

Projektpräsentation im Rahmen des Orientierungsmoduls, BA Italianistik, LMU, 17.1.2017
Übersicht
Vorbemerkung: Forschung und Medien – nach der 2. medialen Revolution
Zur Konzeption
Funktionsbereich (1): Dokumentation
Funktionsbereich (2): Kooperation
Funktionsbereich (3): Publikation
Funktionsbereich (4): Datenerhebung durch Crowdsourcing
Funktionsbereich (5): virtuelles Forschungslabor
Zur Konzeption
Die Raumorientierung
VerbaAlpina (VA) dokumentiert die dialektale Variation innerhalb eines ethnographisch (und weder sprachlich noch national) definierten Raums, und genau in diesem Sinne ist die Konzeption durchaus ethnolinguistisch; aus rein pragmatischen Gründen wird das Untersuchungsgebiet mit dem Geltungsbereich der so genannten Alpenkonvention gleichgesetzt.
Im Vordergrund steht das Lexikon, und der onomasiologische Rahmen für die Selektion des projektrelevanten Ausschnitts wird durch kulturelle Techniken und Lebensformen abgesteckt, die sich unter den jeweils spezifischen, auch kulturunabhängigen Umweltbedingungen konventionalisiert haben. Dergleichen Räume, die durch die Alpen in prototypischer Weise repräsentiert werden, konnten die sprachwissenschaftlichen Forschungstraditionen nicht angemessen erfassen, da sich die Teildisziplinen, die sich systematisch mit der Konstitution von Räumen beschäftigen – also die Sprachgeographie, bzw. Dialektologie oder auch Geolinguistik – beinahe ausnahmslos an vorgegebenen politischen und/oder (einzel)sprachlichen Grenzen orientieren. Der räumliche Zuschnitt zentraler und in mancher Hinsicht bis heute maßgeblicher Unternehmungen ist zwar nachzuvollziehen (vgl. etwa den AIS und das FEW) – zustimmen mag man jedoch oft nicht. Gerade die besonders faszinierenden mehrsprachigen Kulturräume, also z.B. die Pyrenäen, Korsika und Sardinien im Verbund oder aber das Gebiet zwischen der montenegrinisch-albanischen Adriaküste und der Donau, fallen daher durch das Raster der etablierten, durch nationalphilologische Voreinstellungen gesteuerten Forschung. Der ambitioniert geplante Atlante linguistico mediterraneo hätte ein richtungweisendes Großprojekt werden können; er ist jedoch über Ansätze niemals hinausgekommen.
VerbaAlpina zielt auf den Alpenraum; das Projekt will aber weder Sprach- noch Dialektgrenzen herausarbeiten (vgl. Auer 2004) und keineswegs das Mosaik gegeneinander abgegrenzter Varietäten (Dialekte) abbilden. Vielmehr wird eine Interlinguale Geolinguistik entwickelt, die untersucht, inwieweit spezifische Varianten, nämlich die für den alpinen Kulturraum charakteristischen Bezeichnungstypen, gerade den Dialekten gemeinsam sind und sie womöglich über die Grenzen der Sprachfamilien hinaus verbinden. Die relative Änlichkeit der lokalen Dialekte ergibt sich induktiv aus den Daten selbst. Die einzige vorgegebene Gliederung des Alpenraums, die der Kartographie von vornherein unterlegt wird, betrifft die aktuellen Grenzen zwischen den drei großen Sprachfamilien (Germanisch, Romanisch, Slawisch).
Perspektive
Die Verteilung der Varianten in diesen dialektalen Großräumen impliziert vielfältige, mehr oder weniger weit zurückliegende Kontaktbeziehungen; daher kann die übergreifende Perspektive des Projekts nur eine historische sein. Im Blick auf den skizzierten Untersuchungsraum versteht sich VerbaAlpina allerdings nicht als Beitrag zur nationalen Sprachgeschichtsschreibung der involvierten Sprachen, sondern als Versuch, die Stratigraphie eines mehrsprachigen kommunikativen Raums exemplarisch zu rekonstruieren.
Dabei wird ausschließlich bottom up verfahren, das heißt auf Grundlage von Daten, die lokal georeferenzierbar sind. Die minimale und by default geltende Referenzeinheit ist die politische Gemeinde, genauer gesagt ein Geopunkt, der die Gemeinde als ganze repräsentiert, oder aber die gesamte Gemeindefläche. Im Bedarfsfall kann die Georeferenzierung jedoch einerseits bis auf wenige Meter präzisiert oder aber, andererseits, regional erweitert werden: die Präzisierung gestattet grundsätzlich (mikro)toponomastische Anwendungen und die regionale Zusammenfassung erlaubt insbesondere in quantitativer Hinsicht nützliche synthetische Darstellungen.
Die Fundierung in Webtechnologie
VerbaAlpina kann als eine webbasierte Forschungsumgebung beschrieben werden, die in den digital humanities angesiedelt ist. Dieses Format wird bestimmt durch die aktuellen Rahmenbedingungen, die sich ganz erheblich von der traditionellen Wissenschaftskommunikation unterscheiden. So eröffnen sich in ganz selbstverständlicher Weise fünf unterschiedliche, aber eng miteinander verflochtene Funktionsbereiche angelegt.
Funktionsbereich (1): Dokumentation
Das Untersuchungsgebiet von VerbaAlpina erscheint in geolinguistischer Hinsicht auf den ersten Blick gut erschlossen. Allerdings klafft im zentralen und östlichen Teil Österreichs eine gewaltige Datenlücke.
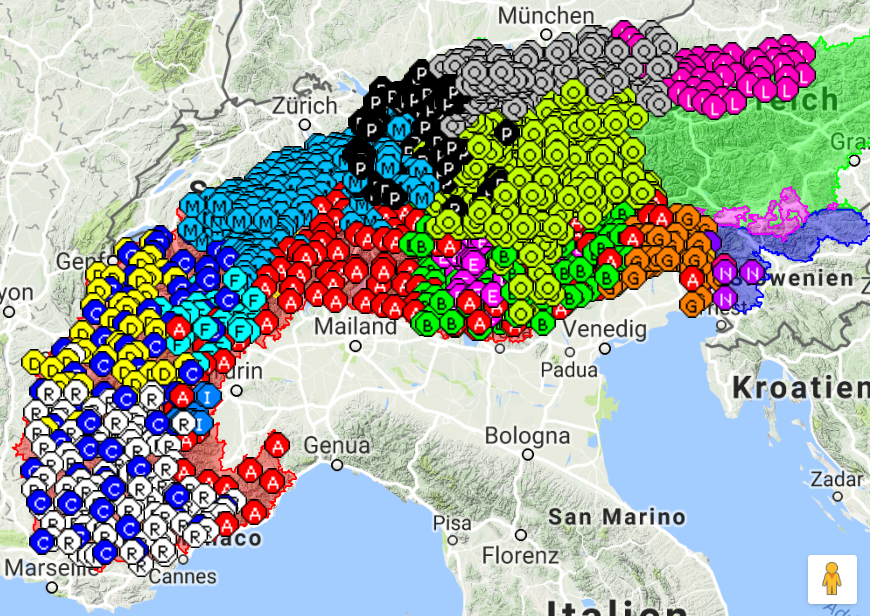
Karte 1: Erschließung des alpinen Sprachraums durch Atlanten
Durch Berücksichtigung der Daten des WBÖ, die ja größtenteils lokal erhoben wurden, kann diese Lücke bis zu einem gewissen Grad nun geschlossen werden. Die folgende Karte zeigt, dass alle Erhebungsorte des WBÖ inzwischen georeferenziert wurden, so dass bald Wörterbuchdaten aufgenommen werden können; VerbaAlpina wird jedoch die literarischen Belege des WBÖ systematisch ausblenden.
Karte 2: Erhebungsnetz des WBÖ
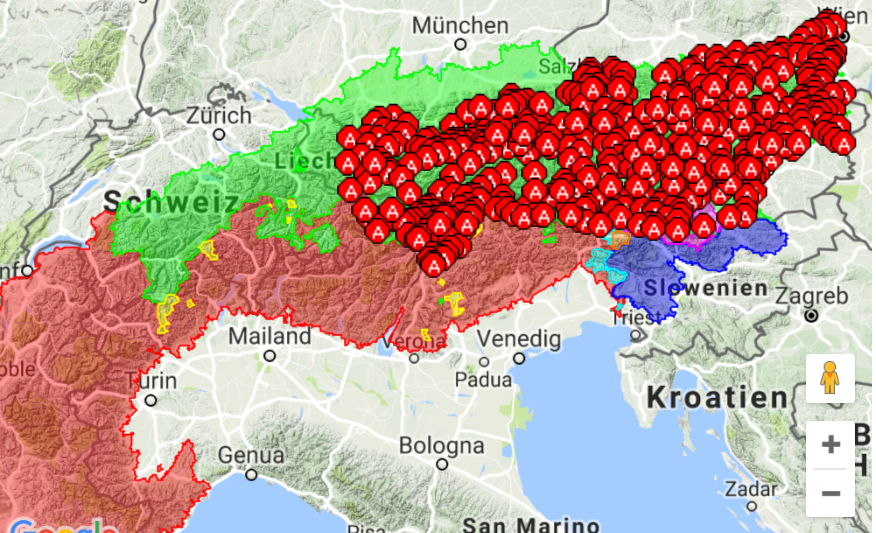
Bei genauerem Hinsehen sind die Verhältnisse allerdings einigermaßen ernüchternd; die folgende, mit dem quantitativen Kartierungstool von VerbaAlpina erzeugte Karte zeigt die Dichte aller Erhebungspunkte des italienischen Staatsgebietes unabhängig von der Sprachzugehörigkeit. Wie man sieht, ist die Erschließung sehr ungleichmäßig; die Regionen mit Minderheitensprachen erweisen sich als klar privilegiert. – Andere, geolinguistisch hochkomplexe Gegenden, wie zum Beispiel das okzitanisch-piemontesisch-ligurische Übergangsgebiet sind dagegen absolut unterrepräsentiert.
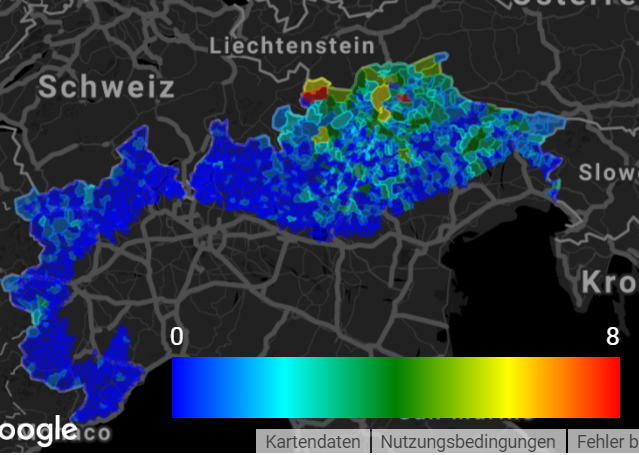
Karte 3: Geolinguistische Erschließung Italiens auf der Ebene der Gemeinden
Den Zugang zur Dokumentation vermitteln zunächst unterschiedliche Filter. Sie erlauben es dem Nutzer, aus den verfügbaren Daten eine gezielte Auswahl zu treffen und kartographisch darzustellen.
Filter zum interaktiven Kartenaufbau
Linguistische Datenaufbereitung
Bei Aktivierung ('Klick') eines Punktsymbols auf der Karte öffnet sich ein Fenster mit den jeweils für den Ort verfügbaren sprachlichen Daten. Alle Daten werden quellentreu wiedergegeben (als phonetisch transkribierter Einzelbeleg, wie im vorstehenden Beispiel, oder in orthographisch typisierter Form) und allgemeineren Typen zugeordnet; die abstrakteste Kategorie wird durch den etymologisch definierten Basistyp vertreten. Außerdem wird auf Referenzwörterbücher verlinkt, die – wenn möglich – auf standardsprachliche Äquivalente verweisen (hier die Symbole C und T). Das folgende Beispiel zeigt die Bezeichnung des Konzepts RAHM in Bergün (Graubünden):
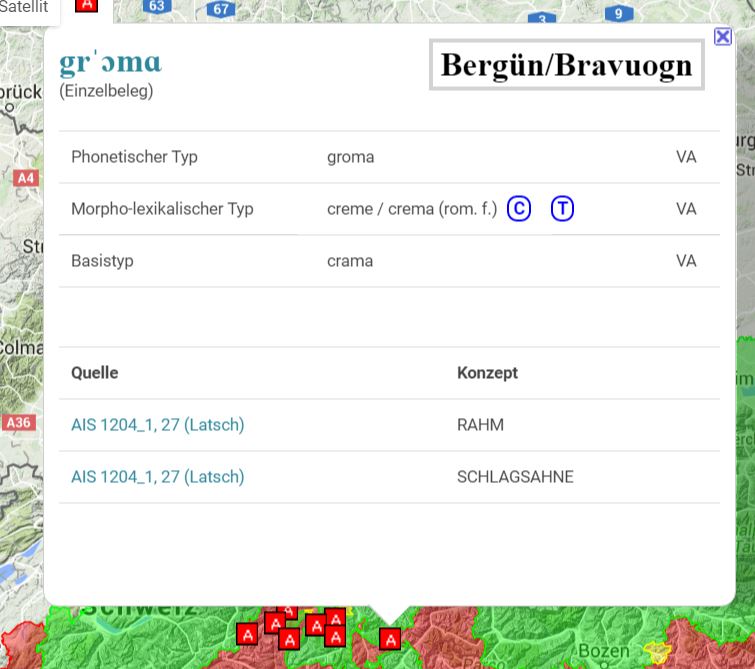
Karte 5: Präsentation und Typisierung der Sprachdaten im Belegfenster der interaktiven Karte
Wenn standardsprachliche Entsprechungen fehlen, wird auf dialektale Referenzwörterbücher verlinkt (z.B. das Schweizerische Idiotikon). Die Zuweisung jedes Sprachdatums einer Quelle zu einem Typ gestattet es, Quellen ganz unterschiedlicher Art zu kombinieren, ohne ihre erheblichen qualitativen Divergenzen zu verwischen.
Nicht selten sind in den ausgewählten Kategorien bereits zahlreiche sprachliche Ausdrücke verfügbar; die Suche nach dem 'Konzept' BUTTER führt zu 1449 Belegen. Es wird daher die Möglichkeit gegeben, alle relevanten Ausdrücke nach unterschiedlichen Kriterien zu gruppieren und sortieren.
Alternative Visualisierung
Komplementär zur Punktsymbolkarte wird eine interaktive Flächensymbolisierung vorbereitet, um eine gute Visualisierung quantitativer Verhältnisse zu ermöglichen. Dabei sollen einerseits die georeferenzierten Gemeindeflächen zu Grunde gelegt werden (wie auf Karte 3); zusätzlich sollen jedoch alle Gemeinden durch 'Waben' identischer Größe repräsentiert werden; wegen der sehr unterschiedlichen Gemeindegrößen wird die optische Wahrnehmung dadurch unwillkürlich verfälscht. Im Fall gleichgroßer Karteneinträge müsste diese Form der Visualisierung (im Unterschied zum echten Voronoi-Verfahren) allerdings auf die Georeferenzierung verzichten. Hier eine mögliche Kartierung:
Quellen
Bislang wurden einige georeferenzierbare Wörterbücher (wie etwa der ALTR), vor allem jedoch Sprachatlanten ausgewertet. Dabei wurden im wesentlichen drei Techniken eingesetzt:
Quellentyp (1): Gedruckte Karten
Bereits auf gedruckten Karten publiziertes Material wurde mit einem speziell entwickelten Tool neu transkribiert und in die VA-Datenbank eingelesen, so im Fall der allermeisten Atlanten (SDS, AIS, TSA usw.). Im Einzelnen sind die Prozeduren für die Digitalisierung jedoch aufwändig und kaum, wenn überhaupt, zu automatisieren. Sie setzen zunächst eine rigorose Trennung der unterschiedlichen Informationen voraus, die eine analoge Sprachkarte liefert. Diese Informationen werden von VerbaAlpina in einem Wissenshorizont strukturiert, der durch die drei Dimensionen der außersprachlichen Realität, der Konzepte und der sprachlichen Ausdrücke abgesteckt wird.
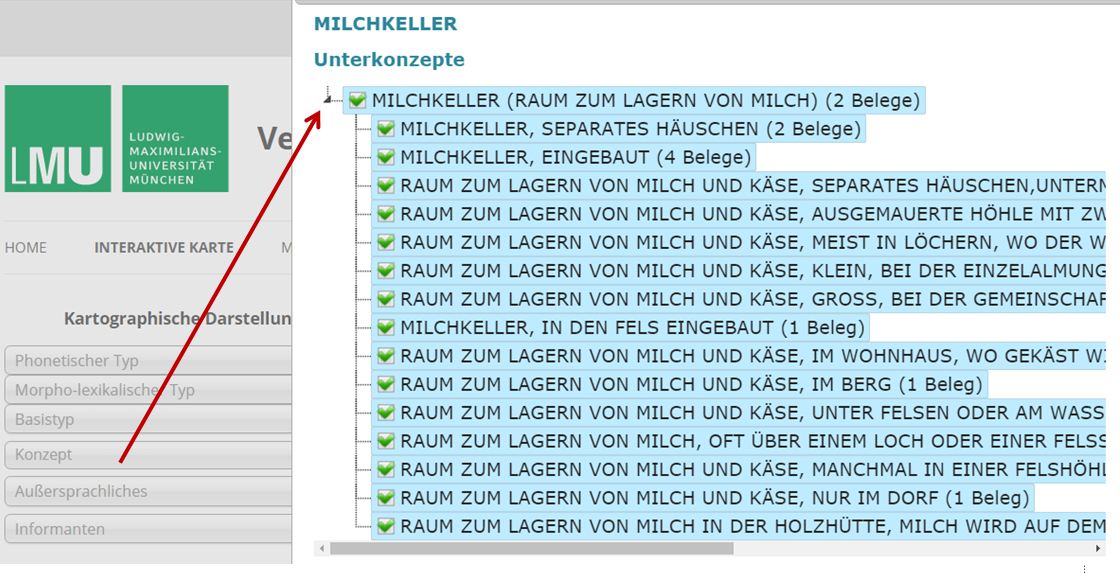
Man vergleiche etwa den allgemeinen Kommentar zum Stimulus MILCH-,KÄSEKELLER, der drei Bautypen (A, E, S) unterscheidet und sie bei den Einzelbelegen um weitere Informationen ergänzt (rot Pfeile).

Alle diese Hinweise werden von VerbaAlpina in abfragbare Unterkonzepte verwandelt, wie die folgende Abbildung zeigt:
So wird eine differenzierte semantische Analyse der erfassten Ausdrücke ebenso möglich wie eine onomasiologische Untersuchung der Konzeptbezeichnungen.
Die folgende Abbildung zeigt die Oberfläche, auf der gedrucktes Material transkribiert wird:
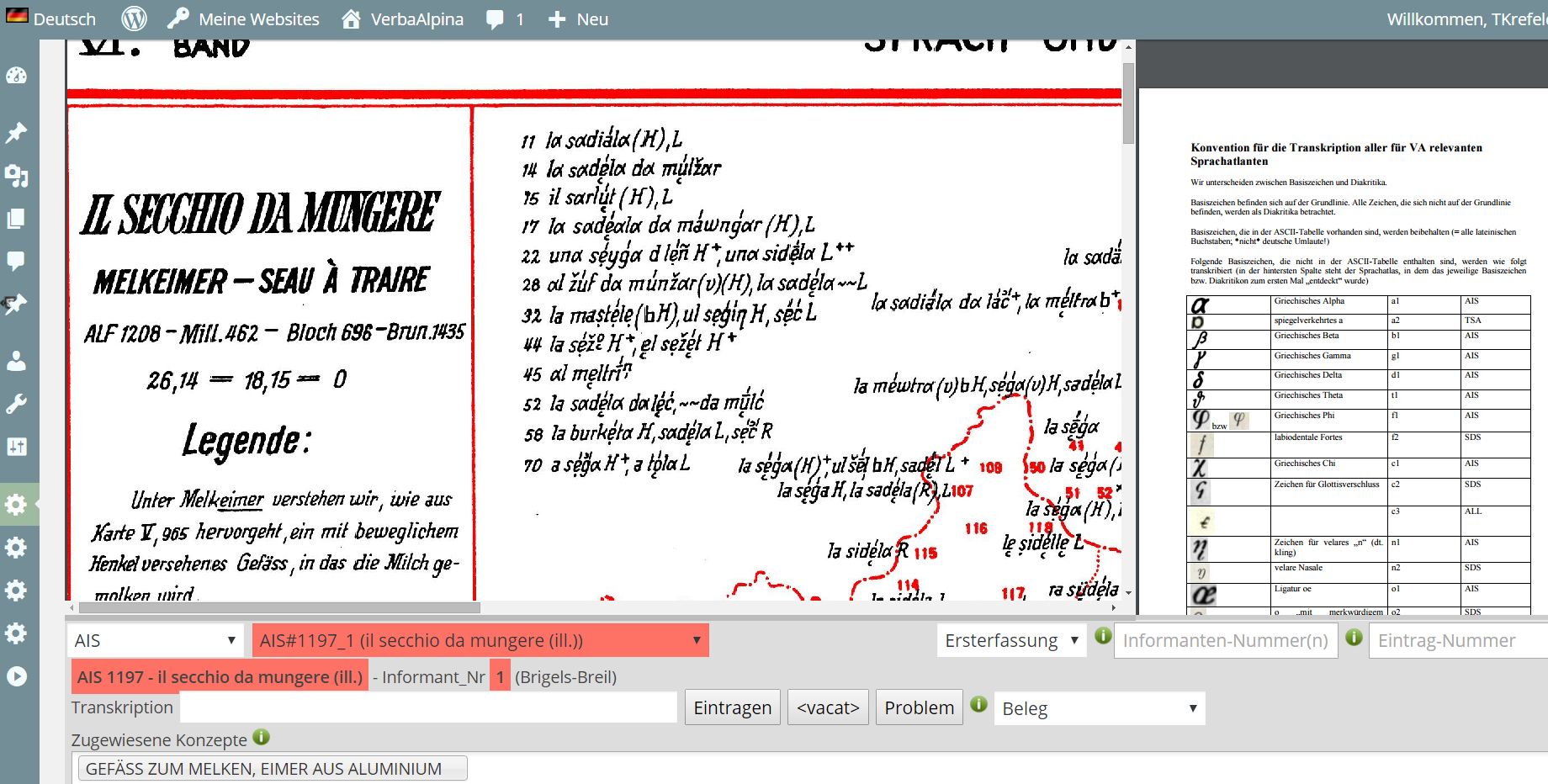
Das von VA entwickelte Transkriptionstool
Quellentyp (2): Gedruckte Karten auf Basis digitalisierter Daten
Bereits auf gedruckten Karten publiziertes Material, das jedoch im Original schon digital vorliegt, wurde so konvertiert und algorithmisch neu transkribiert, dass es in die VA-Datenbank eingelesen werden konnte. Dieses Verfahren wurde für den ALD-II und den ALTR praktiziert.
Quellentyp (3): Nicht publiziertes analoges Material
Noch nicht publiziertes Material anderer Projekte wird direkt aus deren Erhebungsbögen transkribiert bzw. digital übernommen; einen Auszug aus einem Erhebungsbogen des SAO veranschaulicht die direkte Übernahme, die mit dem selben Tool erfolgen kann, das für den Quellentyp (1) benutzt wird.

Fragebuchauszug aus dem SAO – Typ: 'Milchkammer' (Graphik: Stephan Lücke)
Die Datenbankeingabe der Quellentypen (1)-(3) geschieht nun zunächst mit Hilfe eines technischen Betacodes auf der Basis von ASCII-Zeichen und in einem zweiten Schritt mit einer automatischen Umsetzung der technischen Transkription in das Internationale Phonetische Alphabet (IPA), wie zwei Beispiele aus dem AIS und dem SAO zeigen:
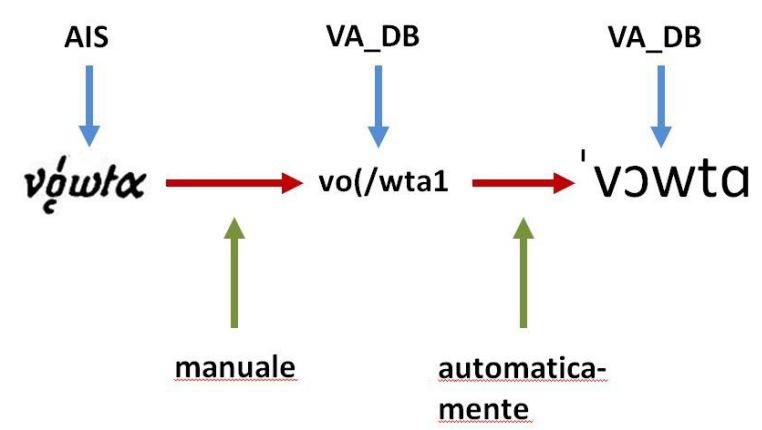
(Graphik: Stephan Lücke)
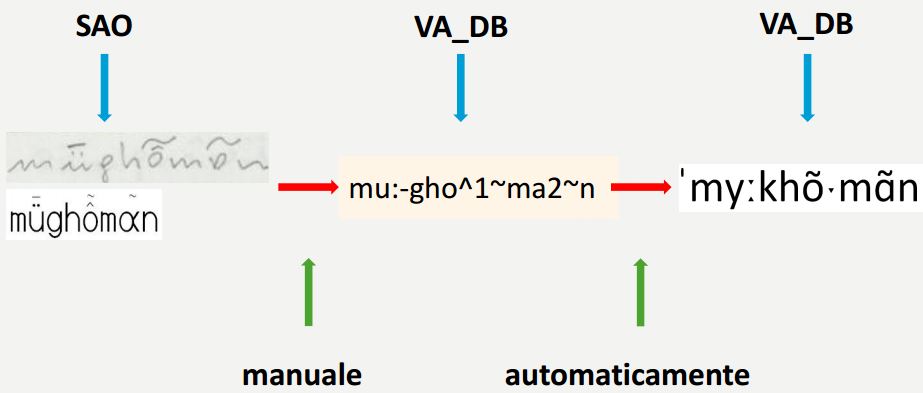
(Graphik: Stephan Lücke)
Die Entsprechungen von Input (Quelle), Betacode und Output (Weboberfläche) werden in einer mittlerweile umfangreichen Codepage (CODEPAGE FÜR ALLE) dokumentiert.
Bei den Materialien, die bereits in digitaler Kodierung vorliegen, kann die Umsetzung in IPA im Idealfall durch entsprechende Programmierung automatisiert werden. Das war etwa im Fall der ALD-Daten möglich.
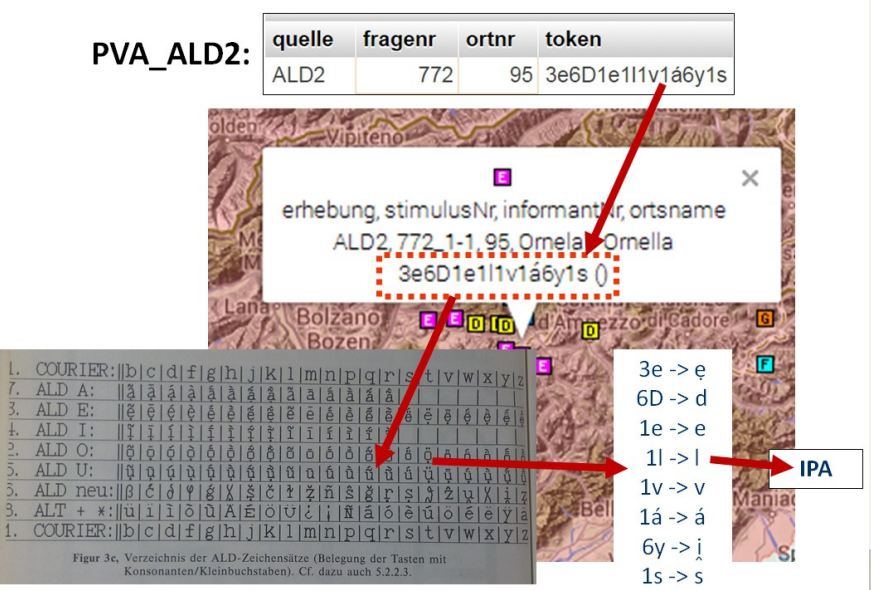
ALD-Kodierung 'edelvais' (Graphik: Stephan Lücke)
Die Quellentypen (1)-(3) ergeben oft ein inkonsistentes und wenig ausgeglichenes Bild, da nicht alle Stimuli offenkundig mit derselben Präzision abgefragt wurden; extrem sind z.B. die Details, mit denen die Bezeichnungen des ALMSTALLS in der Erhebung des AIS spezifiziert wurden. Dem übergeordneten Prinzip der Quellentreue folgend, werden die unterschiedlichen Gewichtungen in der Dokumentation von VerbaAlpina erhalten (Link --> Konzept --> Gebäude --> Almstall), idealerweise können sie jedoch durch Neuerhebungen ausgeglichen oder wenigstens reduziert werden.
Quellentyp (4): Neuerhebung über soziale Medien
Der Erhebung neuen Materials ist der 'Funktionsbereich (4)' gewidmet (s.u.).
Multidimensionalität
Für ein umfassendes Verständnis der sprachhistorischen Prozesse ist es unbedingt wünschenswert, die sprachlichen Daten um andere, historisch relevante Daten zu ergänzen; das kann VerbaAlpina nur sehr bedingt leisten; immerhin sind manche relevante Daten in der 'Interaktiven Karte' über den Filter 'Außersprachliches' abrufbar. Der folgende Kartenausschnitt zeigt in synoptischer Zusammenschau einerseits die
-
-
-
-
- Orte mit lateinischen Inschriften in der Provinz Noricum (mittelblauer Kreis);
- Orte mit lateinischen Inschriften aus Raetien (lilafarbener Kreis);
- aus der so genannten Tabula Peutingeriana überlieferten römische Ortsnamen an den viae publicae (pinkfarbener Kreis).
-
-
-
Andererseits wurden die Reflexe von drei lateinischen, genauer: zwei lateinischen und einem latinisierten aber mutmaßlich vorrömischen Basistypen aufgerufen:
-
-
-
-
- Basistyp lat. casearia in der Bedeutung 'Hütte' ('C' im dunkelblauen Kreis) in Nord-, Süd- und besonders prägnant in Osttirol;
- den Basistyp vorröm. baita in der Bedeutung 'Haus' ('B' im grünen Quadrat) in Slowenien südlich von Ljubljana;
- den Basistyp lat. cellarium in der Bedeutung 'Hütte' (grünes Dreieck) in Oberösterreich.
-
-
-
Invalid map id
Die unübersehbare Kongruenz oder wenigstens Affinität der Distributionen dürfte kaum einem Zufall geschuldet sein.
Ein westalpines Beispiel
Ein Beispiel aus den romanischsprachigen Westalpen, d.h. hier grosso modo aus dem Gebiet zwischen dem Rhônetal im Westen und dem Ossolatal im Osten, soll nun exemplarisch das sprachgeschichtliche Potential der webbasierten geolinguistischen Dokumantation zeigen.
Die lokalen Mundarten dieses Gebiets werden durch mehrere, teils ganz kleinräumige (CLAPie) und teils erst initial (APV, ALEPO) publizierte Sprachatlanten dokumentiert (vgl. Karte 1). Die Idiome dieses westalpinen Kontinuums werden von der Dialektologie in mehreren großräumigen Gruppen klassifiziert, die als 'Okzitanisch', 'Frankoprovenzalisch', 'Ligurisch' und 'Piemontesisch' bezeichnet werden. Die beiden zuerst genannten sind deutlich grenzüberschreitend – ganz im Gegensatz zu den entsprechenden Atlanten, die nur in Ausnahmefällen über die Staatsgrenzen hinausgehen : der ALF mit 8 Erhebungspunkten in Italien; der ALJA mit einem Erhebungspunkt in Italien und der APV mit je 2 Erhebungspunkten in Italien und in der Schweiz. Man beachte also, dass sowohl ALEPO als auch CLAPie und ALP im Wesentlichen okzitanische Mundarten erfassen, und dass ALJA und APV auf das Frankoprovenzalische zielen.
Es ist daher dringend wünschenswert, die Daten zusammenzuführen und synoptisch zu kartieren, wie es zumindest für spezifische Ausschnitte des Wortschatzes im Projekt VerbaAlpina geschieht:
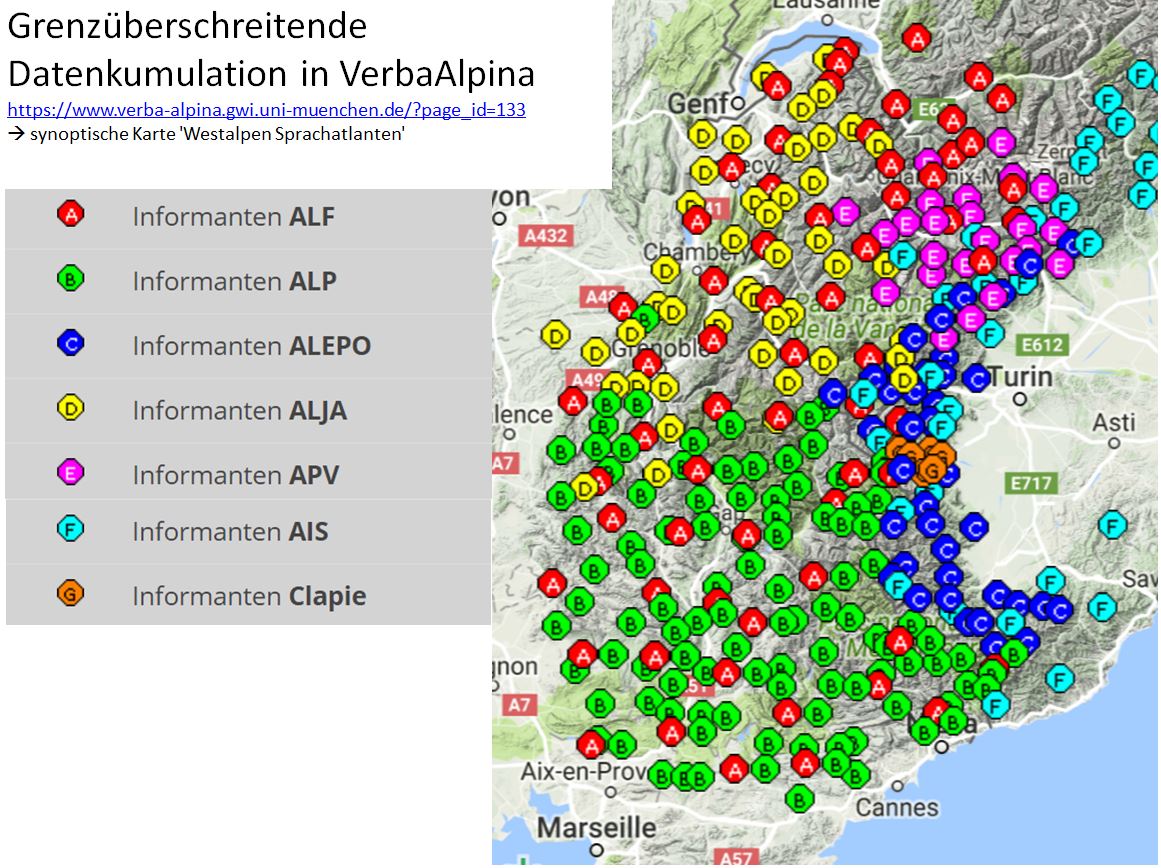
Karte 7: Geolinguistische Erschließung der Westalpen
Das Beispiel tomme/toma
Für eine detaillierte Sprachgeschichtsschreibung kann es im Übrigen nützlich, ja notwendig sein, eine weit über den eigentlich fokussierten Ausschnitt des Kontinuums hinausreichende räumliche Perspektive einzunehmen, so dass auch sekundär entstandene Migrationsvarietäten berücksichtigt werden können. Im Fall der Westalpen sind die süditalienischen und sizilianischen Kolonien von großem Interesse. Dazu das folgende, nicht ganz unbekannte Beispiel: In den Westalpen ist der morpholexikalische Typ tomme verbreitet; er geht etymologisch auf gall. toma (vgl. FEW 13, 20 f.) zurück. Als generische Bezeichnung des Konzepts KÄSE ist er weitgehend synonym mit dem Typ fra. fromage/ita. formaggio.
Invalid map id
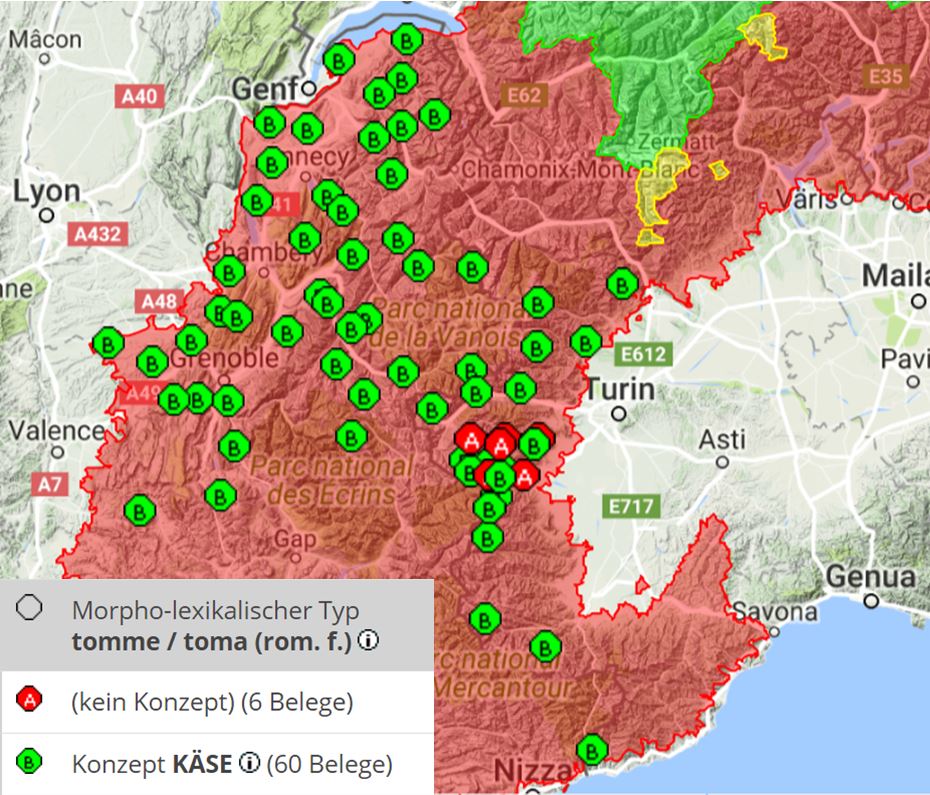
Karte 8: Verbreitung von tomma/tuma
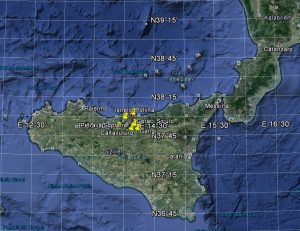
Karte 9: Die Madonie; das Erhebungsgebiet von Sottile 2002
"tuma GA ['tuma], GE → etn., AL → etn., CA → etn., IS. → etn., PO → etn. ['tuma],['tumwa] f. prodotto caseoso che si ottiene rompendo la cagliata. 2. formaggio fresco non sottoposto a sterilizzazione nella scotta. 3. formaggio fresco, immerso direttamente nella scotta senza essere pressato nelle fiscelle.
Rotta la cagliata (→ quagghiata) nella → tina, la massa caseosa che precipita sul fondo e che viene raccolta (→ accampari, → arricampari) e sistemata a scolare nel → tavulìeri è ormai detta tuma. La tuma, poi, facoltativamente tagliata a cubetti, viene sistemata in fiscelle (→ ntumari, → ntumalora) perché possa scolare ulteriormente. Tuma è, inoltre, chiamato il formaggio che non viene sottoposta a sterilizzazione nella scotta (cfr. GE) e che generalmente viene consumato subito [...]
Etn[otesto]. GE [a Geraci; TK] a tuma un ci â d'èssiri misa nâ → vasceɖɖa, si ssi parra di tuma.
Trad. «la 'tuma' non va messa [raccolta] nelle fiscelle, se parliamo della 'tuma' ». [...]
Etn. IS [a Isnello, TK] a tuma jeni u prodottu che si ffa ppoi u → formàggiu
Trad. «La 'tuma' è il prodotto [la pasta caseosa] che [con cui] si fa il formaggio». [...]" ((Sottile 2002, 168), 168)
In Sizilien haben sich also beide Typen in ihren ursprünglichen und spezifischen Bedeutungen erhalten, die im Fall von fromaggiu sogar noch motiviert ist. Ebenfalls noch motiviert ist der siz. Diminutiv tumazzu (vgl. Sottile 2002, 168), der für zwar feste und geformte, aber daher auch reduzierte, eher kleine Käselaibe steht (wie die Produkte, die heute in Frankreich und in der Westschweiz als tomme vermarktet werden).
Funktionsbereich (2): Kooperation
Neben den gleichsam historischen Sprachdaten, die in Sprachatlanten und Wörterbüchern dokumentiert sind, werden weitere, nicht selten aktuellere, Sprachdaten aus dem Alpenraum von Sprachforschern verschiedener akademischer Institutionen gesammelt, verwaltet und publiziert. Aus Sicht von VerbaAlpina spielen diese Daten in mehrfacher Weise eine bedeutende Rolle. Zum einen erlauben sie unter Umständen, Beleglücken onomasiologischer und/oder geographischer Art zu schließen, die die systematische Erfassung des Atlanten- und Wörterbuchmaterials zurückgelassen hat. Gerade wenn es sich um rezentes Sprachmaterial handelt, eröffnet sich daneben jedoch auch eine diachrone Perspektive, die durch den Vergleich mit dem historischen Material einen Blick auf Sprach- und unter Umständen auch auf einen dahinter stehenden Kulturwandel ermöglicht. Aus diesem Grund hat sich VerbaAlpina um den Abschluss von Kooperationsvereinbarungen mit einer ganzen Reihe von Projektpartnern bemüht. Die immer noch anwachsende Liste von Institutionen aber auch von Einzelpersonen ist auf dem VerbaAlpina-Portal einsehbar. Derzeit bestehen über 30 derartige Kooperationsvereinbarungen.
Zentraler Gegenstand der entsprechenden Vereinbarung ist der wechselseitige (!) Austausch von Sprachmaterial, d.h. VerbaAlpina stellt seinerseits seinen Projektpartnern das gesamte in der VerbaAlpina-Datenbank (VA_DB) zusammengetragene Material zur Verfügung. Wesentlicher Bestandteil der Kooperationsvereinbarung ist die allseitige Verpflichtung, bei der Verwendung von Sprachmaterial im Rahmen von Publikationen grundsätzlich die ursprüngliche Quelle der jeweiligen Daten zu nennen.
Durch die Vielzahl an Kooperationsvereinbarungen ist zunächst de iure, nach und nach jedoch auch de facto eine Vernetzung bislang voneinander getrennter Datenbestände entstanden, die es allen Beteiligten ermöglicht, die eigenen Daten in einem erweiterten Kontext zu sehen bzw. auch darzustellen. Zwar ist diese Art der Vernetzung aktuell, dem thematischen Focus von VerbaAlpina entsprechend, auf den Alpenraum beschränkt, eine Ausweitung über die Grenzen des Projekts und seinen geographischen Rahmen hinaus ist aber natürlich sehr sinnvoll und entsprechend wünschenswert. Aus diesem Grund wurde damit begonnen, Kooperationspartner auch außerhalb der Alpenregion zu suchen. Aktuell laufen Gespräche mit Vertretern des Atlante linguistico della Sicilia (ALS), und in einem kleinen Versuchsrahmen wurden auch schon Daten aus Sizilien in unser geolinguistisches System integriert. Es existiert auch bereits ein entsprechendes Portal, über die diese sizilianischen Daten in ganz ähnlicher Weise wie bei VerbaAlpina abgerufen, visualisiert und analysiert werden können:
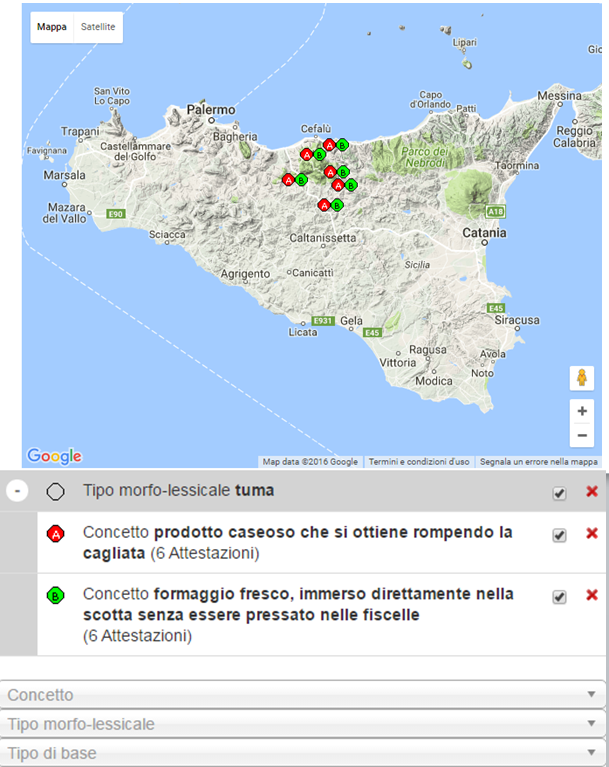
Daten des Atlante Linguistico della Sicilia auf einer online-Karte (http://www.als-online.gwi.uni-muenchen.de/carta/)
Das Erscheinungsbild lässt deutlich erkennen, dass hier die selbe Technologie zum Einsatz kommt wie bei VerbaAlpina. Auch wenn man nicht von einem generischen System im engeren Sinne bzw. von modularer Verwendung sprechen kann, so ist die Realisierung eines solchen Ablegers, der sich im wesentlichen nur durch die geographische Verortung unterscheidet, aus rein technischer Sicht kein großes Problem. Und dadurch, dass die eigentlichen Daten im selben Backend und – ganz wesentlich – in einer kompatiblen Struktur verwaltet werden, sind problemlos regionsübergreifende Zusammenhänge erkenn- und darstellbar. Die sprachwissenschaftliche Relevanz dieser Möglichkeit wurde gerade vorhin illustriert am Beispiel der morpholexikalischen Typen Tomme/Toma und Fromage/formaggio.
Das Ziel besteht letztlich darin, eine geolinguistische Forschungsplattform zu etablieren, an der sich Sprachwissenschaftler unterschiedlichster Fachrichtungen und Interessen beteiligen können.
Für die Erzielung möglichst weitreichender Akzeptanz sind verschiedene Faktoren von Bedeutung. Einer dieser Faktoren wurde bereits genannt: Die allseitige Verpflichtung, bei der Verwendung fremden Materials grundsätzlich dessen ursprüngliche Herkunft zu nennen. Eine weitere wichtige Voraussetzung ist, dass einerseits Standards hinsichtlich Datenstrukturierung und Zeichenkodierung vereinbart und eingehalten werden, andererseits alle Beteiligten ein Maximum an individueller Freiheit hinsichtlich eben dieser Standards behalten. Was widersprüchlich klingt, lässt sich durch ein Schnittstellenmodell zumindest konzeptionell problemlos realisieren: Für jede Datenstruktur und Kodierung wird eine eigene Schnittstellenprozedur entworfen, die die Daten von der individuellen Gestalt in die definierten Standards überführt.
VerbaAlpina stellt jedem Partnerprojekt eine eigene relationale Datenbank auf einem MySQL-Server-Cluster zur Verfügung:
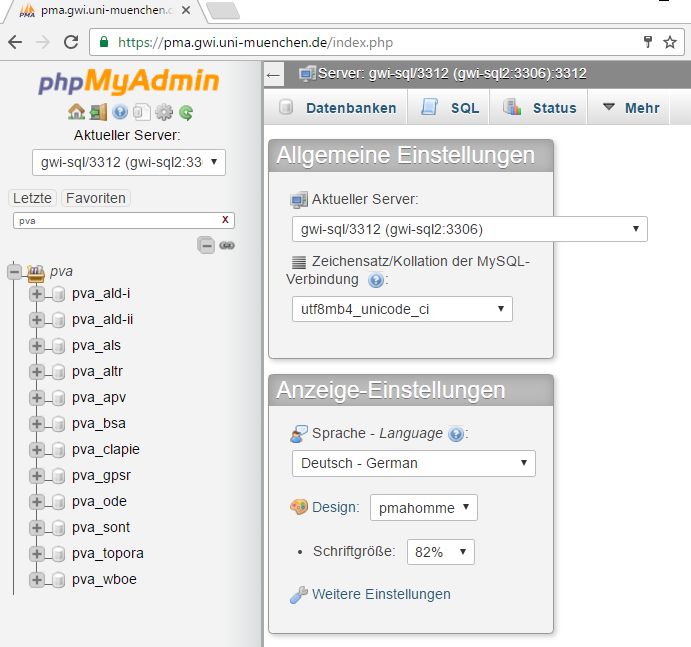
Die Datenbanken der VerbaAlpina-Partner (PVA) auf dem MySQL-Cluster der ITG (Stand: 2016-11-22)
Die Projektpartner sind hinsichtlich der konkreten Ausgestaltung ihrer Datenbank im Hinblick auf Strukturierung und Zeichenkodierung vollkommen frei. Lediglich VerbaAlpina sowie sämtliche Kooperationspartner, die sich durch die Unterzeichnung der Kooperationsvereinbarung zur Einhaltung der genannten Regeln verpflichtet haben, besitzen Leserechte auf die Partnerdatenbanken. Nach außen hin ist der Zugang zu den Datenbanken passwortgeschützt, kann auf Wunsch der Eigentümer jedoch individuell oder für jedermann, vollständig oder in Teilen, freigegeben werden. Folgende Grafik gibt, unter anderem, einen Überblick über die Zugriffsrechte auf die einzelnen Module von VerbaAlpina. Mit Zugriffsrechten sind hier stets Leserechte, keine Schreibrechte, gemeint:
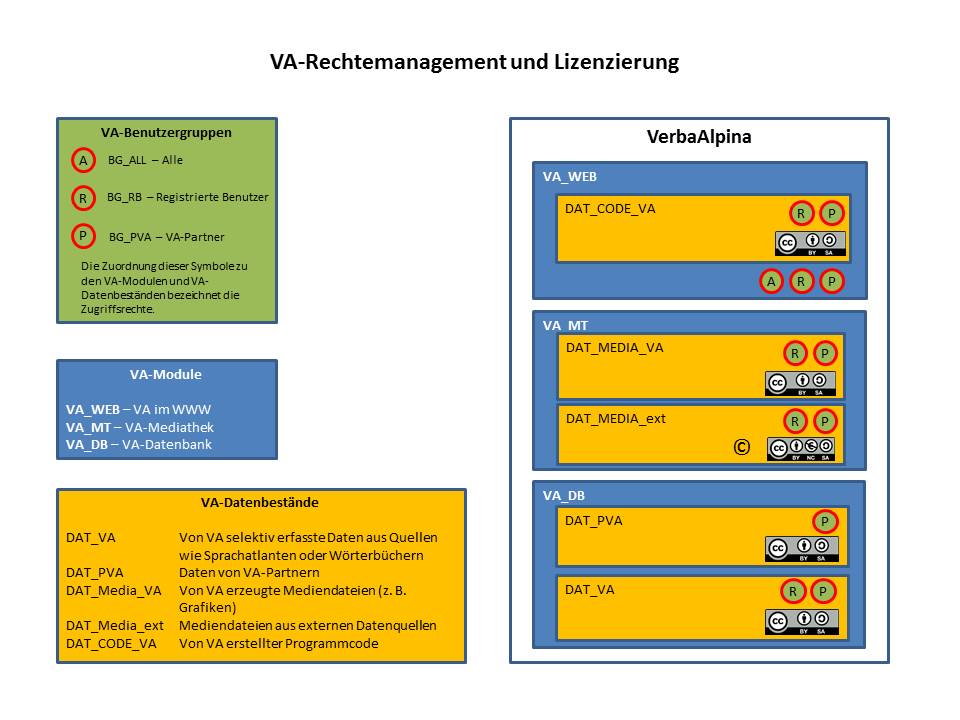
Die Daten der Projektpartner werden von der IT-Gruppe Geisteswissenschaften (ITG) der Ludwig-Maximilians-Universität (LMU) München in einer, z.T. an das Leibniz-Rechenzentrum (LRZ) angebundenen, professionellen IT-Infrastruktur gehalten. Die ITG garantiert hohe Ausfallsicherheit sowie, selbstverständlich, die regelmäßige Anfertigung von Backups. Auch die langfristige Archivierung der Daten der Projektpartner auf den Archivierungsservern des LRZ ist möglich.
Aus Sicht der Kooperationspartner könnte ein wichtiger Aspekt die institutionelle Absicherung der ITG sein. Es geschieht leider nicht selten, dass großangelegte Projekte, die über viele Jahre hinweg finanziert und betrieben wurden und die z.T. große Mengen an Material zusammengetragen haben, nach Ende der Finanzierung vor dem Aus stehen und es keine Möglichkeit gibt, die Projektdaten zu bewahren bzw. auch weiterhin zur Verfügung zu stellen. Dieses Problem ist weit verbreitet und nicht auf einzelne Länder beschränkt. Erst jüngst berichtete die Inhaberin der Humboldt-Professur für die Alte Geschichte des Nahen und Mittleren Ostens, Karen Radner (übrigens eine Österreicherin), von ihrer Erfahrung mit einer Datenbank mit Keilschrifttexten. Diese Datenbank war über Jahrzehnte hinweg an der Universität Helsinki erarbeitet worden. Nachdem der Verantwortliche Wissenschaftler in den Ruehstand gegangen war, habe sich an der Universität Helsinki niemand für diesen einzigartigen Datenbstand interessiert. Zum Glück konnte Karen Radner den Datenbestand übernehmen und das Projekt fortführen.
Der Umgang mit elektronischen Datenbeständen ist im Hinblick auf Nachhaltigkeit und Nachnutzbarkeit eine große Herausforderung für den gesamten Wissenschaftsbetrieb. Neben Fragen der Standardisierung von Kodierungen und Strukturierungen ist dabei ganz wesentlich die Frage, welche Institution(en) die Verantwortung für Bewahrung, Verfügbarkeit und Pflege dieser Art von Daten übernehmen sollen. Prädestiniert für diese Aufgabe erscheinen eigentlich die Bibliotheken, die seit Jahrhunderten für die Bewahrung von Wissen zuständig gewesen sind, und tatsächlich beschäftigen sich etliche Bibliotheken mit dieser Frage. Parallel entstehen andere Strukturen, die sich in ähnlicher Weise derselben Aufgabe widmen. Zu nennen wären hier z.B. sog. Repositorien wie etwa der Clarin-Verbund oder auch die D-Grid-Initiative, die es sich zur Aufgabe gemacht hat, "eine nachhaltige Grid-Infrastruktur in Deutschland aufbaut, um Informations- und Wissenstechnologien dezentral für die Wissenschaft nutzbar zu machen".
In gewisser Weise symptomatisch ist, dass ausgerechnet die im Wikipedia-Artikel "D-Grid" zitierten Portaladressen von D-Grid, http://www.d-grid.de/ und http://www.d-grid-ggmbh.de/, dort als "Offizielle Webpräsenz der D-Grid-Initiative" bezeichnet, nicht mehr erreichbar sind (Aufruf am 22.11.2016, vormittag):
Natürlich kann dergleichen aus technischen Gründen immer wieder passieren, und auch wir sind davor nicht gefeit. Dass allerdings auch eine Google-Suche nach "D-Grid" die offizielle Webpräsenz nicht (oder bestenfalls unter ferner liefen) zutage fördert, stimmt dann doch bedenklich. Schließlich handelt es sich um eine Initiative der Bundesrepublik Deutschland, die mit über 70 Millionen Euro gefördert worden ist (Quelle: https://de.wikipedia.org/wiki/D-Grid, 2016-11-22). Dieses Beispiel illustriert sehr schön, wie wichtig die dauerhafte institutionelle Verankerung einer verantwortlichen Institution in diesem Umfeld ist. Es ist allerdings, fairer Weise, darauf hinzuweisen, dass die Teilprojekte von D-Grid wie z.B. Textgrid nach wie vor im Internet erreichbar sind (https://textgrid.de/). Man kann nur hoffen, dass sie nicht in absehbarer Zeit ebenso verschwinden wie das Dach-Portal.
Die Lage ist unübersichtlich, und es ist schwer zu sagen, welche Institution sich für welche Art von Daten zuständig fühlt, wie die jeweiligen Perspektiven aussehen und, überhaupt, welche Lösung sich am Ende durchsetzen wird. Im Moment kann es daher nur darum gehen, eine geeignete Institution zu finden, die erstens bereit und dazu in der Lage ist, Daten über einen längeren Zeitraum sachgerechet zu speichern, verfügbar zu halten und zu pflegen, und die überdies über eine unbefristete Existenzperspektive besitzt. Diese Kriterien erfüllt z.B. die ITG. Sie ist eine zentrale wissenschaftliche Einrichtung der LMU, zuständig für die sechs geisteswissenschaftlichen Fakultäten, und ausgestattet mit derzeit, jeweils unbefristeten, vier wissenschaftlichen und drei technischen Personalstellen. Nicht zuletzt aus diesem Grund kann VerbaAlpina mit seiner Anbindung an die ITG seinen Partnern einen wichtigen Dienst leisten.
Funktionsbereich (3): Publikation
Wo immer Webtechnologie zum Einsatz kommt, verliert der Begriff der ‘Publikation’ seine Selbstverständlichkeit. Strenggenommen sind schon ein offener Quellcode ('open source') und die Datendokumentation im Internet Publikationsformen, ungeachtet der Tatsache, dass sie nicht immer dazugezählt werden. Darüber hinaus versteht sich VerbaAlpina aber auch als Instrument zur Veröffentlichung von projektbezogenen Texten. Dafür sind Im Wesentlichen drei Formate vorgesehen.
- Theoretisch und methodologisch zentrale Begriffe und Probleme sowie Hinweise zur Funktionalität der Forschungsumgebung werden in meist konziser, gelegentlich auch etwas weiter ausholender Weise unter dem Reiter Methodologie abgelegt.
- Ausführlichere analytische Untersuchungen von Projektergebnissen oder theoretische bzw. methodologische Diskussion können unter Projektpublikationen abgelegt werden.
- Kommentare zu einzelnen sprachlichen Typen werden in der Kartenlegende durch einen ‚i‘-Button geöffnet; sie können dort auch sehr leicht durch Projektmitarbeiter oder Externe eingestellt werden (vgl. z.B. den Kommentar zum Basistyp *pinguia in der interaktiven Karte).
Da Webpublikationen im genannten Sinn leicht modifizierbar sind und vor allem im Fall von aktiven Projekten auch kontinuierlich modifiziert werden (sollten), ist es unerlässlich eine verlässliche Zitierweise zu ermöglichen, die in ihrer Verlässlichkeit dem Standard gedruckter Literatur entspricht. Der Projektinhalt von VerbaAlpina wird daher von Zeit zu Zeit in stabilen Zitierversionen 'eingefroren', die von der jeweils aktuellen und sich verändernden Arbeitsversion unterschieden werden müssen. Jedem Beitrag zur Projekt Methodologie ist daher mit einem entsprechenden Zitierhinweis versehen, der die jeweilig Version automatisch präzisiert; im folgenden Beispiel handelt es sich also um den Beitrag 'Typisierung' der Version 16/1:

Hinweis zur Zitierweise
Funktionsbereich (4): Datenerhebung durch Crowdsourcing
Außer durch die Datenbestände von Projektpartnern können die bereits angesprochenen Inkonsistenzen hinsichtlich der onomasiologischen oder geographischen Abdeckung auch durch das sog. Crowdsourcing ausgeglichen werden. Mit Crowdsourcing ist laut Wikipedia "die Auslagerung traditionell interner Teilaufgaben an eine Gruppe freiwilliger User, z. B. über das Internet" (Quelle) gemeint und wird dort als Anlehnung an den Begriff "Outsourcing" bezeichnet. Die Funktion des Crowdsourcing im Rahmen von VerbaAlpina ist jedoch vielleicht besser durch die Kernbedeutung des Wortes "source" beschrieben. Die Nutzer des Internets sollen als Daten-QUELLE dienen und ihre Kenntnisse der Dialekte des Alpenraums in den Datenbestand von VerbaAlpina einbringen.
In diesem Zusammenhang stellen sich die folgenden Probleme bzw. Herausforderungen:
- Kontaktherstellung zu geeigneten "Crowdern" und evtl. Herstellung einer Bindung ans Projekt
- Kontaktherstellung: Kontakt zu einschlägigen Institutionen im Alpenraum. Hier eine aktuelle Liste von Veranstaltungen, auf denen VerbaAlpina beworben werden könnte bzw. wird:
1) Bezirksbäuerinnentag (Südtiroler Bäuerinnenorganisation), 28.01.2017, Bozen
2) Alpsennenkurs (AVA, Alpwirtschaftlicher Verein im Allgäu e.V.), 26.04.2017, Immenstadt
3) Österreichische Almwirtschaftstagung (Steirischer Almwirtschaftsverein), 28.-30.06.2017, Krieglach (Dachorganisation: Almwirtschaft Österreich)
4) Deutscher Bauerntag (Deutscher Bauernverband), 28.-29.06.2017, Ort noch unbekannt
5) Käseolympiade (Tourismusverband Galtür), 23.09.2017, Galtür
6) Oberbayerischer Almbauerntag (AVO, Almwirtschaftlicher Verein Oberbayern), 7./8.10.2017, Samerberg
Adressenliste mit derzeit rund 4000 Einzelpersonen (darunter auch 150 Almen; Tabelle `crowdkontakte` in VA_DB) und Institutionen im ganzen Alpenraum (A, D, F, I, SLO)
- Flyer:

- Präsenz in den Medien (Zeitungen, Hörfunk)
- Präsenz in sozialen Netzwerken (z.B. Facebook):
Ein- bis zweimal im Monat eine Meldung, z.B. eine spezielle, vielleicht nicht so bekannte Bezeichnung für ein bestimmtes Konzept. Evtl. auch interessante Abbildungen aus der Lebenswelt der Almen.
Bindung: Möglichkeit, sich zu registrieren (Motivation: Crowder kann sehen, wieviel er bislang beigetragen hat, auch im Vergleich zu anderen)
- Technische Umsetzung
- Web-Portal
- Smartphone-App (quasi fertiggestellt; erster Prototyp bereits Anfang Juli 2016 im Rahmen einer Bachelorarbeit von Giorgia Grimaldi erprobt)
Die Crowdsourcing-App von VerbaAlpina
Die Crowdsourcing-App von VerbaAlpina
- Steuerung der Datenerhebung (um onomasiologische und/oder geographische Lücken gezielt schließen zu können)
- Priorisierung besonders schlecht belegter KONZEPTE bei der Auswahl, die dem "Crowder" präsentiert wird
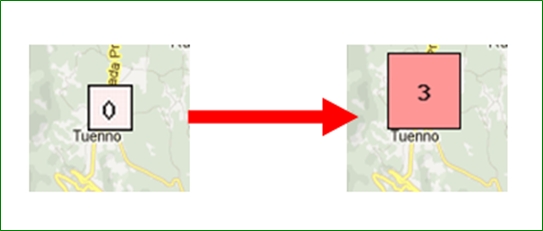
- Kartierung, die, bezogen auf definierte "Mittelräume" (sog. NUTS-3-Regionen), die Anzahl in VerbaAlpina bereits vorhandener Belege, durch Farbsättigung wiedergibt.
- Attraktive Gestaltung der Schnittstelle und technische Zuverlässigkeit zur Steigerung der Akzeptanz: Möglichst einfach und übersichtlich; keine App, sondern Webseite mit "responsivem" Layout, die auch die komfortable Nutzung auf Smartphones erlaubt.
- Orthographie und Typisierung
- Fokus auf morphologischen Typen; Phonetik spielt keine bzw. untergeordnete Rolle
- manuelle Typisierung dennoch nicht vermeidbar
- Validierung der eingehobenen Daten
- Prinzip: "Einmal ist keinmal, zweimal ist immer" – Wenn zwei von einander unabhängige Quellen (≙ Crowder) dasselbe behaupten, dann besteht Sicherheit; Visualisierungsmöglichkeit:
- Einbindung von "Kompetenztests" nach folgendem Muster:
- Prinzip: "Einmal ist keinmal, zweimal ist immer" – Wenn zwei von einander unabhängige Quellen (≙ Crowder) dasselbe behaupten, dann besteht Sicherheit; Visualisierungsmöglichkeit:

- Registrierung
- Möglichkeit der Kommentierung durch registrierte Crowder und Wissenschaftler gleichermaßen
Funktionsbereich (5): virtuelles Forschungslabor
Bibliographie
- AIS = Jaberg, Karl / Jud, Jakob (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz, Zofingen, vol. 1-7
- ALD-II = Goebl, Hans (2012): Atlant linguistich dl ladin dolomitich y di dialec vejins, 2a pert, vol. 1-5, Editions de Linguistique et de Philologie. Link
- ALEPO = Telmon, Tullio (2013): Atlante Linguistico ed Etnografico del Piemonte Occidentale III: Il mondo animale: I La Fauna: II caccia e pasca, Alessandria, vol. 3, Edizioni dell’Orso. Link
- ALF = Gilliéron, Jules / Edmont, Edmond (1897-1900): l’Atlas linguistique de la France, Paris , Champion. Link
- ALJA = Martin, Jean-Baptiste / Tuaillon, Gaston (1971, 1978, 1981): Atlas linguistique et ethnographique du Jura et des Alpes du nord, Paris, vol. 1, 3, 3a, Éd. du Centre National de la Recherche Scientifique
- ALP = Bouvier, Jean-Claude (1975, 1979, 1986): Atlas linguistique et ethnographique de la Provence, Paris, vol. 1, 2, 3, Éd. du Centre National de la Recherche Scientifique
- ALTR = Cordin, Patrizia (2005): L'Archivio lessicale dei dialetti trentini. Link
- APV = Schüle, Ernest (1978): Atlas des patois valdôtains, Aoste, Departement de l'instruction publique. Link
- Auer 2004 = Auer, Peter (2004): Sprache, Grenze, Raum, in: Zeitschrift für Sprachwissenschaft, vol. 23, 149-179. Link
- CLAPie = Cugno, Federica / Rivoira, Matteo (2014): Culture e Lingue nelle Alpi del Piemonte. Link
- FEW = Wartburg, Walter (1922-1967): Französisches etymologisches Wörterbuch. Eine Darstellung des galloromanischen Sprachschatzes , Basel, vol. 20, Zbinden. Link
- SAO = Adalbert-Stifter-Institut des Landes Oberösterreich (Hrsg.) (1998ff.): Sprachatlas von Oberösterreich
- SDS = Baumgartner, Heinrich/ Handschuh, Doris/ Hotzenköcherle, Rudolf (1962-2003): Sprachatlas der Deutschen Schweiz, Bern, vol. 1-9, Francke
- Sottile 2002 = Sottile, Roberto (2002): Lessico dei pastori delle Madonie, Palermo, Centro di studi filologici e linguistici siciliani. Link
- TSA = Klein, Karl Kurt/ Kühebacher, Egon/ Schmitt, Ludwig Erich (1965, 1969, 1971): Tirolischer Sprachatlas, vol. 1-3, Innsbruck, Tyrolia-Verl. [u.a.]
- WBÖ = Eintrag nicht gefunden