

1. Einleitung
Das Projekt Tiroler Ortsdialekte online (TiDiOn) arbeitet an der Erstellung eines interaktiven Sprachatlas basierend auf dem Korpus des Tiroler Dialektarchivs am Institut für Germanistik der Universität Innsbruck. Durch den Aufbau einer geeigneten Datenbankstruktur, die Digitalisierung und Vereinheitlichung des handschriftlichen Materials mithilfe einer eigens dafür konzipierten Teuthonista-Schriftart sowie durch die Kategorisierung, Verknüpfung und Kartierung der Daten werden die Tiroler Mundarten einer breiten Öffentlichkeit online zugänglich gemacht. Durch die Förderung des Landes Tirol konnte im August 2015 mit der Arbeit am digitalen Sprachaltas begonnen werden.
2. Ausgangssituation
Das deutschsprachige Tirol (Region), das Gebiete in Österreich und Italien umfasst, liegt am südlichen, alpinen Rand des oberdeutschen Sprachraums, größtenteils auf dem Gebiet des Bairischen, aber auch schon im Übergangsgebiet zum Alemannischen. Bedingt durch seine Siedlungsgeschichte und montane Topographie gliedert es sich sprachlich in Südmittelbairisch im Tiroler Unterland, Südbairisch im zentralen Nordtirol sowie dem gesamten Süd- und Osttirol, alemannisch beeinflusstes Südbairisch im Tiroler Oberland sowie Schwäbisch im äußersten Nordwesten. Hinzu kommt in ganz Tirol ein alpenromanisches Substrat wie in Osttirol zusätzlich ein slawisches.
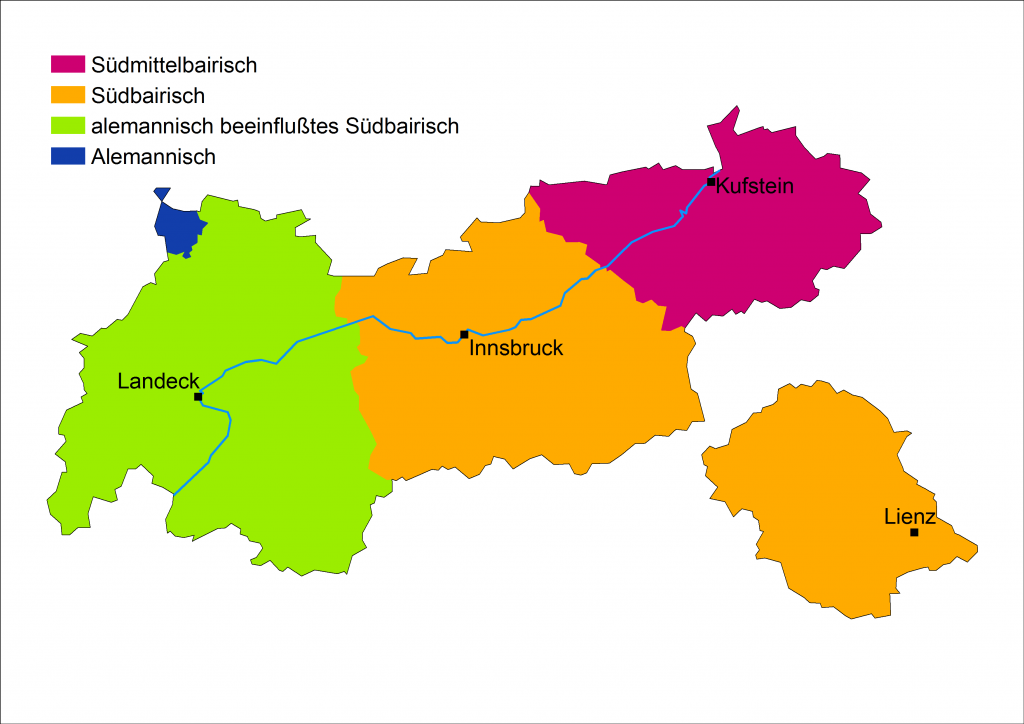
Großdialekte Tirols innerhalb Österreichs.
In den 1970er- und 1980er-Jahren und teils bis in die 2010er-Jahre wurden in Summe zehn Exploratorinnen und Exploratoren damit beauftragt, die Tiroler Ortsdialekte zu dokumentieren. Anhand ähnlicher, aber im Detail unterschiedlicher Fragebücher mit jeweils 2.200 Fragen zum bäuerlichen Alltag wurden im Idealfall mehrere ältere, sprachlich und sachlich sichere Gewährspersonen in ausgewählten Gemeinden befragt und dies schriftlich in Teuthonista und teilweise auf Tonband oder Audiokassette aufgezeichnet. Die Anzahl der Gewährspersonen belief sich auf ca. 500, die zur Zeit der Befragung im Durchschnitt 70 Jahre alt waren. Dabei reichte das Altersspektrum von 20 bis 93 Jahre. 81 Jahre liegen zwischen der Person mit dem am weitesten zurückliegenden Geburtsjahr (1880) und jener mit dem am zeitlich nächsten (1961). Die Erhebungen von über 120 Gemeinden des Bundeslandes Tirol liegen als Original oder Kopie im Tiroler Dialektarchiv in Innsbruck und bilden das Ausgangsmaterial für unser Projekt.
3. Ziele
Die Grundstruktur unserer Datenbank stand zu Projektbeginn bereits fest. Eines unserer kurzfristigen Ziele ist daher, diese durch kleinere Änderungen im Laufe der Zeit und durch die Erfahrung in der Anwendung anzupassen. Anfänglich ist angedacht, Phänomene, die für die breite Bevölkerung interessant sind, etwa weil sie ihre alltägliche Lebenswelt berühren, zuerst zu bearbeiten und damit einen vorläufig statischen Sprachatlas zu erstellen. Dieser soll der Öffentlichkeit sowie der Wissenschaft zugänglich gemacht werden. Langfristig ist die Erstellung eines webbasierten, multimedialen und interaktiven Sprachatlas, in dem das gesamte Erhebungs-, Ton- und Bildmaterial des Tiroler Dialektarchivs aufbereitet, zusammengeführt und zugänglich ist, unser Ziel.
4. Derzeitige Situation
4.1. Digitalisierung und Archivierung
Da der Bestand, also die Niederschrift der Erhebung, in physischer Form in Innsbruck liegt, bestand die Gefahr, das Material durch unvorhergesehene Ereignisse zu verlieren. Um einem ebensolchen Verlust vorzubeugen, wurden die gesamten Aufzeichnungen hochauflösend gescannt und die Digitalisate dezentral in einem mehrfach gesicherten Enterprise-CMS gespeichert. Der Prozess der Digitalisierung bringt neben der Beständigkeit des Materials weitere Vorteile, wie etwa die ortsunabhängige Zugänglichkeit und Nutzung der Bestände oder auch die schnellere Handhabung bei der Materialdurchsicht und -aufarbeitung mit sich. Auch die sich im Besitz des Archivs befindlichen Tondokumente und Fotografien wurden ebenfalls digitalisiert und in weiterer Folge adäquat aufbewahrt, um ihrer Vergänglichkeit entgegenzuwirken. Ton und Bild machen jedoch nur einen Bruchteil des im Archiv lagernden Materials aus.
4.2. Vorüberlegungen
Die testweise Auswahl und Eingabe erster Belege in die Datenbank war von zahlreichen Vorüberlegungen geleitet. Da die Zahl der durch die Fragebücher elizitierten Antworten sich insgesamt auf etwa 240.000 beläuft, war es zu Beginn vorerst Ziel der Unternehmung, nur exemplarische Auszüge des gesamten Bestandes in die Datenbank einzutragen. So führte die Fülle an Daten dazu, dass eine Vorauswahl getroffen werden musste, um relativ rasch vorzeigbare Ergebnisse zu erhalten. Eine serielle Eingabe von Bestand um Bestand hätte keine aussagekräftigen Karten in absehbarer Zeit hervorgebracht. Bei der Vorauswahl der Daten fand eine Orientierung am Tirolischen Sprachatlas (1965–1971) von Egon Kühebacher statt, da dieser zahlreiche Karten enthält, deren Lemmata auch in unseren Beständen abgefragt wurden. Dadurch konnte der Umfang an zu erwartenden Formen für bestimmte Lexeme und lautliche Phänomene eingrenzt werden, was ein erstes Herangehen an die Kartenerstellung erleichterte. Die durchschnittlich 30 dazwischenliegenden Jahre haben die Sprachlandschaft Tirols, wenn auch nur mit geringfügigen Auswirkungen, verändert, was jedoch erst bei einem direkten Vergleich der Ergebnisse offensichtlich wird. So können Verschiebungen der Verbreitungsgebiete von Varianten beobachtet und dokumentiert werden.
Neben den ersten Eingaben in die Datenbank stand auch das Ausloten der Grenzen und Testen der Datenbank in den ersten Monaten des Projektes im Vordergrund, um in der späteren Praxis eine gute Funktions- und Arbeitsweise zu gewährleisten. Dafür wurde beispielsweise das Lemma schwarzer Alpensalamander (s. Karte unten) für die Eingabe ausgewählt. Viele Besonderheiten, wie etwa die Mehrfachbedeutung ein und desselben Ausdrucks oder die Vielgestalt der Bezeichungen für den gleichen Inhalt fallen dort zusammen und erschweren die Eingabe.
4.3. Dateneingabe und Annotierung
Unsere Datenbank DataWiki, in der alle relevanten Informationen zusammenlaufen, ist ein Ableger der Semantic-MediaWiki-Software und ein Produkt des Unternehmens DIQA Projektmanagement GmbH. Die Eingabe erfolgt dabei händisch über eine formularbasierte Wiki-Oberfläche. Der Eintrag eines Einzelbelegs erfordert die Angabe eines in der Lautschrift (s. 4.4) abgetippten Originalbelegs (OB), eines vereinfachten Belegs (VB) (s. 4.5) und eines etwaigen Explorationsvermerks sowie die Zuweisung zu einem Explorationsort und einer Frage in einem Fragebuch. Durch die kaskadierende Verknüpfung (wo sinnvoll) mit einem phonetisch-phonologischen, einem morpholexikalischen und schließlich einem semantischen Typ, wird dieser Einzelbeleg systematisch kategorisiert.
4.4. Lautschriftart
Für die digitale Abschrift der Belege haben wir uns für die Entwicklung und Verwendung einer eigenen Schriftart entschieden, die sowohl in der Ein- als auch in der Ausgabe der Teuthonista optimal an unsere Bedürfnisse angepasst ist. Die verschiedenen Generationen der Lösungsansätze spiegeln unseren Lernprozess wider. Anfänglich wurde auf die Schriftart MonacoSDS zurückgegriffen. Da ihr Zeichenumfang und ihr Bildungsprinzip für die Verarbeitung unserer Daten aber zu eingeschränkt war, traten wir an das Grafikbüro florianmatthias heran, um auf Grundlage einer bestehenden Schriftart eine voll funktionsfähige Lautschriftart für uns entwerfen und umsetzen zu lassen. Auf Grundlage der FF Tundra wurde die Taiga geschaffen, die den Großteil der benötigten Zeichen nun abbilden konnte und sich bei der Eingabe fortan an das Prinzip der graphischen Ähnlichkeit hielt, sodass sich das mit der Tastatur eingegebene und das auf dem Bildschirm ausgegebene Zeichen ähnlich sehen. Vor allem vielschichtige Zeichenkombinationen und der Wunsch nach einem noch einfacheren, eindeutigeren und intuitiveren Kodierungssystem (Betacode) legten jedoch die Gestaltung eines von Grund auf neuen Fonts nahe. Mit dem kompletten Neuentwurf einer Lautschriftart wurden die Typographen von Typejockeys betraut. Die neuerarbeitete Architektur soll sowohl die maschinelle Verarbeitung des Kodes als auch dessen Kompatibilität mit anderen Systemen sowie die modulare Darstellung der Glyphen gewährleisten: Grundzeichen werden dabei als Kleinbuchstaben (e > e), Alternativzeichen als Großbuchstaben (E > ə) und Diakritika als nachgestellte ASCII-Sonderzeichen (e:, > ę̈) eingegeben. Somit erhält jedes phonetische Zeichen einen eindeutigen Kode. Die Kodierungsreihenfolge der Diakritika ist fixiert und geht tendenziell vom höchst- zum tiefstgestellten. Die Position der Diakritika wird ausschließlich durch ihr Kodezeichen (e^ > ê aber e“ > ḙ) bestimmt, um Mehrdeutigkeit zu verhindern. Doppelte Diakritika werden durch doppelte Zeichen kodiert (e. > ẹ und e.. > e̤). Die erste Version der neuen, noch namenlosen Lautschriftart soll Anfang 2017 fertiggestellt sein.

Erscheinundsbild und Code der verschiedenen Lautschriftart-Generationen.
4.5. Vereinfachung des Belegs
Um die feingliedrige Teuthonista für Anwenderinnen und Anwender leichter lesbar sowie für Maschinen leichter verarbeitbar zu machen, wird bei der Eingabe von jedem Originalbeleg (OB) ein vereinfachter Beleg (VB) durch gewisse Regeln abgeleitet. Prinzipiell werden hierfür keine Diakritika genutzt und Alternativzeichen mit entsprechenden Grundzeichen wiedergegeben (α > a; ə > e; ʀ > r). Dabei gibt es allerdings Ausnahmen: Im Bereich der Vokale werden ę und ǫ zu ä und å vereinfacht, die Umlaute ö und ü bleiben. Nur Längen- (nur monophthongisch) und Nasalierungszeichen (nicht pränasal) sowie Zeichen für Unsilbigkeit (nur prävokalisch) werden mit zusätzlichen oder anderen Grundzeichen umschrieben (ē > ee; ẽ > e(n); i̯ > j; u̯ > w). Lange Diphthonge erscheinen kurz (ǭα > åa), Betonungszeichen bleiben erhalten (é > é). Im Bereich der Konsonanten fallen bei den Plosiven alle Halbfortes mit Fortes (d > d; τ, t > t), bei den Frikativen alle Fortes mit Lenes (s, ʃ > s), alle Bilabiale und Labiodentale (β, φ, f, v > f) sowie alle Gutturale (χ, x > ch), bei den Sonoranten alle r-Laute (r, ʀ, ρ > r) und alle l-Laute (l, λ > l) zusammen. Nur das Längenzeichen und das Zeichen für Stimmhaftigkeit bei v haben Auswirkung auf die Vereinfachung (t̄ > tt; ṿ > w). š–ʃ̌, χ–x und ŋ werden als Tri- bzw. Digraphen sch, ch und ng wiedergegeben.

Vereinfachung des Originalbelegs (OB).
4.6. Kategorisierung
Die Kategorisierung der Belege stellt die notwendige Basis für die Kartenerstellung dar (s. 4.7). Ausgewählte Phänomene können, so ist die Struktur des digitalen Sprachatlas TiDiOn angelegt, auf Ebenen unterschiedlichen Abstraktionsgrades kategorisiert werden. Abhängig von den vorliegenden Belegen und der gewünschten Differenzierung kann eine Kategorisierung auf der Ebene des belegnahen Stichworts (BSW) oder noch zusätzlich auf der Ebene des standardisierten Stichworts (SSW) vorgenommen werden. Liegt der Fokus auf der Darstellung der Verteilung verschiedener Lexeme in einem geographischen Gebiet, ist meist nur eine einstufige Kategorisierung über das BSW notwendig. Sind jedoch beispielsweise auch feine phonetische Unterschiede von Interesse, besteht die Möglichkeit, sowohl die lexikalische Verteilung als auch die lautlichen Feinheiten mithilfe von BSW und SSW abzubilden. Welche Option gewählt wird, hängt häufig davon ab, ob ein phonetisch-phonologisches, morphologisches oder lexikalisches Phänomen abgebildet werden soll. Es muss von Fall zu Fall entschieden werden, welche Option sich im Speziellen eignet. Die Kategorisierung selbst muss von den Eingebenden vorgenommen werden. Eine automatische Zusammenfassung der Belege aufgrund ihrer Schreibung in Teuthonista ist nicht möglich, da die Einzelbelege zu heterogen sind. Durch die Zuordnung jedes Belegs zu einem (nur BSW) oder fallweise zwei Stichwörtern (BSW und SSW) werden die Farben der Belegfähnchen vergeben. Derzeit erlaubt uns das System nicht, verschiedene Symbole zusätzlich zu farblich unterscheidbaren Belegfähnchen zu nutzen. Diese Einschränkung und auch die händische Vergabe von Farben zur besseren Lesbarkeit der Karten sollen durch eingreifende Maßnahmen in die Datenbankstruktur möglich werden.
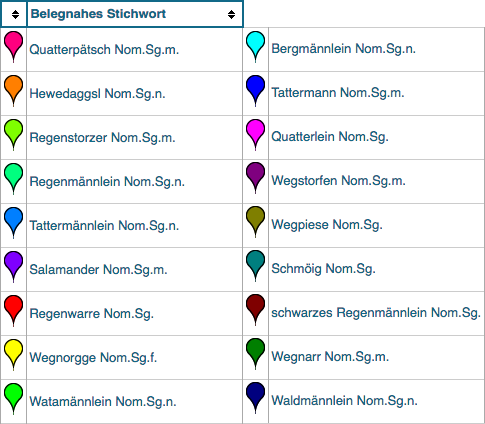
Anhand des Beispiels schwarzer Alpensalamander sollen die Möglichkeiten der Kategorisierung nachgezeichnet werden. Die sprachliche Vielfalt der Bezeichnungen, die in Tirol für dieses Tier verwendet wurde/wird, lässt sich am besten auf einer Karte abbilden, die die lexikalischer Verteilung widerspiegelt. Dabei werden Formen wie etwa tạtr̥męnlǝ oder tọtǝʀmandlę unter dem von uns konstruierten SSW Tattermännlein zusammengefasst, wie auch etwa wẹ̄gnǭr und wēgnǫṛ unter Wegnarr zusammenfallen. Die phonetischen Unterschiede werden dabei über das BSW erfasst werden. Das BSW ergänzt die lautlichen Differenzen, die beim SSW außen vor gelassen werden und ist damit näher am realen Beleg zu verorten. Tatermandlä, Totermenlä und Weegnår wären somit exemplarische Beispiele für BSW. Eine gemeinsame Darstellung von BSW und SSW auf einer Karte ist durch ihren unterschiedlichen Abstraktionsgrad nicht möglich, sie werden auf zwei verschiedenen Karten abgebildet. Die unterschieldlichen Stichwörter der BSW und SSW werden auf der Karte in verschiedenen Farben wiedergegeben und bestimmen maßgeblich den Gehalt der Karten. Bei Interesse an der tatsächlichen Realisierung eines Belegs an einem bestimmten Ort kann der Originalbeleg zusätzlich über die Karte abgerufen werden.

Kategorisierung des Originalbelegs (OB) auf den Ebenen des belegnahen (BSW) und des standardisierten Stichwortes (SSW) am Beispiel schwarzer Alpensalamander.
4.7. Darstellung und Ausgabe
Die Darstellung und Ausgabe der eingegebenen Daten erfolgt als interaktive Sprachkarte. Momentan bedienen wir uns dabei des Online-Kartendienstes Google Maps, der in unser Semantic MediaWiki implementiert ist. Anhand der Position und Farbe einzelner Belegfähnchen und der Legende lässt sich die geographische Verteilung der sprachlichen Merkmale ablesen. Zusätzliche Informationen zum Erhebungspunkt werden in einer Sprechblase eingeblendet, die durch Anklicken des jeweiligen Belegfähnchens erscheint. Dazu gehören der Originalbeleg, der vereinfachte Beleg (als Lesehilfe), die Initialen der Exploratorinnen und Exploratoren, deren Vermerke sowie der Name des Erhebungsortes. Durch das Anklicken mehrerer Belegfähnchen können somit direkte Vergleiche zwischen zwei oder mehreren Belegen gezogen werden.
Bei der vollständigen Eingabe aller Belege zu einer bestimmten Frage steht am Ende des Prozesses folgendes Ergebnis: eine Karte, die die geographische Verteilung lexikalischer Varianten des Lemmas Schwarzer Alpensalamander aufzeigt. Vorherrschend sind vor allem die Formen Tattermännlein im Oberinntal und Wegnarr im Tiroler Unterland. Häufig, wenn auch mit Abstand zu den erstgenannten, folgt Wegnorgge im Bezirk Landeck. Das Vorkommen anderer Belege ist auf wenige bis einmalige Nennungen beschränkt.
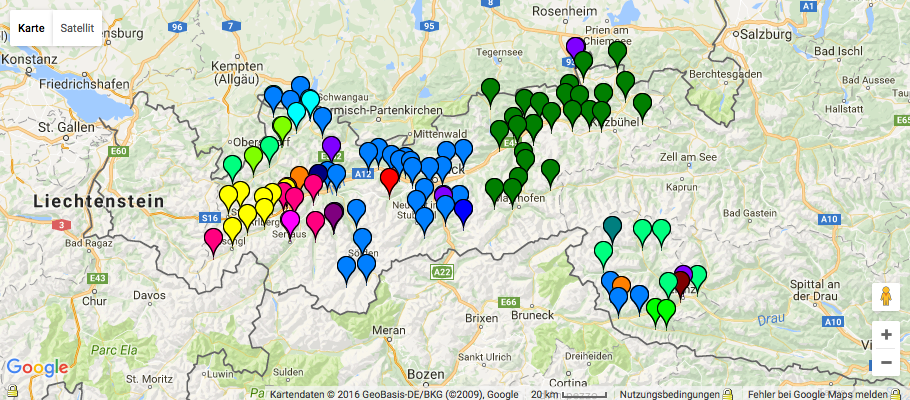
Kartographische Darstellung der linguistischen Daten am Beispiel der lexikalischen Varietäten des Lemmas schwarzer Alpensalamander.
5. Ausblick
Nach dem mehrmonatigen Testbetrieb des Datenbanksystems haben sich Herausforderungen herauskristallisiert, die es zukünftig zu lösen gilt und an denen derzeit vor Ort in Zusammenarbeit mit dem Zentralen Informatikdienst der Universität Innsbruck gearbeitet wird. Dazu zählen etwa Umstrukturierungen innerhalb der Datenbank, die Einbettungen von Ton- und Bilddateien oder auch die Schaffung eines größeren Gestaltungsspielraums bei der Datenausgabe in Kartenform. In die Überarbeitung der Datenbank fließen auch Überlegungen und Anforderungswünsche ein, die für den derzeitigen Projektfortgang nur nebensächlich sind, aber in naher Zukunft an Bedeutung gewinnen könnten. Darunter fällt die Möglichkeit, Dateien an Belege und Bedeutungen anzuknüpfen, die der besseren Interpretierbarkeit und der leichteren Verständlichkeit zuträglich sind. Die zukünftige Kartenerstellung soll sich thematisch an den Bereichen Mensch und Gesellschaft, Haushalt und Küche sowie Pflanzen und Tiere orientieren. Sobald eine ausreichende Anzahl an aussagekräftiger Karten zur Verfügung steht, werden diese mit einem entsprechenden Kommentar veröffentlicht und einem breiten Publikum online präsentiert.
6. Kontakt
![]()
Mag. Dr. Simon Pickl
Mag. Dr. Yvonne Kathrein (Karenz)
David Gschösser BSc BA
Julia Schönnach BA
Tiroler Dialektarchiv
Institut für Germanistik
Universität Innsbruck
Innrain 52d
6020 Innsbruck
Österreich
www.tiroler-dialektarchiv.at
tiroler-dialektarchiv@uibk.ac.at
+43 512 507-41386
Bibliographie
- Kühebacher et al. (1965–1971) = Kühebacher, Egon et al. (1965–1971): Tirolischer Sprachatlas. 3 Bände, Marburg, N. G. Elwert