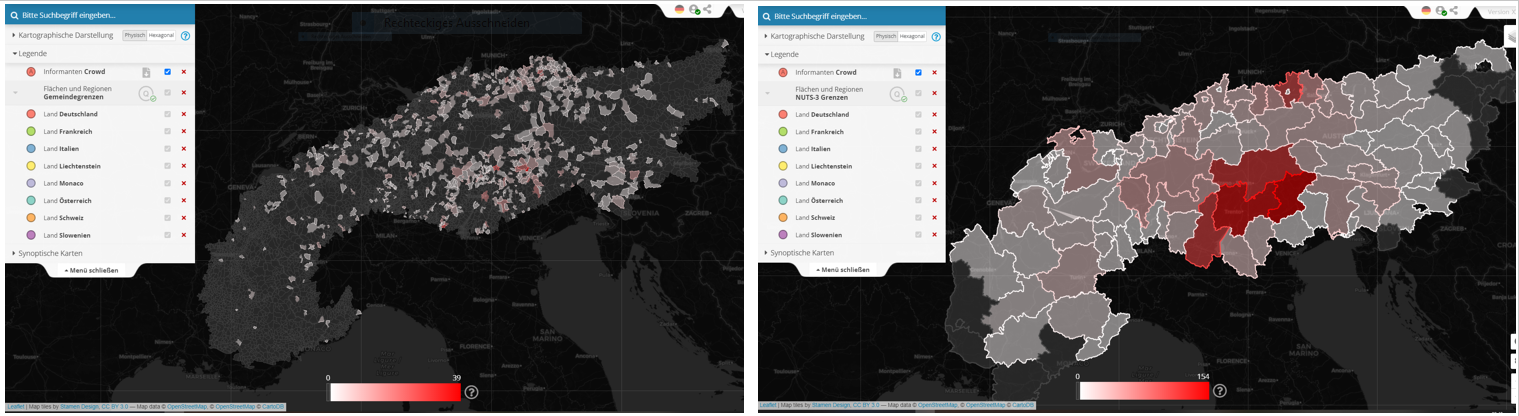
Optionale Visualisierung mit Referenz auf die Gemeindeflächen (links, interaktives Original) und die NUTS 3-Regionen (rechts, interaktives Original)
7. Möglicher Einbezug nicht sprachlicher Kontextdaten
Für die Interpretation geolinguistischer Konstellationen sind demographische und historische Informationen über den Belegort unerlässlich; VA hat daher alle 5771 Gemeindenamen des Alpenraums mit den jeweiligen Einträgen im Dienst geonames.org verknüpft. Im Fall der Gemeinde, auf deren Territorium wir uns befinden, Garmisch-Partenkirchen, führt uns der Dienst zu vielfältigen topographischen, administrativen und enzyklopädischen (Wikipedia-Logo) Informationen:
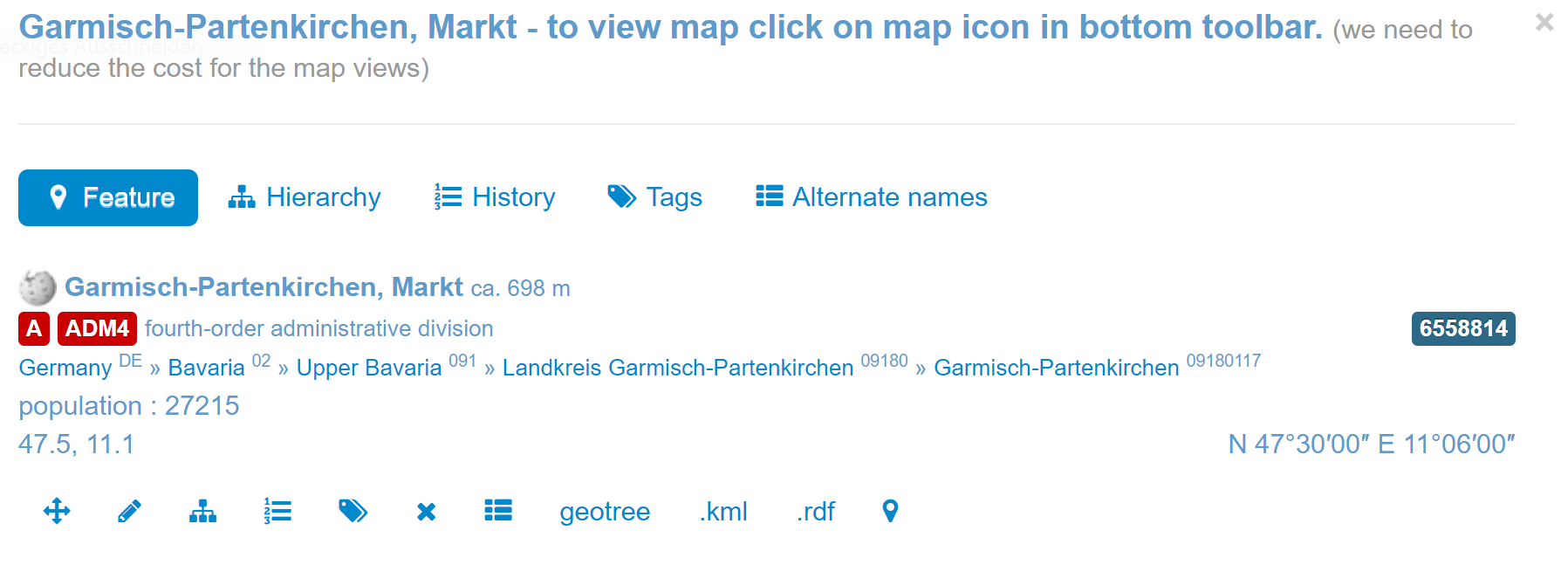
Über geonames.org importierte Informationen (Beispiel Garmisch-Partenkirchen – Quelle)
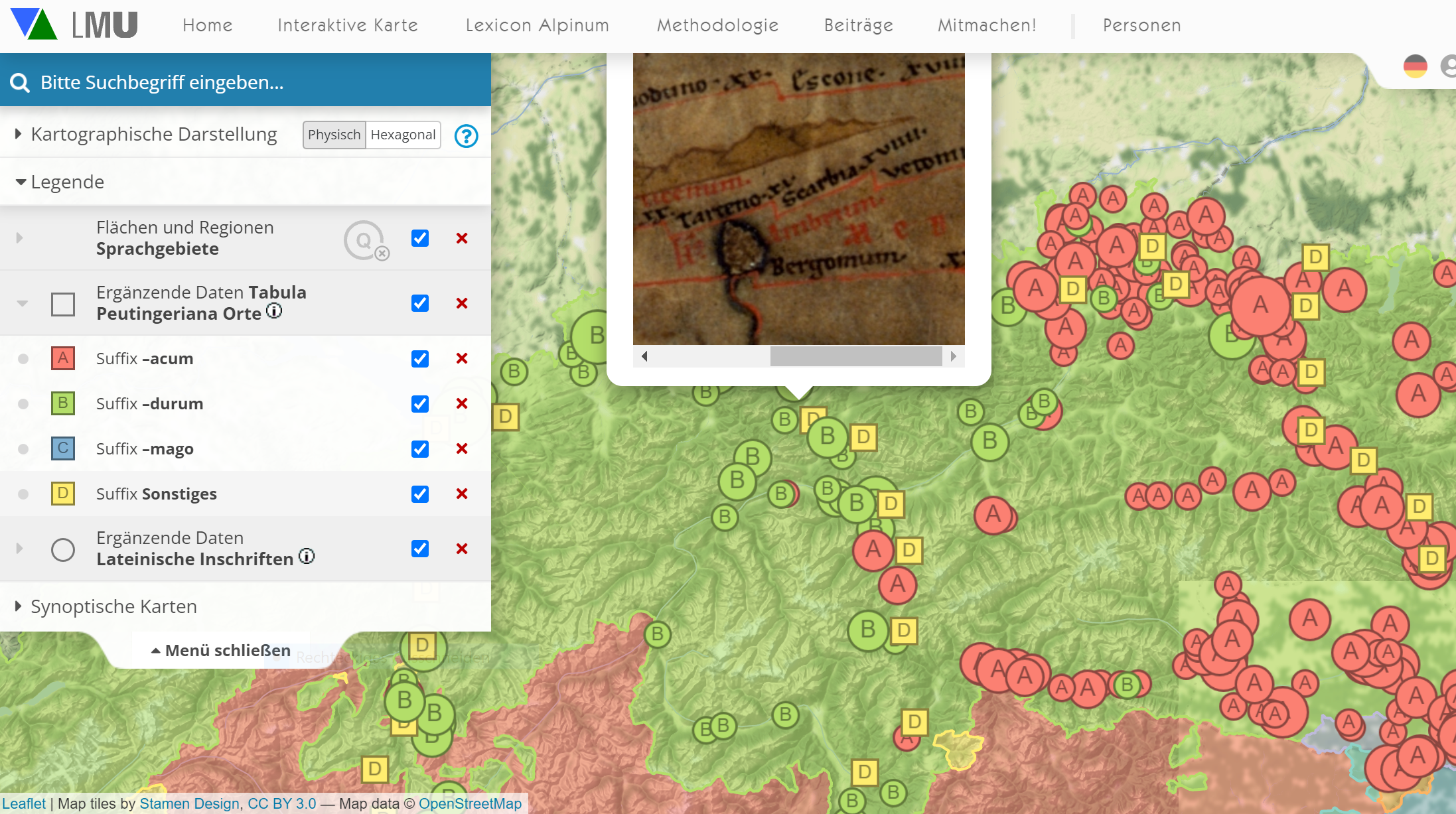
Erwähnung von Partenkirchen (Tarteno ⇒ <P>arteno) auf der Tabula Peutingeriana (interaktives Original)
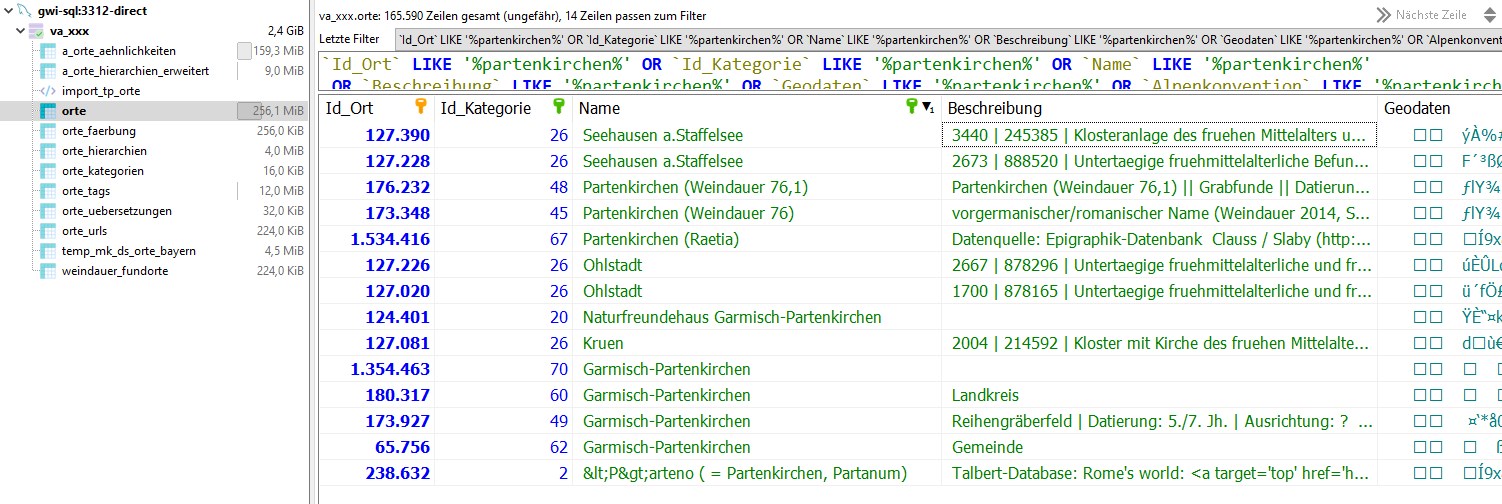
Ausschnitt aus der Tabelle "Orte" in der VA-Datenbank mit Einträgen zu "Partenkirchen"
Die Tabelle "Orte" enthält aktuell etwa 165000 Einträge und hat ein Volumen von mehr als 250 MB. Die Eintragungen in diese Tabelle sind insgesamt 47 Kategorien zugeordnet. Neben den Daten von der Tabula Peutingeriana sind dies beispielsweise die folgenden:
Kloester (1317); langobardische_graeberfelder (120); Walsergemeinden (77); Raetische Inschriften (36); ...
8. Überwindung der Gattungsgrenzen
Die traditionellen Gattungen, in denen die Ergebnisse geolinguistischer Forschung veröffentlicht wurden (Ortsmonographie, Atlas, Wörterbuch, Korpus), verfolgen jeweils spezifische Zwecke und sind daher komplementär zu sehen. Es gibt im Rahmen der digitalen Medien jedoch keinen Grund mehr, sie kategorisch zu trennen. Gerade wegen ihrer Komplementarität liegt es vielmehr nahe, sie organisch mit einander zu verflechten, wie es in VerbaAlpina unternommen wurde. Der Webauftritt des Projekts liefert unter dem Reiter Methodologie theoretische Erörterungen zentraler linguistischer und informationstechnischer Begriffe; diese konzeptionelle Komponente ist eng mit den beiden wichtigsten Funktionalitäten verschränkt, der interaktiven Karte und der Lexicon Alpinum. Diese beiden Komponenten wiederum sind gewissermaßen symbiotisch angelegt worden, denn jeder Lexikoneintrag kann durch einen Klick auf einer Karte visualisiert werden und von der Karte gelangt man durch einen Klick zu den korrespondierenden Lexicon-Einträgen:
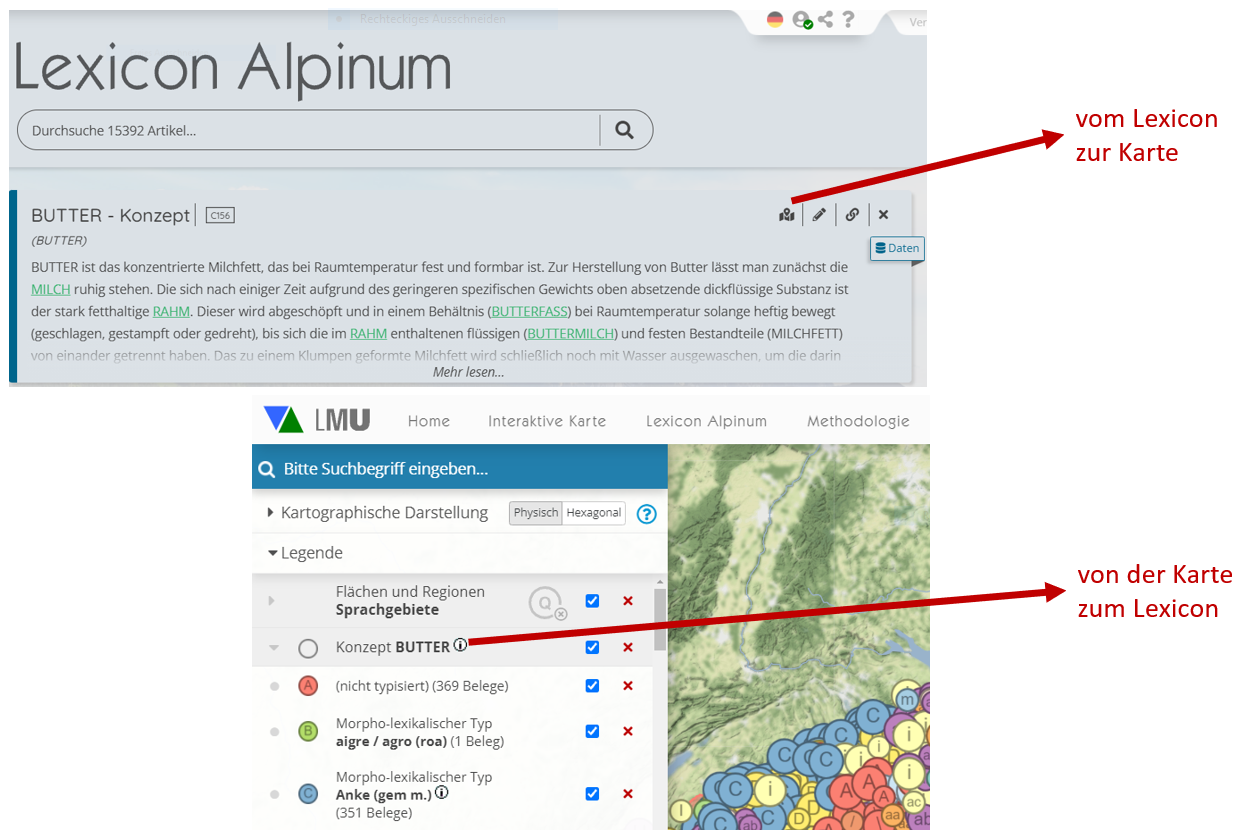
Wechselseitige Verschränkung lexikographischer und kartographischer Informationen
Schließlich ist das Datenkorpus auch aus diskursivem Text oder aus der interaktiven Karte heraus direkt abfragbar. Es besteht für Nutzer die Möglichkeit, auf der interaktiven Karte individuelle Datenbankabfragen über die Schaltfläche 'SQL Query' abzuschicken und die Ergebnisse so in kartographischer Darstellung einzusehen.
Die Nutzung der SQL-Funktion verlangt Kenntnisse in der Abfragesprache SQL. Die nötigen Informationen über Struktur und Inhalt der an dieser Stelle abfragbaren Tabelle sind über einen Klick auf das kleine Fragezeichen neben dem Schlüsselwort "WHERE" abrufbar:
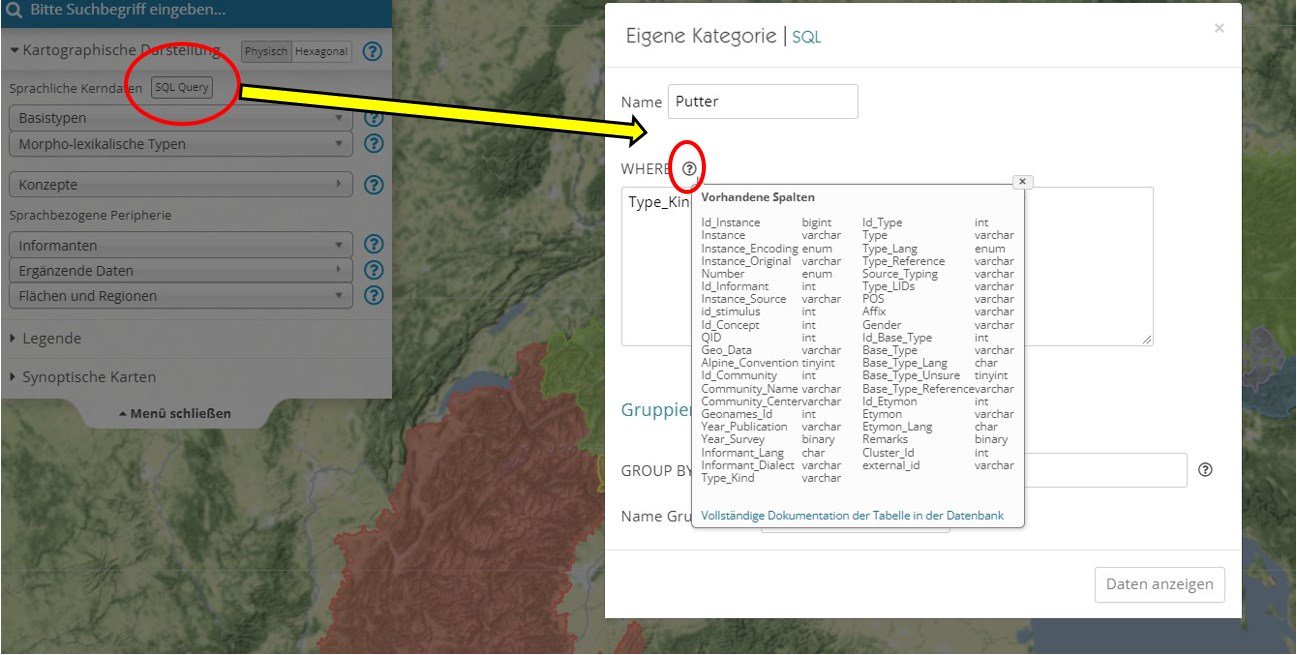
Dialogfelder zur Formulierung individueller Abfragen. Ein Tooltip präsentiert die in der Tabelle vorhandenen Felder samt deren Datentypen.
Ein in blau gesetzter Link am unteren Rand des Tooltipps führt auf eine eigene Seite mit detaillierten Informationen zu den Datenbankfeldern und deren Inhalten.
Beispiel: Belege mit dem Basistyp "butyru(m)":
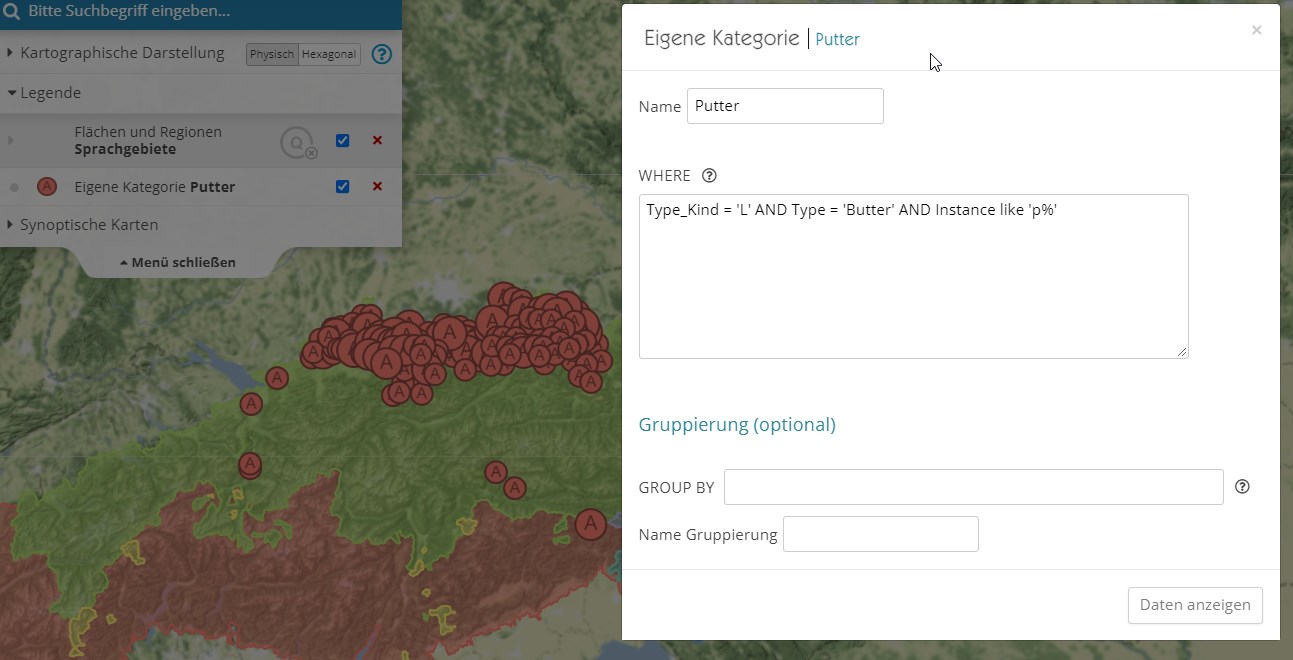
Kartierung von Einzelbelegen, die dem lexikalischen Typen "Butter" zugeordnet sind und mit einem P beginnen. Ein Rechtsklick auf den Legendeneintrag ermöglicht die Modifizierung der SQL-Abfrage (Dialogfeld rechts).
Ein Beispiel für Aggregation und Gattungsverschränkung
Abschließend soll die Aggregation unterschiedlicher Quellen(typen) und die Gattungsverschränkung etwas detaillierter exemplifiziert werden. Ausgangspunkt der Darstellung ist der Artikel chaschöl des bündnerromanischen Referenzwörterbuchs DRG (Link). Die dort genannten Formen erscheinen auf der Karte chaschöl im Verbund mit denjenigen aus anderen Quellen, wie stellvertretend die Markierung der Orte des VSI zeigt:
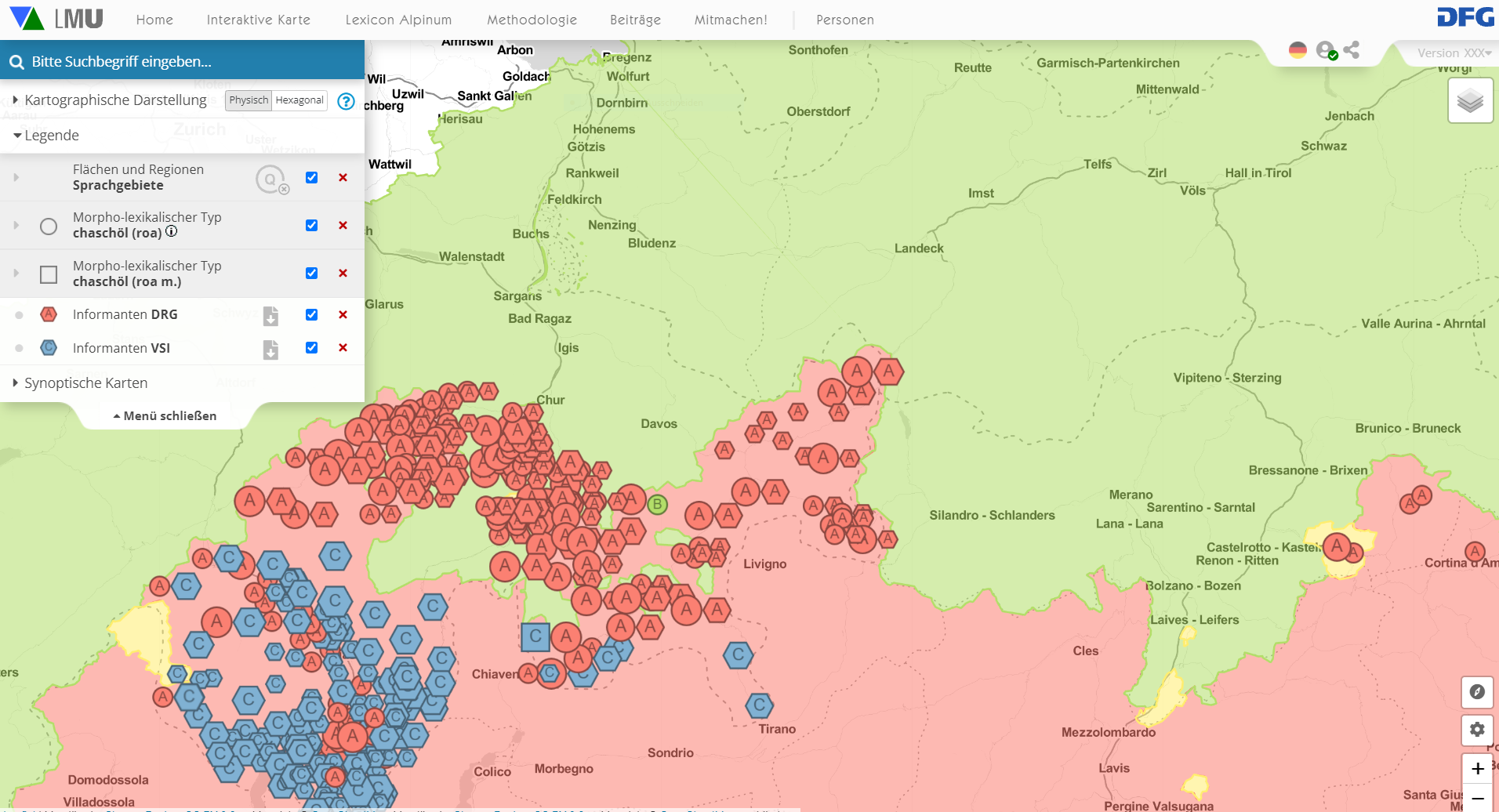
Verbreitung des Typs chaschöl (< lat. caseolus) im Spiegel aggregierter Quellen, interaktives Original
Bibliographie
- ADDU = Thun, Harald / Elizaincín, Adolfo (2000-): Atlas lingüístico diatópico y diastrático del Uruguay, Kiel, Westensee
- AIS = Jaberg, Karl / Jud, Jakob (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz, Zofingen, vol. 1-7
- ASD = Krefeld, Thomas / Lücke, Stephan / Mages, Emma (2016): Audioatlas Siebenbürgisch-Sächsischer Dialekte , München, Ludwig-Maximilians-Universität. Link
- ASLEF = Pellegrini, Giovan Battista (1974-1986): Atlante storico-linguistico-etnografico friulano, Padova, vol. 1-6
- AsiCa = Krefeld, Thomas / Lücke, Stephan (2006-2017): Atlante sintattico della Calabria, München. Link
- Asica 2.0 = Krefeld, Thomas / Lücke, Stephan (2019): Atlante sintattico della Calabria. Rielaborato tecnicamenta da Veronika Gacia e Tobias Englmeier, München. Link
- DRG = De Planta, Robert/ Melcher, Florian/ Pult, Chasper/ Giger, Felix (1938ff.): Dicziunari Rumantsch grischun, Chur, Inst. dal Dicziunari Rumantsch Grischun. Link
- DWDS = Berlin-Brandenburgische Akademie der Wissenschaften (Hrsg.) (2004-): Das Digitale Wörterbuch der deutschen Sprache, Berlin. Link
- GPSR = Gauchat, Louis (Hrsg.) (1924ff.): Glossaire des patois de la Suisse romande, Genève [u.a.], Droz [u.a.]
- Idiotikon = (1881 ff.): Schweizerisches Idiotikon. Schweizerdeutsches Wörterbuch, Basel. Link
- Krefeld 2018 g = Krefeld, Thomas (2018): I principi FAIR nel progetto VerbaAlpina, ossia il trasferimento della geolinguistica alle Digital Humanities. Link
- Krefeld/Lücke 2020 = Krefeld, Thomas / Lücke, Stephan (2020): 54 Monate VerbaAlpina – auf dem Weg zur FAIRness, in: Ladinia, vol. XLIII, 139-156. Link
- Metropolitalia = Krefeld, Thomas / Lücke, Stephan / Bry, François (2010-2013): Metropolitalia. Social Language Tagging, München. Link
- VALTS = Gabriel, Eugen (1985-2004): Vorarlberger Sprachatlas mit Einschluss des Fürstentums Liechtenstein, Westtirols und des Allgäus , vol. 1-5, Bregenz, vol. 1-5, Vorarlberger Landesbibliothek
- VSI = Sganzini, Silvio (1952ff): Vocabolario dei dialetti della Svizzera italiana, Lugano, Tipografia la Commerciale
- VerbaAlpina = Krefeld, Thomas / Lücke, Stephan (2014-): VerbaAlpina. Der alpine Kulturraum im Spiegel seiner Mehrsprachigkeit, München. Link
- WBOe = Bauer, Werner/ Kranzmayer, Eberhard. Institut für österreichische Dialekt- und Namenlexika (Hrsg.) (1970–): Wörterbuch der bairischen Mundarten in Österreich, Wien, Verl. der Österr. Akad. der Wiss.