




Thomas Krefeld | Stephan Lücke
Contributo al convegno "Lingue e culture della montagna", Torino / Bobbio Pellice, 15./16.5.2015
Indice del contributo
- 0. Dimensioni di VerbaAlpina
- 1. Documentazione (esempi)
- a. I dati dell’AIS
- b. I dati del VALTS
- 2. Cooperazione: Dati dei nostri partner (esempi)
- a. “Archivio lessicale dei dialetti trentini” (ALTR)
- b. L’atlante del ladino dolomitico (ALD)
- 3. Rilevamento (Crowd)
- 4. Pubblicazione
0. Dimensioni di VerbaAlpina
Sono ormai sette mesi che lavoriamo su VerbaAlpina (= VA) ed è questa una bellissima occasione per invitarVi sul cantiere e presentarVi lo stato attuale del progetto; Vi proponiamo una specie di consultazione guidata del sito e ci permetteremo anche di rivolgerci più o meno direttamente ai partner VA presenti stasera in quest’aula.
Va ricordato all'inizio la cornice mediale che è fondamentale per la concezione e lo svolgimento del progetto: Si tratta di una piattaforma online, che vuol sfruttare in modo conseguente le opzioni forniteci dalla tecnologia web ed evitare nello stesso tempo le soluzioni ibride, ancora difusissime in questa fase di transito mediale. La trasformazione non tocca certamente l'obbiettivo della ricerca scientifica; la comunicazione scientifica però è sostanzialmente cambiata (cf. Krefeld 2011). La differenza forse più vistosa riguarda le tappe successive del lavoro scientifico tradizionale che sbocca nella pubblicazione dei risultati. Non è affatto più possibile (neanche desiderabile) separare nettamente diverse fasi di un lavoro che si organizza molto più efficacemente in funzioni parallele e strettamente intrecciate. Sono essenzialmente quattro funzioni, che vengono descritte in seguito:
- documentazione,
- collaborazione,
- rilevamento,
- pubblicazione.
Per garantire l'ingranaggio operativo di queste funzioni occorre utilizzare esclusivamente software con un codice sorgente aperto ('open source') e di rinunciare all'uso o allo sviluppo di software proprietario. È dunque a priori problematico collaborare con ditte private o anche istituzioni statali che rischiano di rivendicare diritti di proprietà (sia per motivi statali o politici). Il linguaggio non appartiene a nessuno, meglio: è una risorsa di tutti, e lo dovrebbe essere anche sotto forma digitalmete codificata.
1. Documentazione
La prospettiva della documentazione è etnolinguistica; sono scelte certe tecniche culturali e fenomeni caratteristici dell'ambiente naturale alpino assieme alle designazioni dialettali corrispondenti. Tutti i dati sono presentati sotto forma cartografica virtuale, che esige la georeferenziazione di ogni dato. escludendo ovviamente qualisiasi informazione non georeferenziabile. L'utente ha la possibilitè di selezionare alternativamente concetti o tipi linguistici. Ecco un esempio che mostra sul tema dei fabbricati d'alpeggio (designazioni|foto); per il momento le foto non sono ancora implementate nella cartografazione.
I dati etnolinguistici sono completati da certi dati extralinguistici adatti a fornire informazioni sulla formazione del 'paesaggio' etnolinguistico in generale e specialmente alla diffusione di varianti dialettali. La funzione Carta sinottica permette anche di comporre e di salvare carte individuali combinando liberamente concetti, tipi lessicali e/o dati extralinguistici, come ad esempio i luoghi delle strade romane secondo la tavola Peutingeriana e i monasteri alpini. Nella zona oggi tedescofona la loro fondazione che risale delle volta fin al 8. secolo d.C. assiem alla ubicazione vicino a necropoli e insediamenti romani (non ancora georeferenziati) fa pensare a una continuità romanza fin al medioevo (vd. strade romane_monasteri).
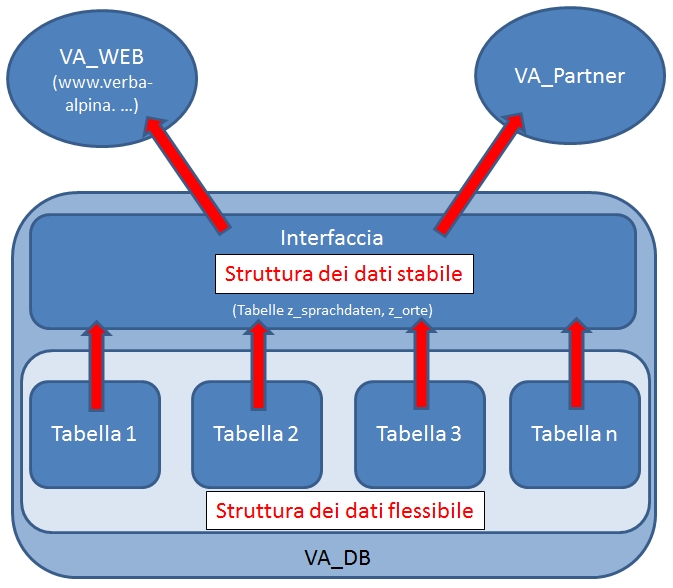
VerbaAlpina ricongiunge dunque in un solo sistema un’ampia quantità di dati di fonti varie.Tutto sommato differenziamo in atlanti linguistici, dizionari, partner di cooperazione e la cosiddetta “crowd” come delle fonti dei dati. Ognuna di queste categorie ed anche le fonti per sé si presentano come delle sfide. Essenzialmente si tratta di un trasferimento di tutti i dati, indipendentemente dell’origine, in una struttura dei dati ed in una codifica dei simboli uniforme. Non prima d'ora si può comperare ed analizzare tutto il materiale.
Nel mettere assieme le diverse fonti dei dati di VerbaAlpina, la struttura scelta dei dati e la codifica dei simboli di VerbaAlpina si presenta come il punto di partenza e la base per le diverse soluzioni di scambio dati.
In primo luogo VerbaAlpina è orientato lessicalmente. Dunque in primo piano troviamo le parole e i loro significati, o formulato in modo diverso: i concetti e i significanti con cui vengono nominati.
VerbaAlpina si è deciso per l’uso del cosiddetto modello relazionale. La sua caratteristica è la disposizione dei dati in formato di tabelle. Nel caso più facile – per dimostrarVi un’ esempio- il fatto che il concetto “cascina di montagna” è denominato da “baita” – viene rappresentato nel modello relazionale nel modo seguente:
| PAROLA | CONCETTO | NOME DEL COMUNE | LONGITUDINE | LATITUDINE | ANNO | FONTE |
|---|---|---|---|---|---|---|
| baita | CASCINA DI MONTAGNA | Monasterolo del Castello | 9.9327 | 45.7641 | 1940 | AIS 1192_1, 247 |
Siccome si tratta di un progetto geolinguistico, le geocoordinate del luogo, dal quale sono i dati, vengono salvate supplementarmente. Il riferimento cronologico (chronoreferenzierung?) in forma della data della publicazione o del rilevamento originale permette un’analisi diacronica. La citazione della fonte è necessaria per assicurarci scientificamente parlando la autenticità.
Partendo da un'attestazione concreta VerbalAlpina distingue diversi livelli d’astrazione. Inizialmente – seguendo i criteri della fonetica storica – vengono riassunti dei tipi fonetici a base della similarità fonetica delle attestazioni. I tipi fonetici vengono dunque riassunte come tipi morfologici cioè lessicali sulla base di pochi criteri morfologici (categoria lessicale, parola semplice/derivazione).

In fine la categoria “tipo di base” comprende alcuni tipi morfologici estendosi su lingue diverse.
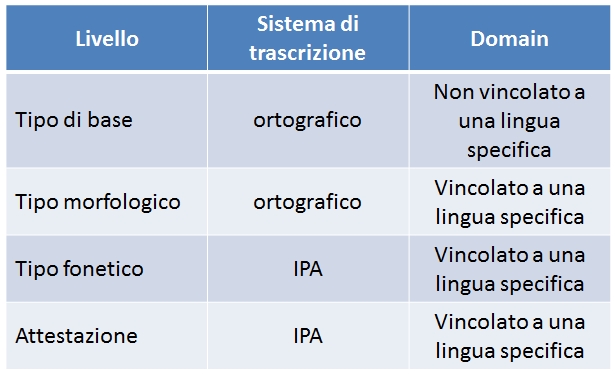
Usando la trascrizione IPA per l’attestazione concreta ed il tipo fonetico, i tipi morfologici ed il tipo di base vengono presentati in ortografia standard, che si orienta, per quanto è possibile, alla grafia dei dizionari di riferimento da noi definiti. In questo contesto i dizionari del Ticinese Repertorio italiano – dialetti (RID) e Lessico dialettale della Svizzera italana (LSI) sono di enorme importanza per l’area alpina romanza, perché registrano, in modo facilmente leggibile anche numerosi tipi lessicali della regione alpina, diffusi anche al di là dello stesso Ticino.

I vari livelli della tipizzazione vengono raccolti in una singola tabella con una selezione di metadati importanti, per esempio informazioni sulle fonti, quindi la bibliografia, o la loro origine geografica e la data del rilevamento, racchiusi in una singola tabella. Questa tabella funziona in doppio modo: d'una parte la tabella costituisce la cosiddetta interfaccia di accesso ai dati, di cui la superficie di VerbaAlpina si serve per la produzione delle carte linguistiche interattive, e dell'altra fa parte dell’interfaccia VAP, con cui VerbaAlpina mette a disposizione i suoi dati ai partner di cooperazione. I dati georeferenziati, che non si riferiscono alla lingua, sono raccolti in una propria tabella, che forma l’altra parte dell’interfaccia VAP
Datenzugriffsschicht
<stephan>
Durante la fase corrente della collezione dei dati, una delle sfide essenziali è il trasferimento del materiale linguistico degli atlanti, dei dizionari e dei partner di cooperazione nel sistema abbozzato di VerbaAlpina. Ciò vorremmo presentare nei selezionati esempi seguenti :
a. I dati dell'AIS
<folie 9> I dati dell’AIS presentano direttamente, seguendo la tradizione romanza degli atlanti linguistici, le attestazioni nella trascrizione fonetica del sistema Böhmer-Ascoli. Normalmente queste attestazioni, che sono iscritte sulla carta, designano il concetto, a cui la carta è dedicata. Nel caso concreto, però non raramente, si capisce dalle spiegazioni ed annotazioni, che un'attestazione speciale non corrisponde esattamente al concetto principale, bensì a una varietà particolare o un concetto subordinato.
La grafica <in seguito> mostra un frammento della carta AIS 1992_2, che è dedicata al concetto "cantina da latte, da formaggio" in forma di una lista.

Le attestazioni che sono marcate con la freccia rossa designano gli informazioni aggiunti nell’atlante in conseguenza della variazione particolare del concetto di base. Nel rilevamento dei dati nella Banca Dati questo fatto viene registrato così <folie 10>:
Nella registrazione dei dati, il linguista deve decidere a quale categoria sistemica si deve assegnare un’attestazione documentata nella fonte. In generale vengono presi in considerazione le attestazioni individuali dall’informante ossia tipi morfologici. Nel caso dell’AIS si tratta sempre di attestazioni individuali. Ciò viene registrato appropriatamente nella banca dati VA.
Generalmente la registrazione del materiale degli atlanti si può difficilmente automatizzare e quindi si deve fare manualmente. A questo punto si solleva il problema della trascrizione fonetica specialmente di fronte alle attestazioni individuali <folie 11>. Questo è un problema doppio: anzitutto si deve trovare un modo per registrare i simboli idiosincratici non ancora codificati in Unicode con una tastiera europea occidentale. A ciò, dal nostro punto di vista, il cosiddetto betacode, in cui questi simboli sono tradotti in successioni di simboli ASCII, ha dato buona prova. L’altro problema della registrazione delle attestazioni individuali è quello di trasferire le particolarità fonetiche in IPA, che è la nostra trascrizione di riferimento. Solo dopo il trasferimento in IPA delle fonti in varie sistemi di trascrizione tutto il materiale sarà comparabile e analizzabili. Per quanto è possibile questa trasposizione in IPA risulta usando un'algoritmo di sostituzione.

b. I dati del "Vorarlberger Sprachatlas" (VALTS)
Diversamente dal'AIS, l'atlante "Voralberger Sprachatlas" (atlante linguistico di Voralberg, e del Tirolo occidentale) segue la tradizione germanistica degli atlanti linguistici, che funziona in generale con carte a punti e simboli che documentano le attestazioni solo in casi particolari. Dalle carte del VALTS si possono dunque rilevare solo i tipi morfologici. L'esempio mostra la carta del VALTS IV 73, che è dedicata ai concetti "cascina di montagna" e "stanza per la lavorazione del latte". Per quanto riguarda la registrazione delle poche attestazioni individuali si deve differenziare se si riferiscono al concetto "cascina" o "stanza nella cascina". Ritroviamo dunque il problema dell'AIS. <folie 12> Ora vorrei mostrarVi il frammento della carte equivalente:

Si vede che la carta presenta un mischio di tipi fonetici come "Tieje" o "Taje" da un lato e dall'altro di tipi morfologici come "Hütte" (baita) e "Sennküche" (cucina nella cascina di montagna), in cui però l'ultimo tipo appunto non significa la cascina in tutto, bensì solamente una parte di essa, cioè "stanza dove si lavora il latte ed il formaggio nella cascina di montagna". L'esempio verde invece mostra il caso in cui inoltre al tipo morfologico viene documentato l'attestazione diretta dell'informante.
<folie 13> Nella Banca Dati di VerbaAlpina gli esempi accennati saranno registrati come segue (i colori della tabella corrispondono alle marcature della carta appena mostrata).

Nel caso del concetto "cucina nella cascina di montagna in cui si lavora il latte ed il formaggio" il VALTS nasconde le attestazioni. In conseguenza le celle "attestazione" (ted. 'Beleg'),"Betacode" e "IPA" non possono essere definiti. Nel nostro grafico mettiamo dunque il punto interrogativo. Nella banca dati queste celle restano semplicemente vuote. E nel caso di "Taje" e "Tieje", al contrario, l'atlante fornisce solo attestazioni senza proporre un tipo morfologico, che deve essere identificato cioè raggiunto da VerbaAlpina, poichè si tratta di una categoria onomasiologica fondamentale. Questo passo richiede delle conoscienze speciali e viene effettuato su base di certi dizionari di riferimento che ci prestano le loro varianti lemmatizzate come forme rappresentative del tipo morfologico. <folie 14> Nel caso presente abbiamo scelto la voce "Teie" del IDITIKON, il dizionario del tedesco svizzero, per raggruppare le attestazioni Taje, Toje, Teje ecc. .

2. Cooperazione: Dati dei nostri Partner
VerbaAlpina ha degli accordi di cooperazione con una moltitudine di partner, dai cui la maggior parte dispone già di dati linguistici georeferenziati.
<folie 15> Siccome finora non esiste uno standard vincolante, si deve creare e realizzare un'interfaccia particolare per i dati d'ogni partner, che adatta le strutture e le codifiche dai dati esterni allo standard di VerbaAlpina.
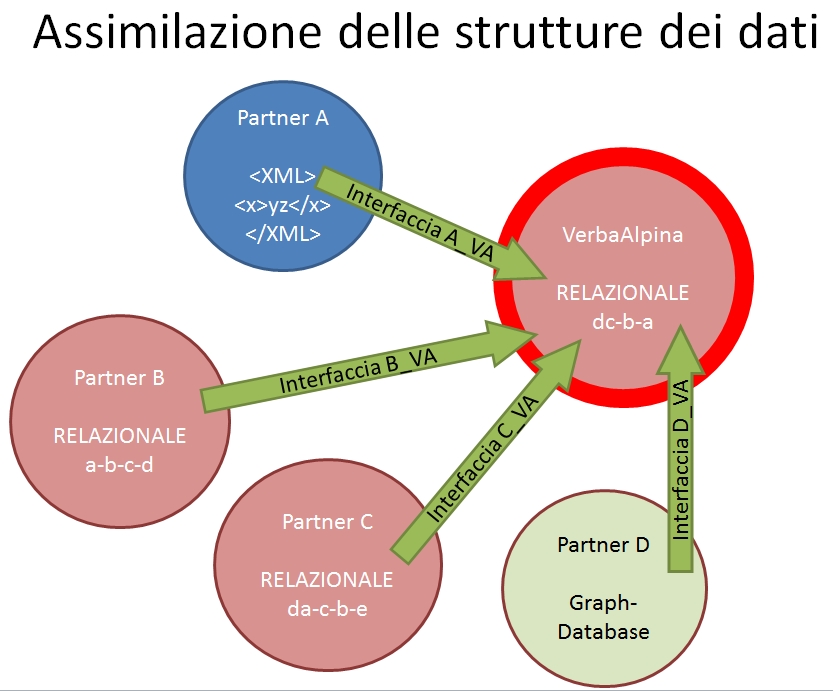
Purché i nostri partner usino anche il modello relazionale, mettiamo a disposiszione una banca dati MySQL, che non si può usare solamente per il trasferimento dei dati, ma anche per l'uso produttivo dei partner, cioè per caricare altri dati.
2a. "Archivio lessicale dei dialetti trentini" (ALTR)
VerbaAlpina ha già ricevuto dei dati di alcuni partner di cooperazione. L'esempio seguente si riferisce all' "Archivio lessicale dei dialetti trentini" (ALTR), condotto di Patrizia Cordin. I dati dell'ALTR sono salvati nella banca dati MySQL PV_ALTR. La sigla "PVA_" vuol dire: Partner di VerbaAlpina. Siccome tanti delle nostre fonti e partner, anche l'ALTR usa un proprio sistema di trascrizione fonetica, che si deve trasferire nella nostra trascrizione di riferimento IPA per gli intendimenti di VerbaAlpina. Sostanzialmente il modo di agire è come abbiamo già spiegato nel contesto dell'AIS. Quindi non dobbiamo approfondire. Però naturalmente è più confortabile, confrontato all'AIS, perché la registrazione manuale non è necessaria.
<folie 16> Sull'esempio dell'ALTR, invece, si può illustrare un altro problema, che riguarda anche altre fonti, come il TSA (atlante linguistico del Tirolo), cioè adattare diverse strategie di georeferenziazione. L'unità di riferimento per VerbaAlpina è il comune. I dizionari registrati dall'ALTR si riferiscono ad aree più estesi, come parti superiori o inferiori di certe vallate. Il procedimento si presenta come segue:

Dalla registrazione originale dell'ALTR (Marcatura A) si capisce che il tipo fonetico “agraöil” (recipiente per conservare il caglio, da agro) esiste nella Alta Val di Sole. Oltre a ciò si trovano delle varianti locali, ad esempio “agraöl” in Peio e Vermiglio o “agröl” in Pelliziano. Seguendo la divisione regionale (Marcatura B), che è documentata nella banca dati dell'ALTR, i luoghi Vermiglio e Mezzana fanno parte dell'Alta Val di Sole. Ne consegue che il tipo “agraiol” è attestato in due luoghi. Ma secondo il commento nella cella Varianti_in_uso esiste una variante a Vermiglio, “agraöl” – un tipo che è attestato a Peio, e questo è un luogo che si trova in Val di Peio. La variante “agröl” infine è attestata a Pelliziano, che si trova anche fuori dell'Alta Val di Sole. Sulla base del riferimento a punti, differenziamo contemporaneamente diversi tipi fonetici e l'archiviazione dei dati appena descritti risulta nella banca dati di VerbaAlpina in cinque passi. (Marcatura C)
2b. "L'Atlant linguistich dl ladin dolomitich y di dialec vejins", 2a pert (Sprachatlas des Dolomitenladinischen und angrenzender Dialekte, 2. Teil) di Hans Goebl (ALD-II)
<folie 17> Abbiamo ricevuto i dati dell'ALD-II, come quelli dell'ALTR, già in forma relazionale. Oltre a ciò questo corpus è localmente georeferenziato. I dati linguistici poi consistono da attestazioni dirette. Quindi l'adeguamento strutturale alla Banca Dati VerbaAlpina non pone problemi sostanziali. L'unica sfida è in questo caso il trasferimento del sistema di trascrizione del ALD in IPA. Il trasferimento viene effettuato in due passi: si 'traduce' il Betacode del ALD, che è una trascrizione a base di simboli ASCII, seguendo le regole dell'ALD in un sistema di trascrizione che assomiglia al sistema di Böhmer-Ascoli. In seguito questa trascrizione viene trasferita in IPA. I due passi vengono effettuati automaticamente con l'uso di algoritmi di sostituzione.

Tutti i dati, che sono raccolti da fonti varie e che sono standardizzati in riferimento alla struttura e la codifica, vengono messi alla disposizione dei partner usando l'interfaccia VAP che esiste in tre lingue diverse, italiano, (VAP_it), francese (VAP_fr) e tedesco (VAP_de). <folie 18> Questa interfaccia è accessibile con l'indirizzo web https://pma.gwi.uni-muenchen.de:8888 e contiene le celle dei dati seguenti:

</stephan>
3. Rilevamento (Crowd)
Questa funzione non è ancora attiva; è prevista una'applicazione che si rivolge direttamente ai locutori per rilevare dati linguistici recenti; questa funzione sarà utilissima per vari motivi. Innanzitutto fornisce dati recenti, capaci di confermare, di attualizzare e di aricchire i dati atlantistici e lessicografici mai completi e delle volte anche invecchiati o imprecisi. Facciamo un esempio. AIS 1192 LA CASCINA DI MONTAGNA e AIS 1192a danno 1032 attestazioni per diversi tipi di fabbricati alpestri e il cambio d'alpeggio in 134 paesi alpini. Tutto il materiale linguistico è raggruppato sotto il titolo della carta e sotto i titoli di parecchi elenchi supplementari:
- LA CASCINA DI MONTAGNA
- LA CANTINA DA LATTE
- LA CANTINA DA FORMAGGIO
- I 'MAGGENGHI'
- LA STALLA D'ALPE
- LA CAMERA DA LETTO NELLA CASCINA
- VARIE CAPANNE
- TRAMUTARSI
A prima vista sembrano essere rapporti univoci tra designazioni e concetti. Moltissime attestazioni sono però precisate per quanto riguarda la materia, la costruzione, la funzione ecc. del fabbricato, in modo che ne risultano 120 concetti subordinati potenziali, senza che sia chiaro se queste precisazioni esprimono tratti semantici del tipo lessicale o, magari, delle qualità di un referente particolare. Un nuovo rilevamento chiarirebbe dunque la semantica e ci fornirebbe informazioni su eventuali sostituzioni delle parole ecc.

4. Pubblicazione
E’ chiaro che la documentazione sul web rappresenta in sé già una forma di pubblicazione; VA però non si accontenta di documentare dati grezzi. La piattaforma comprende anche diverse rubriche per testi linguistici che focalizzano in parte lo stesso progetto e in parte il materiale offerto da esso.
invitati da
(1) Il tab METODOLOGIA dà accesso a un elenco ragionato di alcuni concetti chiave di VerbaAlpina, in modo di chiarire i principi scientifici del progetto.
(2) Sotto il tab TESTI sono registrati innanzitutto contributi che discutono dati o aspetti metodologici di VerbaAlpina; si trovano saggi dei collaboratori ma ovviamente sono molto graditi anche articoli 'esterni', a condizione di trattare problemi rilevanti. Vengono distinti contributi pubblicati altrove (pubblicazioni esterne), studi originali (come questo testo sott'occhio) e materiale informativo.
(3) Ogni categoria che si può selezionare sulla carta interattiva (dati extralinguistici, concetti, carte sinottiche) può essere accompagnato di un commento (vd. Käse). Si potrebbero quindi inserire perfettamente i testi analici dell'Atlas des patois valdôtains e si aspetta che i partner che forniscono dati o che compongono nuove carte sinottiche scrivono pure commenti corrispondenti.
Va detto finalmente che la piattaforma coinvolgerà al di là delle cooperazioni con progetti scientifici anche locutori non linguisti; ma si tenga conto che entrambe le categorie non possono avere gli stessi diritte: i progetti partner dispongono ognuno di un database particolare dentro l‘architettura di VerbaAlpina che possono modificare liberamente; sono anche invitati a pubblicare commenti e contribut
Va detto finalmente che la piattaforma coninvolgerà al di là delle cooperazioni con progetti scientifici anche locutori non linguisti; ma si tenga conto che entrambe le categorie non possono avere gli stessi diritte: i progetti partner dispongono ognuno di un database particolare dentro l‘architettura di VerbaAlpina che possono modificare liberamente; sono anche invitati a pubblicare commenti e contribute nelle funzioni presentati. Eventuali commenti da parte degli utenti non linguisti non saranno mai pubblicati senza valutatazione positiva dai linguisti responsabili del progetto.
Bibliografia
- Lessico dialettale della Svizzera italana (LSI) = Lurà, Franco (Hrsg.) (2004): Lessico dialettale della Svizzera italana, Bellinzona, Centro di dialettologia e di etnografia
- Repertorio italiano – dialetti (RID) = Lurà, Franco/ Galfetti, Johannes (2013): Repertorio italiano – dialetti, Bellinzona, Centro di dialettologia e di etnografia, CDE