

Der nachfolgende Text ist die überarbeitete und erweiterte Fassung eines Vortrags, der auf dem Workshop III der AG Digitale Romanistik: KI statt Crowd? Neue Perspektiven auf linguistische Sprachdatenerhebung, am 5. Dezember 2025 online gehalten worden ist.



Übersicht
Der Vortrag folgt im wesentlichen der Ankündigung in der Einladung zu diesem Workshop. Ich beginne mit einer kurzen Vorstellung des Projekts VerbaAlpina. Es folgen dann drei Abschnitte, die sich mit dem Workflow der Sammlung von Sprachdaten befassen. Am Ende stelle ich dann noch ganz kurz die Frage, welchen Nutzen aus heutiger Sicht die KI für VerbaAlpina hätte haben können.
VerbaAlpina – Was ist/war das?

Folie 4
Im Zentrum des Interesses von VerbaAlpina stand die dialektale lexikalische Variation im Alpenraum. VerbaAlpina hat zum Beispiel interessiert, welche Wörter für die Bezeichnung des Konzepts BUTTER im Alpenraum verwendet werden. Phonetische Varianten wie zum Beispiel Anggä oder Ankä, beides phonetische Varianten des alemannischen Worts Anke, einer Bezeichnung für BUTTER, die auf lat. unguere SALBEN, BESTREICHEN zurückzuführen ist, wurden entsprechend dem morpholexikalischen Typ Anke zugeordnet.
| VA-ID | Beleg | Lexem | Informant | Ort | Konzept |
| S167243 | Anggä | Anke | CROWD 156_deu#1 anonymousCrowder_508 | Matt | BUTTER |
| S167411 | Ankä | Anke | CROWD 156_deu#1 anonymousCrowder_517 | Schübelbach | BUTTER |
Typisierung der Einzelbelege – Ein Beispiel aus den Crowd-Daten. Die von 'Crowdern' beigesteuerten Belege "Anggä" und "Ankä" sind dem Lexem Anke (L544) zugewiesen; Auszug aus dem Lexicon Alpinum (direct link).

Illustration 1: Das Untersuchungsgebiet von VerbaAlpina und die Verbreitung der unterschiedlichen Sprachfamilien im Alpenraum
Den geographischen Rahmen bildete der Alpenraum, wobei sich VerbaAlpina auf die entsprechende Grenzdefinition der sog. Alpenkonvention, einem völkerrechtlichen Zusammenschluss der Alpenanrainerstaaten, gestützt hat. Der Alpenraum ist aus sprachwissenschaftlicher Sicht v. a. deswegen interessant, weil hier, in einem naturräumlich homogenem Gebiet, gleich mehrere Sprachfamilien aufeinandertreffen: das Romanische, das Germanische und das Slawische. In den heutzutage im Alpenraum gesprochenen Dialekten sind vielfach Interferenzen zu beobachten, die auf dynamische Prozesse wechselseitigen Sprachkontakts zurückzuführen sind.

Folie 5
Bei der Sammlung des Sprachmaterials hat sich VerbaAlpina an für den Alpenraum typischen Konzeptdomänen orientiert: So ging es zum einen um den Wortschatz aus dem Bereich der traditionellen Lebenswelt, mit einem Fokus auf Alm-, Milch- und Viehwirtschaft. Desweiteren lag das Interesse auf Flora, Fauna und traditionelle Küche, sowie schließlich die moderne Lebenswelt mit Tourismus und Umweltschutz.
Ein wichtiges Ziel des Projekts ist auch gewesen, Möglichkeiten und Grenzen der elektronischen Datenverarbeitung auszuloten. Das Projekt ist vollständig digital konzipiert gewesen. Sämtliche Methoden der Datensammlung, Datenaufbereitung- und –anlyse sowie die Publikation der Ergebnisse basieren nahezu ausschließlich auf Digitalität und Vernetzung.
Die Digitalität ermöglichte u.a. die Kombination der in der analogen Welt einander ausschließenden onomasiologischen und semasiologischen Perspektive. Auf diese Weise stellt VerbaAlpina Sprachatlas und Wörterbuch in einem dar.

Folie 6

Folie 7
Das Projekt war eine Gemeinschaftsunternehmung von Sprachwissenschaft und Digital Humanities. Es wurde in drei aufeinanderfolgenden Phasen von 2014 bis 2023 von der DFG als Langfristvorhaben gefördert.
Die Datenbasis von VerbaAlpina bildeten zunächst die vorhandenen traditionellen Sprachatlanten und Wörterbücher, die die lexikalische Variation im Alpenraum dokumentierten. Als Beispiele können hier der „Sprach- und Sachatlas Italiens und der Südschweiz“, der „Sprachatlas der Deutschen Schweiz“ oder auch das „Schweizerische Idiotikon“ genannt werden. Während diese Daten teils aufwendig digitalisiert und strukturiert erfasst werden mussten, konnten von Projekten des großen Partnernetzwerks von VerbaAlpina teils bereits in digitaler Form vorliegende strukturierte Daten übernommen werden. Hier kann als Beispiel der Sprachatlas des Ladinischen ("Atlant linguistich dl ladin dolomitich y di dialec vejins", ALD) von Hans Goebl genannt werden.

Folie 8
Wie bereits gesagt, war VerbaAlpina vollkommen digital ausgerichtet. Das multifunktionale Webportal diente gleichermaßen als Werkzeug, z. B. für die Digitalisierung und Erfassung des Datenmaterials oder auch als Dokumentationsplattform für die wöchentlichen Treffen der Projektmitarbeiter, sowie für die Publikation der Projektergebnisse.

Illustration 1: Das Backend des multifunktionalen Webportals, über das die von VerbaAlpina entwickelten Tools nutzbar sind. Das Backend ist nur für Projektmitarbeiter und Projektpartner zugänglich (gewesen).
Eine ganz wichtige Rolle spielte die zentrale relationale Datenbank, in der sämtliche strukturierten Projektdaten abgelegt wurden. Sie war gleichsam das Rückgrat des Projekts. Mit Ende des Projekts im Oktober 2023 enthielt sie knapp 24.000 Lexeme ('morpholexikalische Typen') und knapp 5.500 Konzepte und besaß sie eine Größe von rund 2,6 GB.

Illustration 2: Ein Ausschnitt aus den strukturierten Daten in der VerbaAlpina-Datenbank, dargestellt im Web-Interface von PhpMyAdmin
Von den überwiegend von VerbaAlpina selbst entwickelten Tools, die über das Projektportal zugänglich waren und sind, spielte das Transkriptionsportal bei der Erfassung der Daten aus den gedruckten Sprachatlanten eine große Rolle.

Illustration 3: VerbaAlpina-Transkriptionstool. AIS-Karte 1218 (IL SIERO DEL FORMAGGIO)
Das Projektportal enthält auch eine eigene Sektion „Methodologie“, die die Methodenreflexion des Projekts dokumentiert. In zuletzt 132 Artikeln werden dort sprachwissenschaftliche und informatische Aspekte des Projekts beleuchtet. Die Themenauswahl ist weitgehend intuitiv und war überwiegend durch das Aufkommen entsprechender Fragestellungen während der Arbeit am Projekt bestimmt.

Folie 9
Sammlung von Sprachdaten mit Hilfe von Crowdsourcing

Folie 10
Die vorhandenen Sprachatlanten weisen Asymmetrien hinsichtlich der Konzeptabdeckung auf. Nicht alle für VerbaAlpina relevanten Konzepte wurden jeweils von allen Sprachatlanten oder Wörterbüchern abgedeckt. Ziel war, die geographischen Beleglücken durch Crowdsourcing zu schließen. Dies galt auch für Regionen, für die es bislang noch überhaupt keinen Sprachatlas gab bzw. gibt. Konkret gilt dies für große Teile Österreichs.
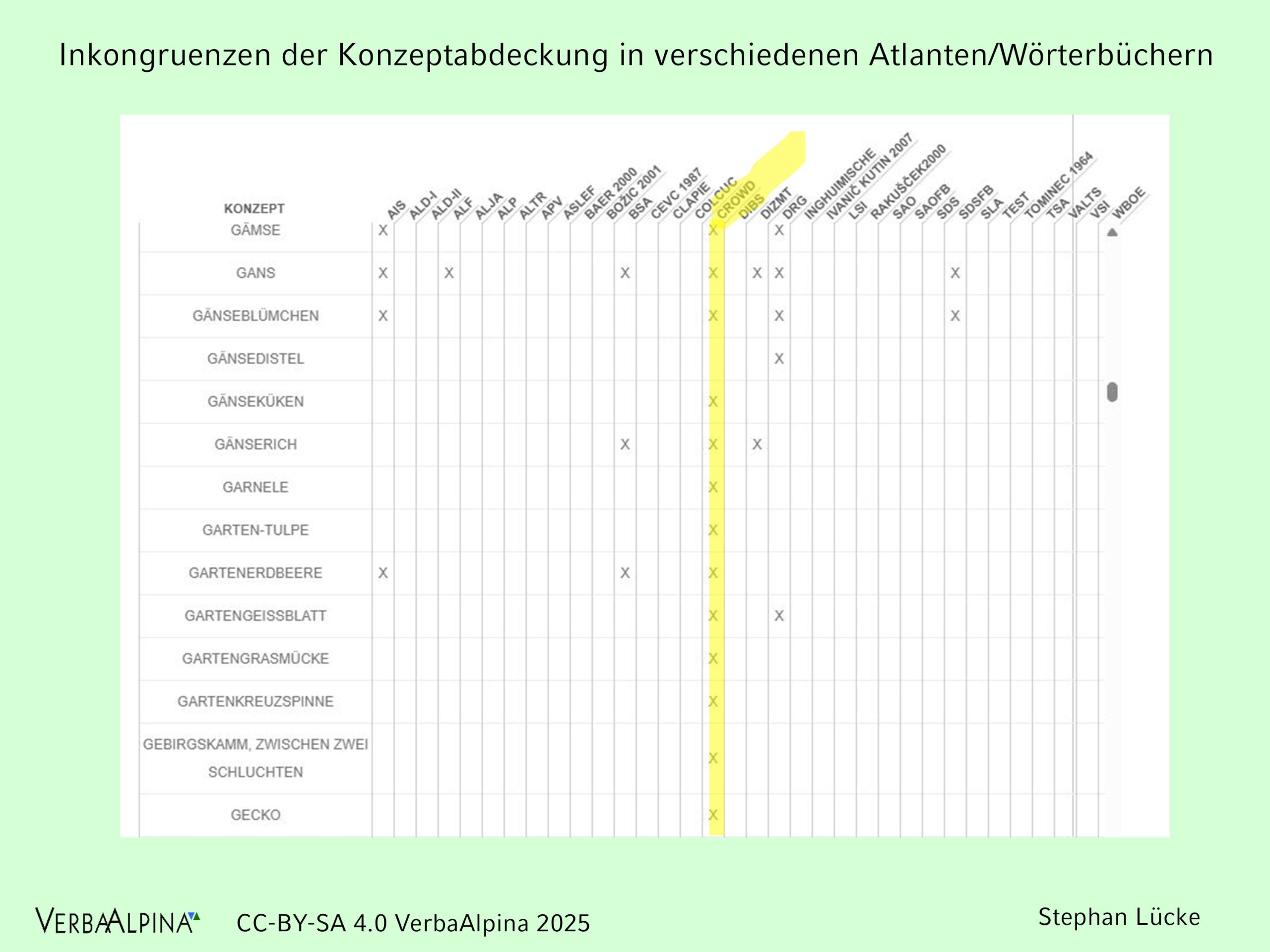
Illustration 4: Matrix der Konzeptabdeckung der verschiedenen Sprachatlanten und Wörterbücher (Link)
Traditionelle Sprachatlanten und Wörterbücher liefern aufgrund ihres in aller Regel vergleichsweise frühen Publikationsdatum praktisch keine Belege für die Konzeptdomänen der modernen Lebenswelt. Speziell hier kam dem Crowdsourcing besondere Bedeutung zu.

Illustration 5: Übersicht über die regionale Abdeckung durch die einzelnen Sprachatlanten und Wörterbücher. Für Teile Österreichs lagen während der Laufzeit von VerbaAlpina keine publizierten Sprachatlanten oder Wörterbücher vor (gelbe Markierung).
Die Nutzung von Digitalität und online-Technologie erlaubte eine vergleichsweise kostengünstige Form des Crowdsourcings. „Feldforschung“ im klassischen Sinne wäre aus finanziellen und Zeitgründen nicht durchführbar gewesen.

Folie 11
Das von VerbaAlpina entwickelte Crowdsouring Tool ist Teil des multifunktionalen Webportals gewesen. Im Wesentlichen sollte das Tool neue Bezeichnungen für die für VerbaAlpina relevanten Konzepte sammeln. Die 'Crowder' wurden aufgefordert, Wörter einzutragen, die an einem bestimmten auszuwählenden Ort zur Bezeichnung eines bestimmten Konzepts verwendet werden. Jeder Crowder musste außerdem seinen eigenen Dialekt benennen.

Illustration 6: Das VerbaAlpina-Crowdsouring-Tool, erreichbar unter https://www.verba-alpina.gwi.uni-muenchen.de/en/?page_id=1741 oder über den Link 'Mitmachen!' auf der Startseite des Webportals.
Entwickelt wurde das Tool von David Englmeier (Frontend) und Florian Zacherl (Backend). Es ist seit 2017 in Betrieb, der Softwarecode ist unter einer offenen Lizenz auf Github abruf- und nachnutzbar. Das 'responsive' Design erlaubt die Nutzung gleichermaßen auf PCs, Laptops, Tablets und Smartphones.
Die 'Crowder' wurden aufgefordert, über die Tastatur ein dialektales Lexem einzutragen, das ein vorgegebenes oder vom Crowder selbst ausgewähltes Konzept bezeichnet. In der entsprechenden Auswahlliste wurde für VerbaAlpina besonders wichtige Konzepte durch Ausrufezeichen hervorgehoben. Die Nutzer konnten aber frei entscheiden und auch neue Konzepte hinzufügen. Für jeden Eintrag musste ein Ort angegeben werden, an dem das entsprechende Lexem mit dieser Bedeutung nach Ansicht des Crowders verwendet wird. Vor der Eingabe von Sprachdaten, mussten die User sich selbst einen Dialekt zuweisen, den sie ihrer Meinung nach sprachen.
Ein 'Tutorial' beim 'Onboarding' half den Nutzern, die das Tool zum ersten Mal nutzten, beim Verständnis für dessen Bedienung. Dieses Tutorial kann jederzeit über einen Klick auf das entsprechende Symbol im rechten oberen Bildschirmeck aufgerufen werden.
Das Tool erlaubte eine freiwillige Registrierung. Registrierte Nutzer wurden von VerbaAlpina u.a. kontaktiert mit der Bitte, Werbung für das Tool zu machen. Außerdem wurden sie um die Evaluation des Tools gebeten. Von 2475 Crowdern haben sich 271, also etwas mehr als 10 Prozent, registriert. Die Eintragungen registrierter Nutzer flossen u.a. in die Bestenliste ein, die ein Ranking derjenigen Crowder mit den meisten Eintragungen lieferte. Es gab außerdem Listen, die die 'aktivste' Gemeinde oder das am häufigsten ausgewählte Konzept anzeigten.
Die Vitalität des Crowdsourcing-Tools wurde von VerbaAlpina fortlaufend überwacht. Dabei hat sich ein klarer Zusammenhang zwischen Publicity-Maßnahmen und einem Anstieg der Crowdsourcing-Aktivität gezeigt. In meinem Beispiel sieht man einen sprunghaften Anstieg nach einer Posting-Offensive auf Facebook Ende Dezember 2020. In den folgenden rund drei Wochen fanden zahlreiche Eintragungen statt, danach ebbte die Aktivität wieder ab.
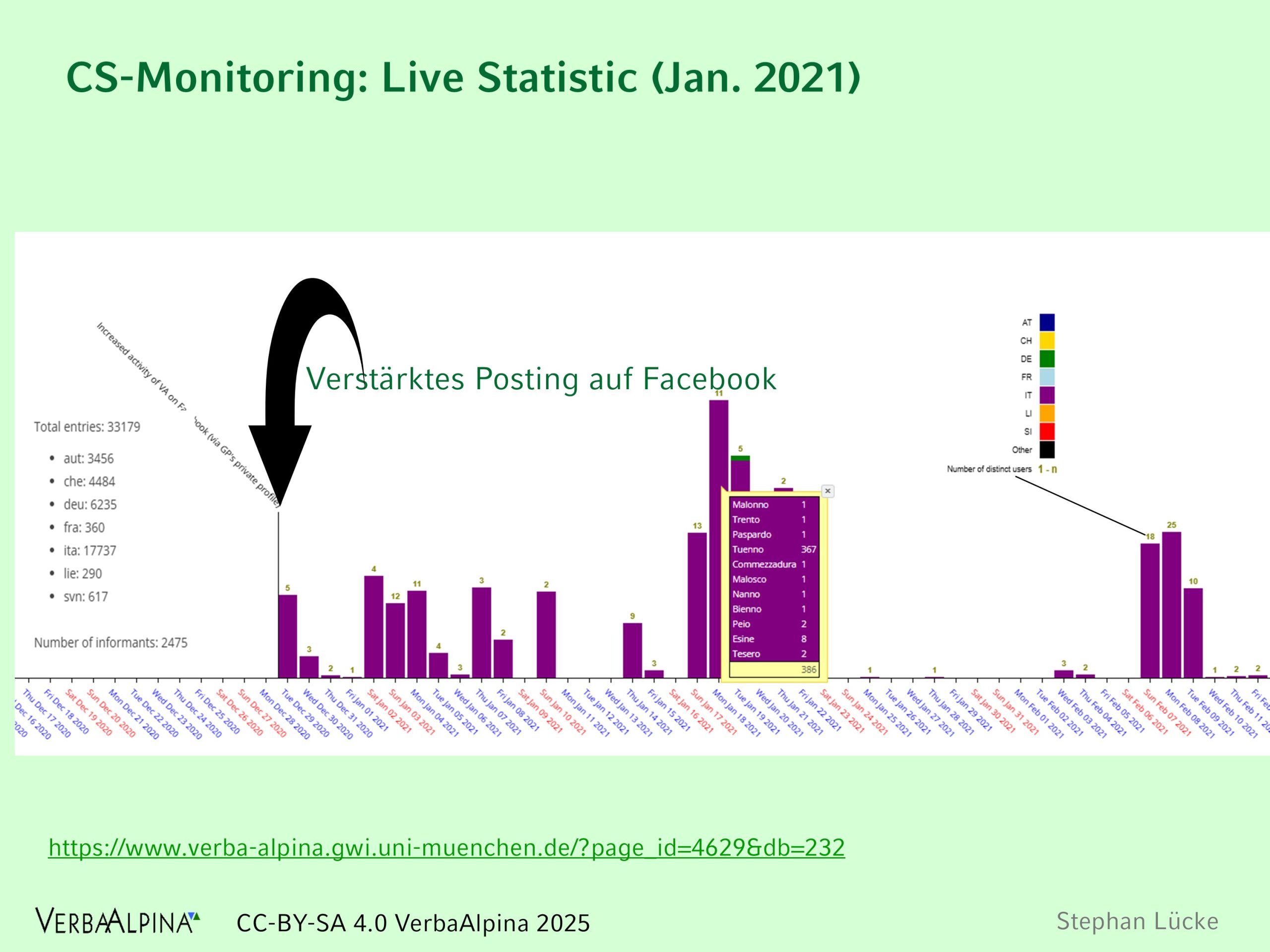
Illustration 7: Monitoring-Tool des Crowdsourcing-Fortschritts. Die Zeitachse zeigt tagesgenau die Anzahl der Eintragungen über das Crowdsourcing-Tool an. Die Herkunft der Crowder ist farblich markiert. Lila steht für Italien. Das Tool lässt einen Zusammenhang zwischen Publicity Aktionen und der Aktivität der Crowder erkennen.
Werbung für das Crowdsourcing war also ein ganz wesentlicher Faktor. Entsprechend wurde diese auf unterschiedlichen Kanälen betrieben. VerbaAlpina hat Kontakt zu Rundfunksendern und zur Presse gesucht. Es gab Interviews im Radio und in Podcasts (z. B. mit der Organisation CIPRA [Commission Internationale pour la Protection des Alpes] am 25.08.2021: https://www.cipra.org/de/news/sprechen-sie-alpen) und Beiträge in Zeitschriften, parallel wurde in den Sozialen Medien (Facebook, Instagram, Twitter, Youtube) Werbung gemacht. Zusätzlich existierte eine Liste mit insgesamt 4273 Kontakten, die gezielt angesprochen wurden, ob sie sich am Crowdsourcing beteiligen oder dafür Werbung machen wollen. Darunter befanden sich Zeitungen, Forschungs- und Kulturinstitute im Alpenraum, Almen, Tourismusverbände, Sennereien, Käsereien, Rundfunk (etwa Hitradio Ö3), Molkereien und Alpenvereine.
Den geringsten Effekt hatte die Verteilung von gedruckten Flyern, z.B. auf Alpenvereinshütten oder in Tourismusbüros im Alpenraum. Ein eigenes, von VerbaAlpina entwickeltes Werbevideo, das auf Youtube veröffentlicht wurde, wurde in den vergangenen acht Jahren gerade einmal 739 mal aufgerufen und kein einziges Mal kommentiert. Auch dies ist demnach und offenbar kein zielführender Weg.

Illustration 8: Maßnahmen zur Bewerbung des VerbaAlpina-Crowdsourcing-Tools (Folie: Colcuc / Mutter 2021)
 Illustration 9a: Deutschsprachiger Flyer aus dem Jahr 2019, der u. a. auf Alpenvereinshütten und in Tourismusbüros in Südtirol ausgelegt worden ist. |
 Illustration 9b: Post von VerbaAlpina auf Instagram zum internationalen Tag der Muttersprache am 21.2.2021 |
Das VerbAlpina-Crowdsourcingtool ist bis heute technisch funktionsfähig, wegen der ausgelaufenen Finanzierung werden eingegebene Daten aber nicht mehr in den Datenbestand von VerbaAlpina übernommen. Moderation, Evaluierung und Typisierung verlangen personellen Aufwand, der nun nicht mehr geleistet werden kann.

Folie 12
Insgesamt haben die 2475 Crowder über 33.000 Belege beigesteuert. Dabei stammen 50 Prozent der Belege von gerade einmal zehn Prozent der 'Crowder'. Es gab also eine kleine Anzahl sehr motivierter Teilnehmer, und einen vergleichsweisen hohen Anteil von weniger motivierten.
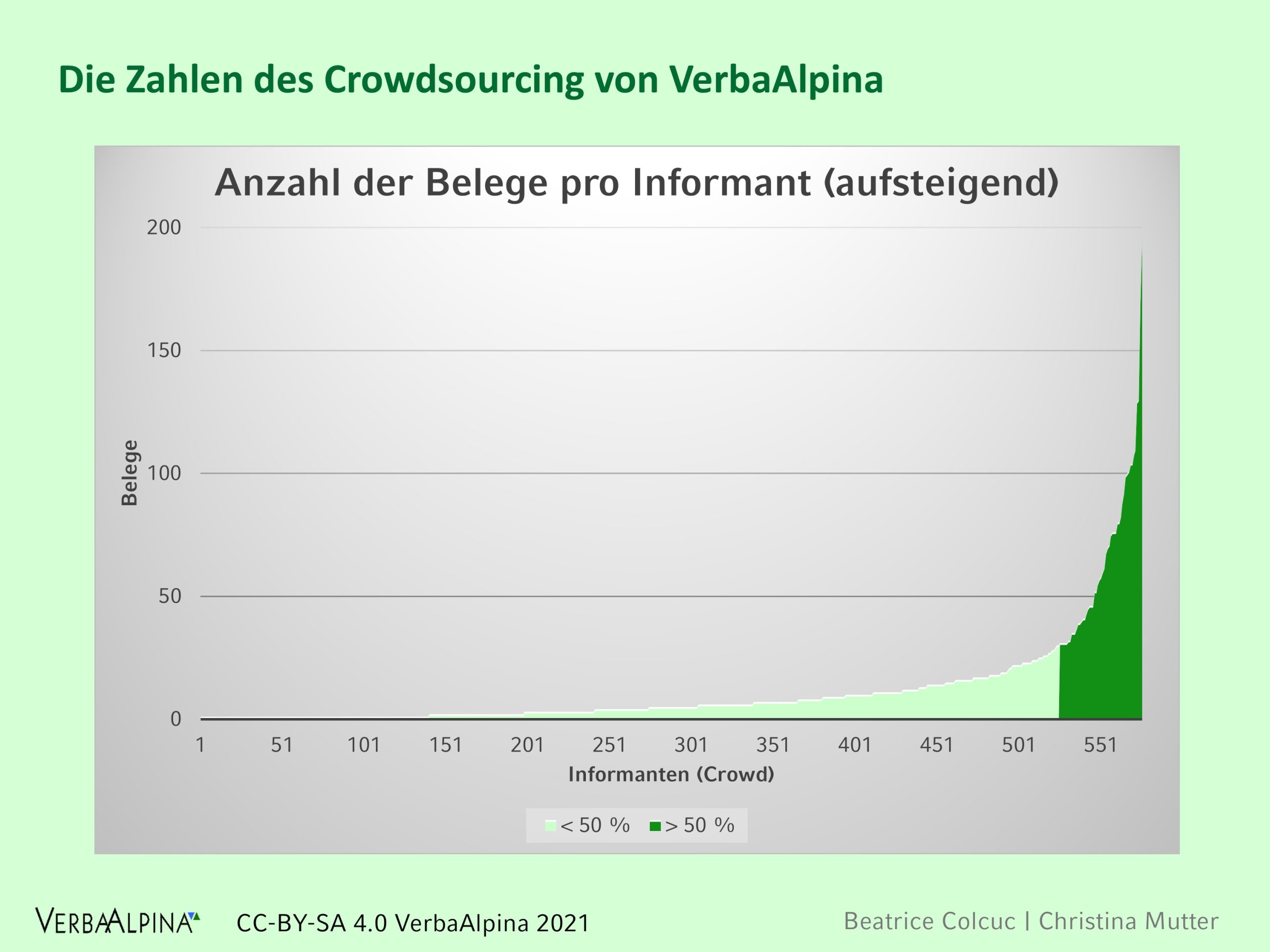
Illustration 10: Anzahl der Eintragungen pro Teilnehmer in das Crowdsourcing-Tool
Ein interessanter 'Beifang' des Crowdsourcings sind vereinzelte soziolinguistische Daten: So lassen die Crowdsourcingdaten erkennen, dass es Informanten gibt, die außerhalb der durch das italienische Sprachminderheitengesetz 482/99 vom 15. Dezember 1999 definierten Region des Ladinischen leben, ihren eigenen Dialekt jedoch dennoch als „Ladinisch“ bezeichnen.

Illustration 11: Ausdehnung des ladinischen Sprachgebiets gemäß italienischem Sprachminderheitengesetz 482/99 (rote Fläche) und Lokalisierung von 'Crowdern', die ihren eigenen Dialekt als "Ladinisch" bezeichnet haben (Punktmarkierungen).
In einem Fragebogen wurden die registrierten Crowder gefragt, was sie vom Crowdsourcing Tool halten. Der Rücklauf ist leider überschaubar gewesen, insgesamt haben nur 40 Angesprochene den Fragebogen ausgefüllt. Hier ein kurzer Einblick in die Auswertung:
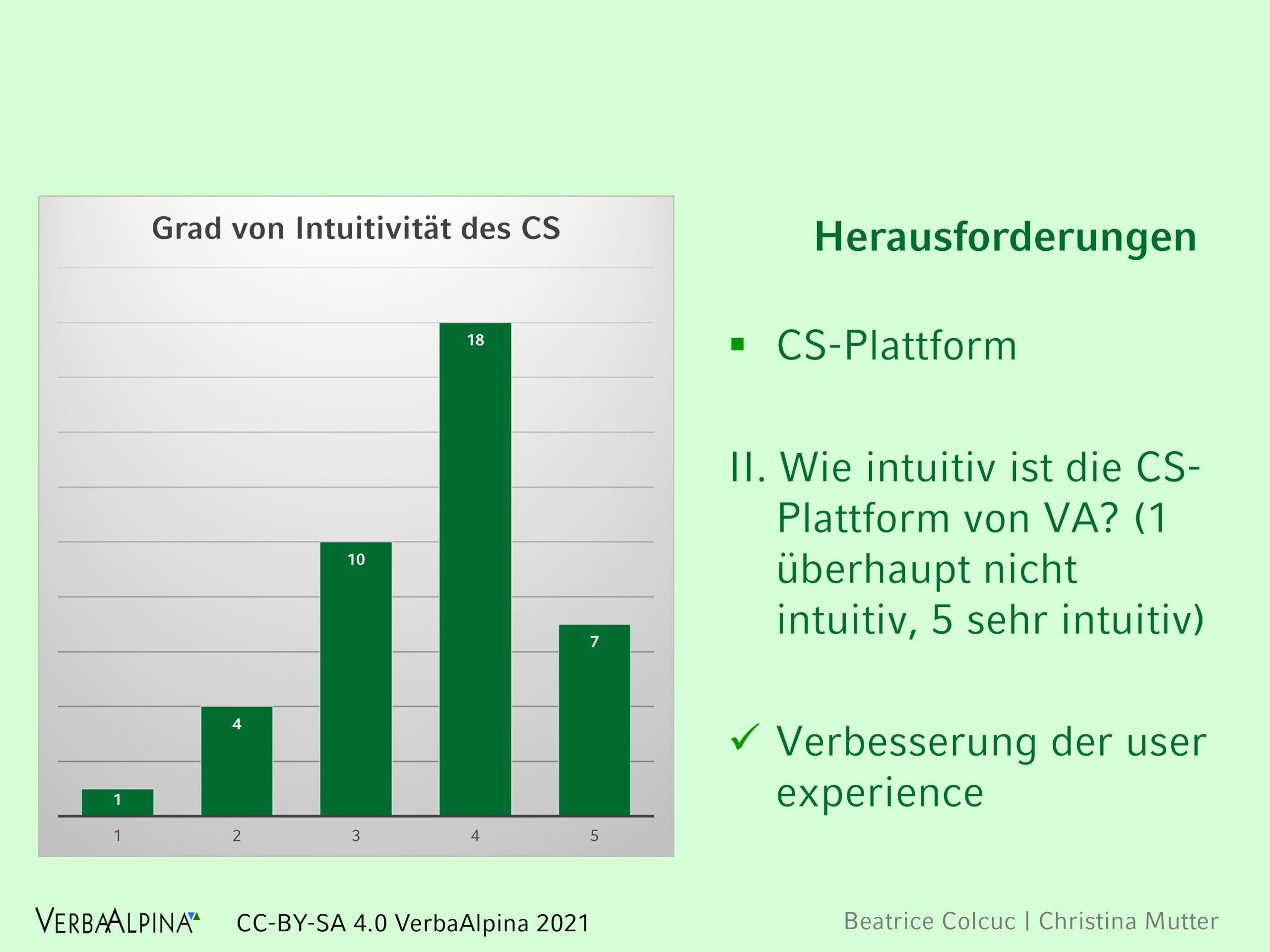
Illustration 12: Bewertung des Crowdsourcing-Interfaces durch registrierte Benutzer (n=40). Mehr als dreiviertel (31) der Antwortenden bewerteten die 'Intuivität', mit der das Tool genutzt werden kann, als gut oder sehr gut.

Illustration 13: Nur etwas mehr als die Hälfte der Antwortenden hat das Crowdsourcing-Tool weiterempfohlen.
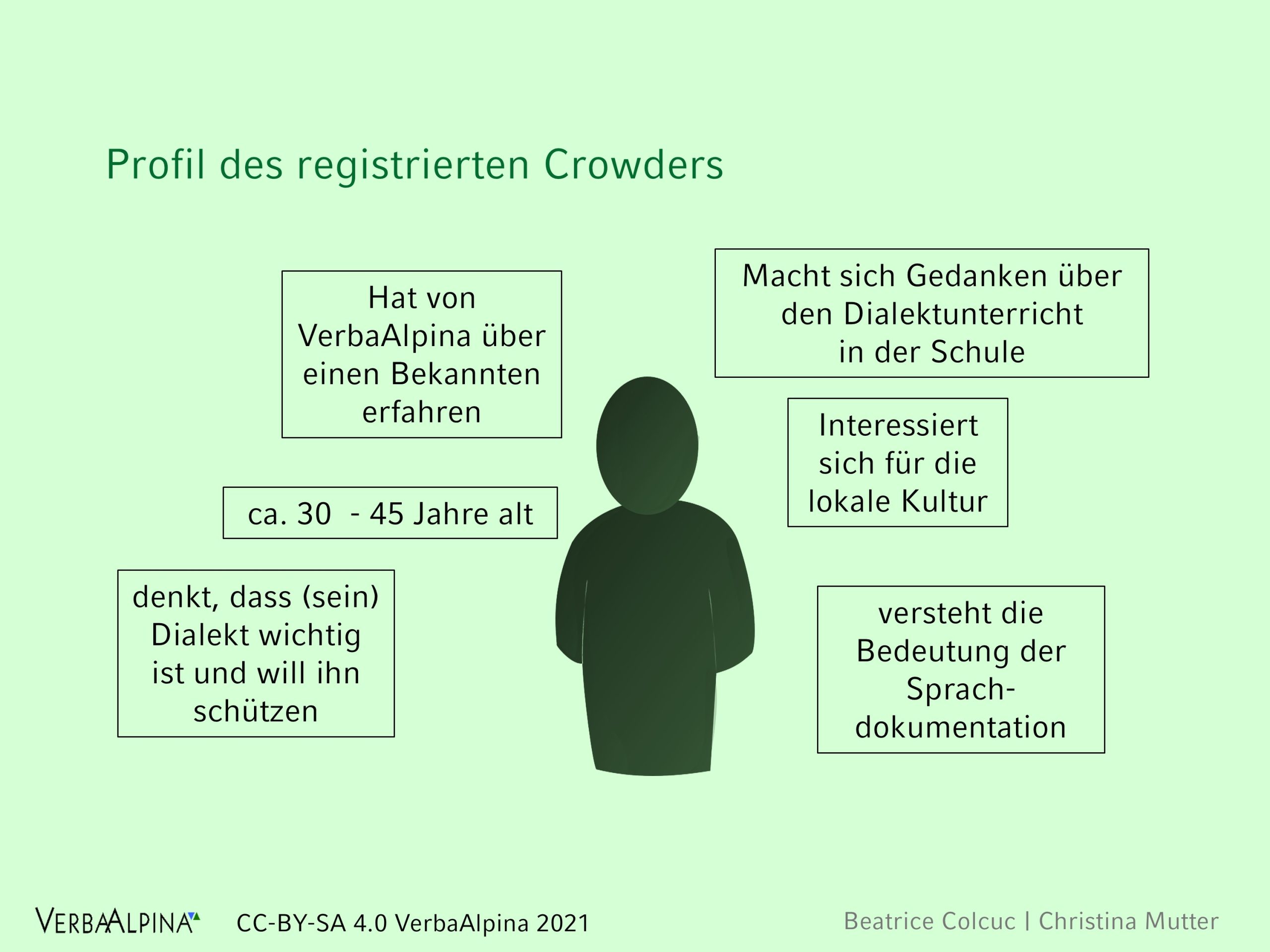
Illustration 14: Profil des registrierten Nutzers des VerbaAlpin-Crowdsourcing-Tools (Folie: Colcuc / Mutter 2021)
Vereinzelt gingen ausführlichere Nachrichten bei VerbaAlpina ein, die ein starkes Interesse an Sprache und Dialekt im Allgemeinen und darüberhinaus an VerbaAlpina erkennen ließen. Als Beispiel kann folgende Nachricht aus dem Jahr 2021 zitiert werden:
"Hallo, viele Namen und Begriffe aus meiner Kindheit im damaligen Pustertaler-Dialekt, gibt es heute nicht mehr. Habe über meine Tochter, Studentin an der genannten Hochschule, mitgemacht. Interessant: mein Gatte aus dem früheren Ober-Vinschgau, hatte eine ganz andere Muttersprache. Namen von Kräutern , Gegenständen..., sind für mich, als Pustertalerin außer einigen, verständlich. Mir gefallen Mundarten. Vinschgau verwendet z. B. die Fälle auf ganz besondere Art:
Ich habe mit ihr gesprochen. I hon mit sie parlart.
Sie hat mich gestraft. Sie hat mir kaschtigart.
Preiselbeeren heißen Glanen , im Pustertal Grantn. usw (So meine Schwiegermutter, geb. anno ###).
Herzliche Grüße aus ### ... " (aus dem VerbaAlpina-Protokoll 518, zum wöchentlichen Projekttreffen vom 24.2.2021)
Das zitierte Beispiel wirft ganz nebenbei auch ein Licht auf die grundsätzliche, häufig übersehene und im Englischen als "third mission" bezeichnete Aufgabe der Wissenschaft, ihre Erkenntnisse den einschlägig interessierten Teilen der Gesellschaft zur Verfügung zu stellen (s. Colcuc/Krefeld/Piva 2022). Im Fall des Crowdsourcing kann man in diesem Kontext von einer 'Rückspiegelung' sprechen: Die Ergebnisse der Analyse der von der 'Crowd' gelieferten Daten werden gleichsam als 'Dank' an sie zurückgegeben.

Folie 13
In der Rückschau lassen sich im Wesentlichen drei Probleme erkennen. Da wäre zunächst die regionale Asymmetrie: Die aktivisten Crowder stammten aus Italien, und dort vor allem aus Südtirol, dem Trentino und dem angrenzenden Veneto. Besonders schwach ist die Beteiligung in Frankreich gewesen. Dafür könnte eine ganze Reihe von Gründen verantwortlich gewesen sein: In Frankreich sind bekanntlich die Dialekte weitgehend verschwunden, außerdem leben in den französischen Alpen wohl viele ältere Leute, die erst im Ruhestand hierher gezogen sind. Das Interesse für Dialekte und deren Erforschung ist daher gering. Die schwache Beiteiligung aus Frankreich ist auch immer wieder Thema in den wöchentlichen Projekttreffen gewesen. In einem Protokoll vom 9.11.22 heißt es: "Belege aus Frankreich! (il faudrait marquer le coup)".
Eine Hilfskraft von VerbaAlpina mit französischen Wurzeln merkte bei einem Projekttreffen an (Protokoll 346 vom 22.7.2019):
"Für Frankreich stehen Francoprovencal und Occitan. Aber das Begriff francoprovencal ist eher aus der Sprachwissenschaft. Ich kann mich gut vorstellen das viele dortige Einwohner ihre Sprache nie so bezeichnen wurden. Zb meine Familie aus Chens sur Léman sagt chablaisien, könnten sich bei savoyard identifizieren, aber franco-provencal... sie kennen das Wort nicht wirklich. Ich glaube, dass bei Grenoble das Begriff Dauphinois auch passen könnte. Es ist nur eine Idee/Vorschlag. Aber es könnte helfen, mehr Beiträge aus Frankreich zu haben... Die Leute wählen eh danach eine Gemeinde. ..."
In der Folge wurden "Savoyard" und "Chablaisien" in beim Start des Crowdsourcing-Tools angezeigte Liste auswählbarer Dialekte aufgenommen. Eine Steigerung der Teilnahme aus Frankreich war danach leider auch nicht feststellbar.
Die Priorisierung der Crowdsourcingkontakte in Frankreich erfolgte bereits sehr früh, gegen Ende 2017, als erkennbar wurde, dass die Beteiligung in Frankreich ein Problem darstellte.
Mit der geringen Beteiligung aus Frankreich kontrastierte die von Anfang an auffällig hohe Teilnahme in Italien. Dabei mag freilich auch eine Rolle gespielt haben, dass die italienischen Bewohner des von der Alpenkonvention definierten Territoriums der Alpen verglichen mit den anderen Staaten Anrainerstaaten überproportional hoch ist: In Italien leben über 30 Prozent der insgesamt über 14 Millionen Einwohner des Alpenraums (Kunzmann/Zacherl 2017, Folie 12). Ein anderer Faktor könnte das in Italien generell große Interesse an persönlicher kultureller Identität und somit auch am eigenen Dialekt gewesen sein. Und schließlich dürfte sich ausgewirkt haben, dass eine Projektmitarbeiterin aus dem italienischen Alpenraum stammte und u. a. ihre persönlichen Kontakte aktiviert hat, um das Crowdsourcing-Vorhaben von VerbaAlpina zu propagieren.

Illustration 15: Herkunft der Teilnehmer am Crowdsourcing gruppiert nach Ländern.
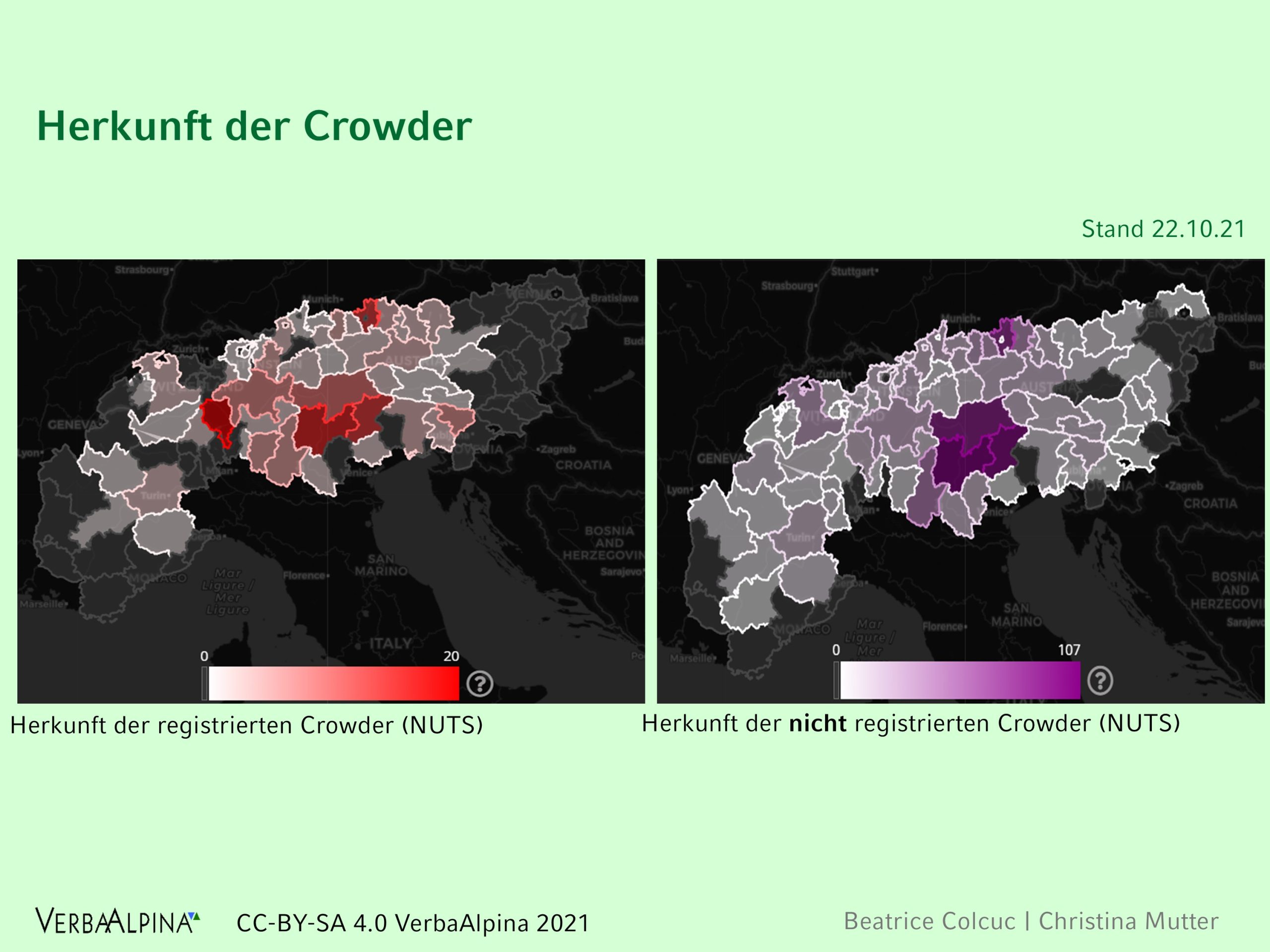
Illustration 16: Kartierung der Herkunft der Teilnehmer am Crowdsourcing bezogen auf die statistischen NUTS3-Einheiten der Europäischen Union (in Deutschland die Landkreise).
Ein weiteres Problem ist das Altersprofil der Personen, die man über die neuen Medien erreichen kann. So waren 2021 über 60 % der Instagram User zwischen 18 und 34 Jahre alt, nur 3 % über 60. Bei der Bewertung der eingehobenen Sprachdaten spielt dies natürlich eine Rolle. Das tatsächliche Alter der Crowd-Informanten ist VerbaAlpina nur in wenigen Ausnahmefällen bekannt.
Problematisch ist schließlich die Verlässlichkeit der eingehobenen Sprachdaten. Zur Bewertung der Daten bietet sich grundsätzlich ein Abgleich mit dem Material aus Atlanten an. Freilich ist dies gerade bei bislang noch nicht belegten Wörtern, die ja gerade einen Mehrwert des Crowdsourcing darstellen, eine Sackgasse. Eine Bestätigung kann ein Eintrag durch Mehrfachbezeugung durch andere Crowder erfahren. Das Motto lautet: Einmal ist keinmal, zweimal ist immer.
Ein sog. „Priming“, also eine Übereinstimmung von Stimulus und Beleg, konnte bei rund 5 % der Belege beobachtet werden, wobei hier Unterschiede in Bezug auf die verschiedenen Konzeptdomänen vorlagen.

Folie 14
Annotation der gesammelten Sprachdaten

Folie 15
Die Crowd-Daten wurden vom VerbaAlpina-Team verarbeitet. Eine ganz wesentliche Annotation war ja bereits bei der Dateneingabe durch den Crowder selbst erfolgt, nämlich die Zuordnung eines Wortes zur einem Konzept und einer Gemeinde. Die Eingabe der Dialektausdrücke erfolgte natürlich nicht in Standardorthographie, was zu einer hohen Variation an Schreibweisen führte. Die wichtigste Aufgabe des VerbaAlpina-Teams war es demnach, die Belege jeweils bestimmten morpholexikalischen Typen zuzuweisen. Im Fall etwa von „Kaas“ wurde dies dem Typ Käse zugeordnet. Für diese Arbeit wurde von VerbaAlpina ein spezielles Typisierungstool entwickelt, dessen Funktionsweise der folgende Screenshot illustriert.
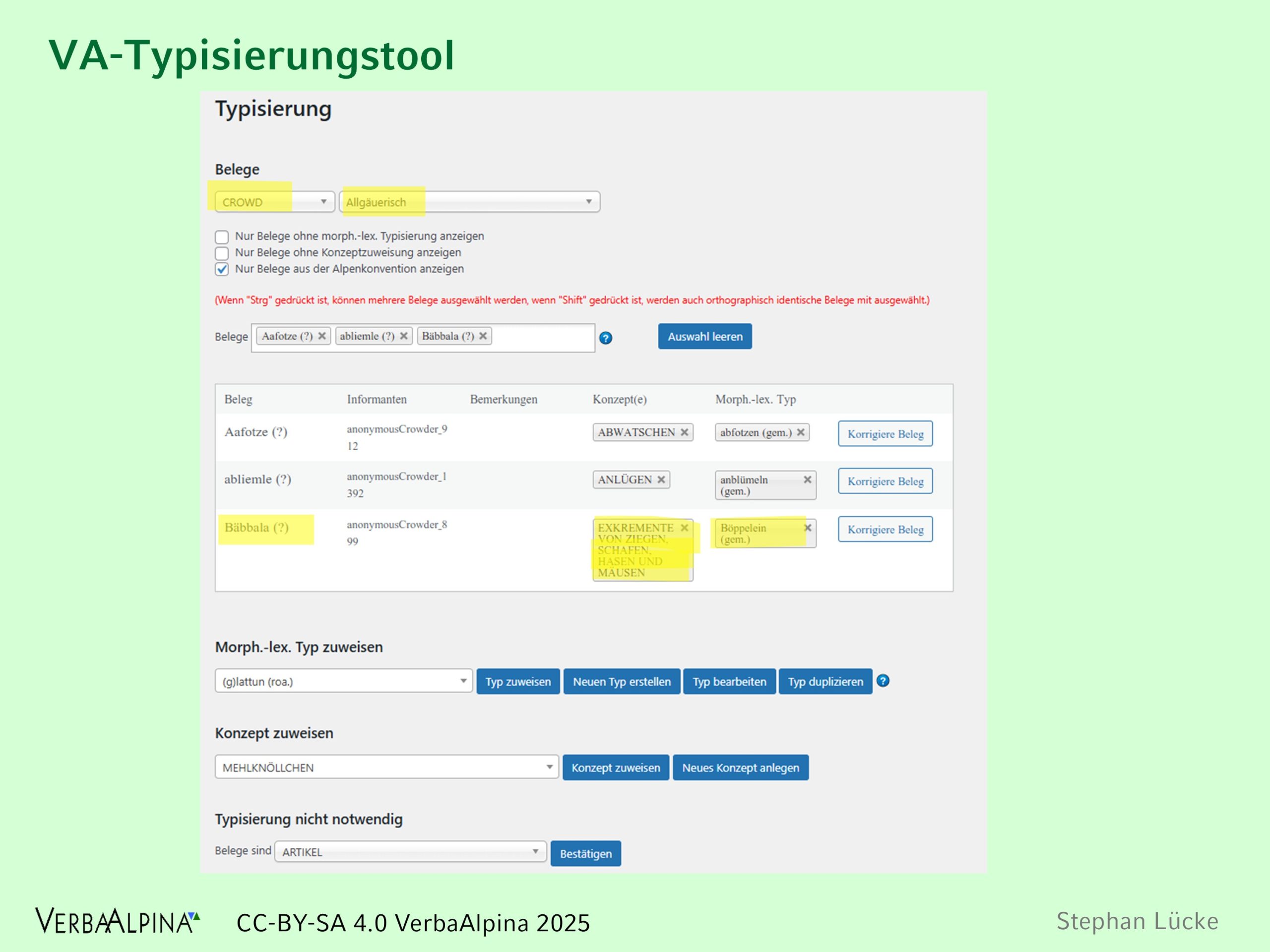
Illustration 17: Das VerbaAlpina-Typisierungstool. Es erlaubt die Auswahl einer bestimmten Erhebung, in diesem Beispiel ist dies die Crowd. Zusätzlich kann eine Filterung nach den von den Crowdern angegebenen Dialektzuordnung erfolgen. Im vorliegenden Beispiel wurde der Beleg „Bäbbala“, ein Wort zur Bezeichnung der EXKREMENTE VON ZIEGEN, SCHAFEN, HASEN UND MÄUSEN, dem in Lexika (z. B. dem Idiotikon) nachgewiesenen Lemma „Böppelein“ zugewiesen.
Bei Abschluss des Projekts waren 96% der von den Crowdern eingegebenen Wörter typisiert (s. Reiter "Typisierung" auf der Seite "Fortschritt")
Als „Annotation“ kann schließlich noch die automatische Vergabe von Identifikatoren betrachtet werden. Bei diesen Identifikatoren handelt es sich schlicht um Nummern, die z.B. einen morpholexikalischen Typ im VerbaAlpina-Korpus eindeutig identifiziert. Solche Nummern werden auch als Normdaten bezeichnet.
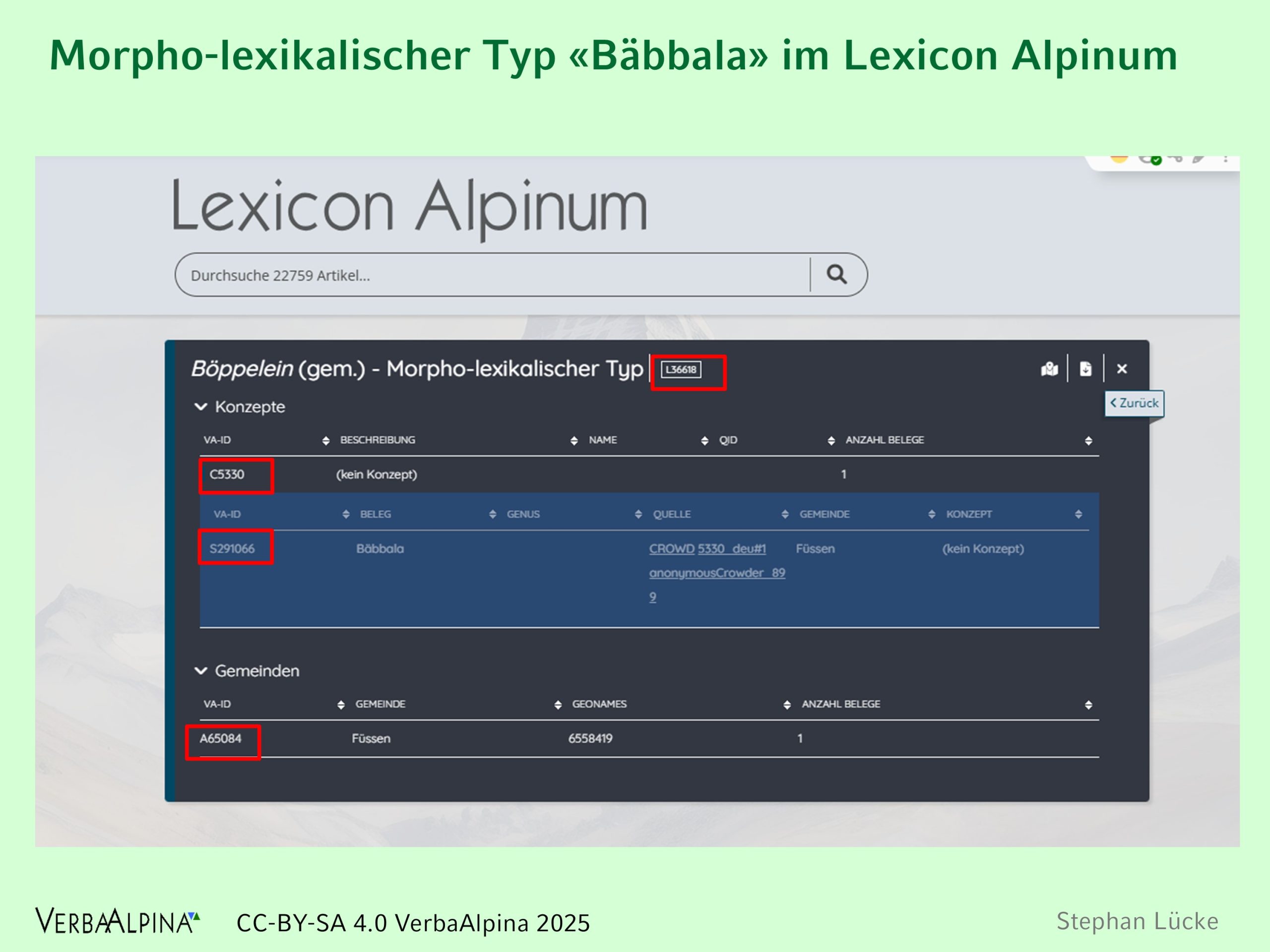
Illustration 18: Eintrag "Böppelein" im Lexicon Alpinum. Die von VerbaAlpina vergebenen Identifikatoren für morpholexikalische Typen, Konzepte, Einzelbelege und Ortschaften sind rot markiert.

Folie 16
Nutzbarmachung der Sprachdaten

Folie 17
Zur Nutzbarmachung der Daten müssen diese primär dauerhaft und verlässlich zugänglich sein. Die VerbaAlpina-Daten waren bereits während der Projektlaufzeit auf dem Webportal von VerbaAlpina verfügbar. Das zentrale Visualisierungsinstrument war und ist die interaktive Online-Karte. Dort kann die geographische Verteilung ausgewählter Daten abgebildet werden.

Illustration 19: Kartierung der Bezeichnungen für das Konzept "EXKREMENTE VON ZIEGEN, SCHAFEN, HASEN UND MÄUSEN" auf der interaktiven online-Karte. Das geöffnete Infofenster zeigt den Beleg für den morpholexikalischen Typ "Bäbbala". Andere auf der Karte dargestellte Belege entstammen den traditionellen Sprachatlanten und/oder Wörterbüchern.
Einen eher wörterbuchähnlichen Zugang bietet das Lexicon Alpinum (s. oben Illustration 18). Beide Schnittstellen greifen auf den selben Datenbestand zu.
Stabile direct links, die sowohl auf der Karte wie auch im Lexicon verfügbar sind, erlauben eine feingranulare Adressierung der Elemente des Datenbestands.
Über die API können die Daten in unterschiedlichen Formaten in strukturierter Form heruntergeladen werden.
Problematisch ist die Aufrechterhaltung der Funktionalität des Webportals. Die ITG der LMU pflegt das Portal solange, wie dies technisch und personell möglich ist. Eine Garantie für eine unbefristete Verfügbarkeit kann aber nicht gegeben werden. Aus diesem Grund wurde der Datenbestand zusätzlich auf Ressourcen der UB der LMU übertragen (strukturierte Forschungsdaten: Discover@LMU; strukturierte und diskursive Daten auf OPEN DATA LMU). Dort sind sie in einer Art „eingefrorenem“ Zustand, will heißen: ohne die interaktiven Optionen des Webportals, sehr wahrscheinlich zeitlich unbegrenzt verfügbar. Die feine Granulierung des Datenbestands ist auch dort gegeben, und einzelne Elemente können über stabile Identifikatoren wie z.B. DOIs adressiert werden.

Folie 18
Für die Nutzbarmachung der Daten im wissenschaftlichen Sinn ist Stabilität unerlässlich. Eine einmal erzeugte Referenz muss stets zuverlässig auf dieselben Daten verweisen. Um dies zu gewährleisten hatte VerbaAlpina von Anfang an ein Versionierungskonzept umgesetzt. Alle halbe Jahre wurde der Datenbestand eingefroren. Auf diese Weise wurde Zitierfähigkeit erreicht.
Die API von VerbaAlpina erlaubt den Datendownload in den Formaten csv, xml und json. Aus dem Repositorium der UB kann außerdem ein SQL-Dump der strukturierten Daten heruntergeladen werden.
Unerlässlich ist eine offene Lizenz, die die Nachnutzung der Daten nicht einschränkt. VerbaAlpina hat sich für die CC BY-SA Lizenz entschieden.
Ziel von VerbaAlpina ist es gewesen, die eigenen Daten in Übereinstimmung mit den sog. FAIR-Prinzipien zugänglich und nachnutzbar zu machen (s. Englmeier/Lücke 2023). Die soeben dargelegten Entscheidungen, Maßnahmen und Entwicklungen tragen genau dazu bei.
Nebenbei sei hier noch erwähnt, dass abseits der sprachlichen Kerndaten des Projekts, in einem überschaubaren Ausmaß, auch die Nachnutzung der von VerbaAlpina entwickelten Technologie(n) erfolgte. Zu nennen wäre in diesem Zusammenhang etwa das Projekt "Atlas pan-picard informatisé" (APPI) an der Universität Lille, das, anscheinend leider nur vorübergehend, die interaktive online-Karte von VerbaAlpina verwendet hat. Speziell die Kartentechnologie wird bis heute auch vom "Atlante linguistico della Sicilia" (ALS) eingesetzt (Link). Erst vor kurzem bekundete das Projekt "Morphosyntactic Atlas of Gascony" (MAGY; Paciaroni 2019) Interesse an der Nutzung des VerbaAlpina-Transkriptionstools. Es ist also nicht ausgeschlossen, dass auch künftig eine Nachfrage der Nachnutzung einzelner von VerbaAlpina entwickelter Softwarelösungen bzw. der dahinter stehenden Konzepte entstehen wird.

Illustration 20: Interaktive Karte des Projekts "Atlas pan-picard informatisé" (APPI) (Universität Lille), die auf der Technologie von VerbaAlpina basiert (Link; Abruf am 8.12.2025)

Folie 19
VerbaAlpina und KI?

Folie 20
Grundsätzlich ist festzuhalten, dass während der Projektlaufzeit KI so gut wie keine Rolle gespielt hat. Ganz stimmt das allerdings nicht: Das Titelbild der letzten VerbaAlpina-Version ist mit Hilfe des KI-Bildgenerierungstools „Midjourney“ erzeugt worden.

Illustration 21: Das mit der KI-Anwendung "Midjourney" generierte Titelbild der Version 232 von VerbaAlpina. Es ist unschwer zu erkennen, wodurch die KI inspiriert gewesen ist: Das Matterhorn.
Jenseits dieser 'Spielerei' kann man sich aus heutiger Sicht folgende Nutzungsszenarien der KI vorstellen:
Die KI könnte unterstützend bei der Typisierung von Belegen aus der Crowd eingesetzt werden. Sie könnte Vorschläge für Typzuordnungen machen, die dann von Experten bestätigt oder verworfen werden würden. Im Zuge dieses Verfahrens wäre auch ein Lernprozess der KI vorstellbar.
KI könnte ferner für das automatische Bespielen von Social Media Kanälen eingesetzt werden. Prompts könnten aus Stichwörtern der jeweils aktuellen Dateneingaben generiert werden.
Grundsätzlich würde man KI natürlich auch bei der Entwicklung und Pflege der zahlreichen Werkzeuge, die für die tägliche Arbeit unerlässlich sind, einsetzen. Speziell die automatische Erfassung der Karten von Sprachatlanten wie dem AIS könnte möglicherweise durch die KI deutlich vereinfacht und beschleunigt werden. Im Fall des AIS besteht das zentrale Problem bei der automatischen Datenerfassung darin, dass bislang die Zuordnung der direkt auf der Karte eingetragenen Sprachbelege zu den jeweils zugehörigen, durch rote Zahlen markierten Erhebungspunkten scheitert. Die Erkenntnisse einer einschlägigen, verdienstvollen Masterarbeit (Nguyen 2019), die sich diesem Thema gewidmet hat, führten in der Folge nicht zur Entwicklung eines praxistauglichen Softwarewerkzeugs.
Denkbar wäre auch noch die Identifizierung von 'verdächtigen' Eintragungen durch die Crowd, also etwa die Eintragung von Typen für Regionen, in denen deren Verbreitung eher unwahrscheinlich wäre.
Zu testen wäre die Möglichkeit, die KI 'tracken' zu lassen, von wem das Projekt VerbaAlpina im Allgemeinen und sein Crowdsourcing-Tool im Speziellen zitiert wird, und anschließend eine automatische Kontaktaufnahme initiieren zu lassen mit dem Ziel, die Rezeption und Breitenwirkung von Projekt und Crowdsourcing-Tool weiter zu intensivieren.
* * *
VerbaAlpina-Publikationen zum Thema Crowdsourcing (chronologisch geordnet)
- Fiori, Stefano (2023): Strategie di resa grafica delle consonanti palatali nei contributi crowd del database VerbaAlpina (Link)
- Colcuc, Beatrice / Rodella, Anna (2022): Con parole tue: dai parlanti a VerbaAlpina attraverso il crowdsourcing, in: apropos [Perspektiven auf die Romania], vol. 9, 187-212 (Link)
- Colcuc, B. (2023): s.v. “Soziale Netzwerke”, in: VerbaAlpina-de 23/2 (Erstellt: 20/2), Methodologie, https://doi.org/10.5282/verba-alpina?urlappend=%3Fpage_id%3D493%26db%3D232%26single%3DM192
- Grimaldi, Giorgia (2016): "Come dici...?" Crowdsourcing-Pretest für VerbaAlpina mittels einer App/mobilen Website, München [Bachelorarbeit] (Link)
- Wiatr, Aleksander (2016): Bedeutung und Funktion von Crowdsourcing im Projekt VerbaAlpina, Ljubljana, in: Jezikovni zapiski, vol. 22/2, ZRC SAZU, 161-175 (Link)
Crowdsourcing in Beiträgen von VerbaAlpina auf Tagungen und Workshops
- 2017 (2x: 19. Arbeitstagung zur alemannischen Dialektologie, Freiburg; dha2017 – Digital Humanities Austria, Innsbruck),
- 2021 (2x: XXXVII. Romanistentag in Augsburg; Workshop "Neue Wege der romanischen Geolinguistik Vers. 2.0 (2021)", Schneefernerhaus)
Bibliographie
- AIS = Jaberg, Karl / Jud, Jakob (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz, Zofingen, vol. 1-7.
- ALS = Ruffino, Giovanni, ed. (1995-): Atlante linguistico della Sicilia (ALS). Palermo: Centro di studi filologici e linguistici siciliani.
- Colcuc/Krefeld/Piva 2022 = Colcuc, Beatrice / Krefeld, Thomas / Piva, Rebekka (2023): s.v. “Dialekt”, in: VerbaAlpina-de 23/2 (Erstellt: 22/1), Methodologie (Link).
- Colcuc/Mutter 2021 = Colcuc, Beatrice / Mutter, Christina (2021): Crowdsourcing als Instrument geolinguistischer Forschung im Projekt VerbaAlpina. Ein Werkstattbericht. Workshop "Neue Wege der romanischen Geolinguistik, Vers. 2.0 (2021)", Umweltforschungsstation, Schneefernerhaus (Zugspitze), 5/11/2021 (Link).
- Englmeier/Lücke 2023 = Englmeier, David / Lücke, Stephan (2023): s.v. “FAIR-Prinzipien”, in: VerbaAlpina-de 23/2 (Erstellt: 18/2), Methodologie (Link).
- Idiotikon = Schweizerisches Idiotikon. Schweizerdeutsches Wörterbuch, Basel, 1881- (Link).
- Kunzmann/Zacherl 2017 = Datengewinnung mittels Crowdsourcing im Dienste der Sprachwissenschaft. Die virtuelle Forschungsumgebung VerbaAlpina. Vortrag auf dem Treffen "Digital Humanities Austria 2017", 4.-6. Dezember 2017, Innsbruck (Link).
- Nguyen 2019 = Nguyen, Manh Duy (2019): Processing of Historical Phonetic Maps using Computer Vision and Deep Learning, München (Masterarbeit) (Link).
- Paciaroni 2019 = Paciaroni, Tania (2019): Morphosyntactic Atlas of Gascony (MAGY). (Link; Zugriff am 8. Dezember 2025).