

Abstract
Die Untersuchungsgebiete der Dialektologie werden üblicherweise nach nationalen und nationalsprachlichen (d.h. politischen) Kriterien zugeschnitten. Das ist geolinguistisch unangemessen und wird weder den grenzüberschreitenden Räumen noch den traditionell mehrsprachigen Arealen gerecht. Ein Untersuchungsgebiet wie der Alpenbogen, in dem die drei großen europäischen Sprachfamilien (Romanisch, Germanisch, Slawisch) seit anderthalb Jahrtausenden in Kontakt stehen, erzwingt die Überführung der Dialektologie in eine interlinguale Geolinguistik. Denn nur so wird es möglich die historische Verflechtung der drei Kontinua (Romanisch, Germanisch, Slawisch) mit ihrer ausgeprägten lokalen Variation zu erfassen. Auf der Grundlage von Web-Technologie wird im Projekt VerbaAlpina (https://www.verba-alpina.gwi.uni-muenchen.de/) seit 2014 eine entsprechende Methodologie in der Perspektive der Digital Humanities entwickelt.
1. Eine dynamische Disziplin
Die Geolinguistik untersucht die Raumgebundenheit und die räumlich bedingte Variation der Sprachen. Die methodologische Entwicklung der Disziplin – um die wertende Rede von ihrem ‘Fortschritt’ zu vermeiden – spiegelt veränderte Sprachauffassungen ebenso wie den tiefgreifenden Wandel der Medien. Besondere Herausforderungen ergaben sich einerseits aus der kontinuierlich wachsenden Bedeutung, die der Mehrsprachigkeit im Allgemeinen und der mehrsprachigen Kompetenz der einzelnen Sprecher*innen im Besonderen beigemessen wurde und andererseits aus dem zunehmenden Einsatz von Webtechnologie in der Forschungspraxis.
2. Von der traditionellen Einsprachigkeit zur Mehrsprachigkeit
Die traditionelle Dialektologie1 zielt auf die Beschreibung monodimensional verstandener sprachlicher (dialektaler) Systeme; Variation innerhalb der lokalen Sprachen wird weitestgehend ausgeblendet. Gerade diese Forschungstradition hat in Gestalt der Sprachatlanten eine spezifische und mittlerweile ebenso elaborierte wie differenzierte Form der Dokumentation hervorgebracht. Aber diese Gattung macht auch auf einige nachgerade erstaunliche Beschränkungen aufmerksam (vgl. Krefeld/Lücke 2021):
- Die Untersuchungsgebiete der dialektologischen Forschung werden – außer Im Fall lokaler Einzelstudien – üblicherweise nach Maßgabe nationaler und nationalsprachlicher (d.h. politischer) Territorien2 zugeschnitten; das gilt gerade auch im Fall der Regionalatlanten, die Teilen des nationalen Territoriums gewidmet sind (vgl. z. B. ALG). Dieses Prinzip ist in doppelter Hinsicht fragwürdig:
- Es verzerrt die Darstellung des romanischen Kontinuums, weil es eine Relevanz der Staatsgrenzen suggeriert; Staatsgrenzen sind aber allenfalls Grenzen der Standard- bzw. Dachsprachen, die sich gerade nicht auf die Gliederung der überdachten Varietäten abbilden lassen.
- Es hat zur systematischen Vernachlässigung grenzüberschreitender Areale geführt. - Traditionell nicht romanischsprachige Areale, deren Sprachen auf keinen Fall ‘Dialekte’ der Nationalsprachen sein können, werden innerhalb nationaler Territorien oft nicht berücksichtigt; das ist wegen der häufig festzustellenden historischen Verschiebung der Sprachgrenzen in Folge von arealem Sprachwechsel unglücklich, denn es erschwert die Dokumentation und Analyse der historischen Sprachkontakts.
Die beiden Punkte sind übrigens starke Argumente dafür, raumorientierte sprachwissenschaftliche Forschung nicht grundsätzlich unter dem engen Begriff der Dialektologie, sondern eher unter dem weiteren Begriff der Geolinguistik zu subsumieren. Im Projekt VerbaAlpina wird das dialektale Lexikon des Alpenraums dokumentiert; der Alpenraum wird über die politischen Gemeinden definiert, die im Perimeter der sogenannten Alpenkonvention liegen. Da in diesem Untersuchungsgebiet die drei großen europäischen Sprachfamilien (Romanisch, Germanisch, Slawisch) seit anderthalb Jahrtausenden in Kontakt stehen, war es weiterhin notwendig die Geolinguistik als interlingual zu spezifizieren.
2.1 Die Modellierung der Mehrsprachigkeit
Auf der Kartenoberfläche wird die Mehrsprachigkeit des Untersuchungsgebiets als synchrones räumliches Nebeneinander der drei genannten Sprachfamilien modelliert (vgl. Interaktive Karte). Auf die Spezifizierung von Einzelsprachen (’Italienisch’) und Dialektzonen (wie z.B. ‘Lombardisch’) wurde dagegen verzichtet; die Bezugsgröße der Georeferenz ist grundsätzlich die politische Gemeinde, d.h. es werden potentiell die lokalen Sprachen (Dialekte) sämtlicher, beinahe 6000 Gemeinden der Alpenkonvention identifiziert. Für zahlreiche Gemeinden sind natürlich de facto (noch) keine Daten verfügbar. Die Gruppierung der lokalen Sprachen/Dialekte zu regionalen Typen wie z.B. Lombardisch ist zwar ein traditionelles Anliegen der Sprachgeographie, das sich in einigen bekannten Karten niedergeschlagen hat. Aus einer Bottom Up-Perspektive, die von lokalen Daten ausgeht, ist die dort vorgeschlagene Zonierung jedoch wenig transparent und nicht zielführend. Es steht den Nutzern aber selbstverständlich frei eine eigene Klassifikation vorzunehmen und einen lokalen Dialekt, der z.B. in der Region Lombardia liegt, der zur Alpenkonvention gehört und in VA mit Sprachdaten belegt ist, wie z.B. den Dialekt von Colico am Comersee, als ‘lombardisch’ zu bezeichnen.
Übrigens ist schon die Zuordnung einer Gemeinde zum Gebiet einer der drei Sprachfamilien alles andere als selbstverständlich, denn es werden bereits in der Zusammenschau der unten genannten Quellen historische Verschiebungen sichtbar. Vor allem in Graubünden sind mehrere Orte, die in den Netzen des AIS (Kartensymbol A) und vor allem des DRG (Kartensymbol B) als romanischsprachig geführt werden, mittlerweile zum Deutschen gewechselt, d.h. sie liegen auf der folgenden Karte im grün unterlegten Gebiet. Man beachte, dass alle VA-Karten rein virtueller Natur sind und nur auf den Endgeräten der Nutzer erscheinen; es liegen also keine digitalisierten graphischen Karten zu Grunde, wie es in anderen geolinguistischen Projekten, die online konsultierbar sind, der Fall ist. Die virtuelle Kartographie wurde von Florian Zacherl und vor allem von David Englmeier konzipiert und implementiert.
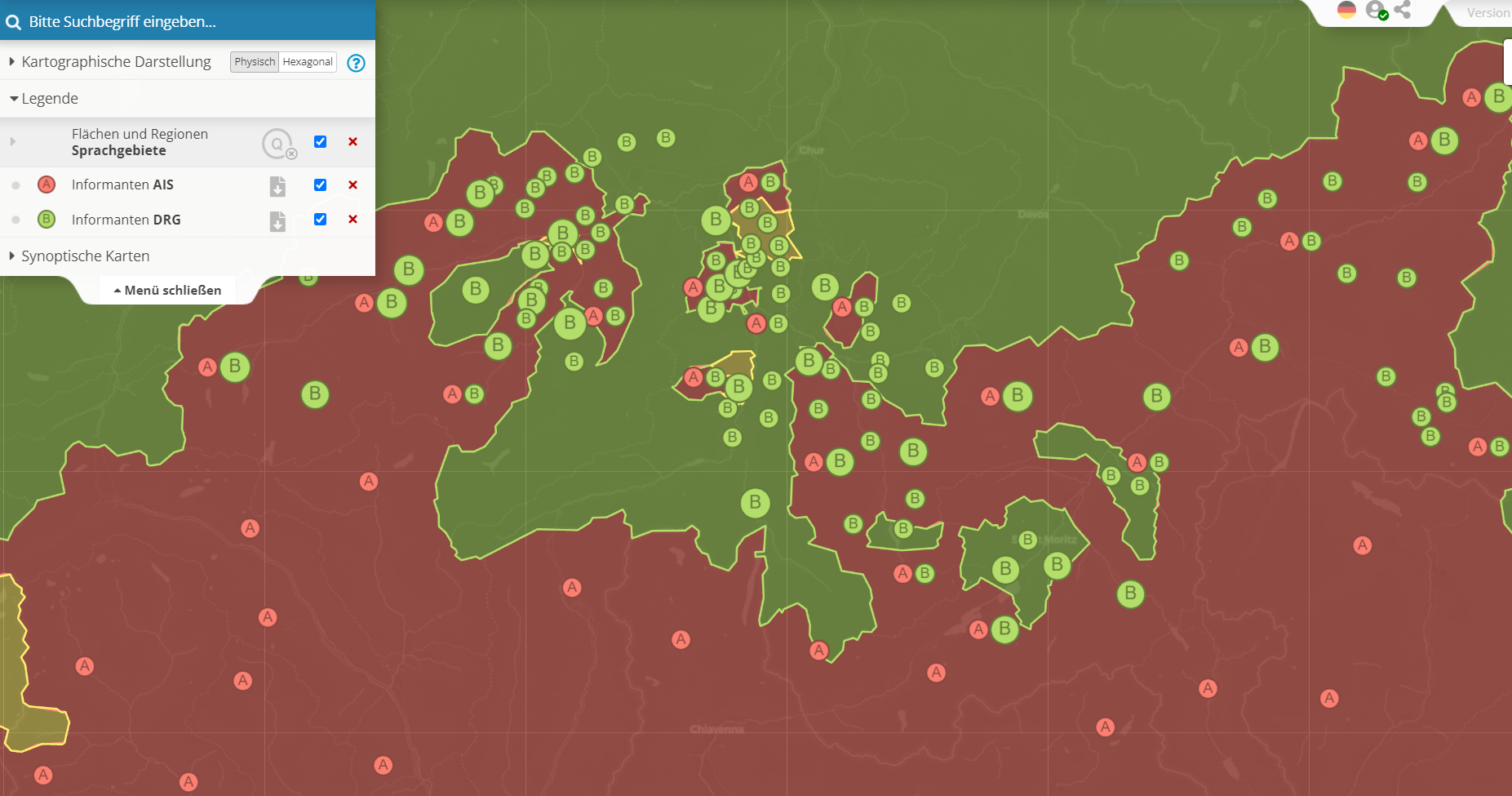
Sprachwechsel in Graubünden am Beispiel einiger ehemals romanischsprachiger Orte des AIS und des DRG (interaktives Original)
3. Neue mediale Rahmenbedingungen
3.1 Aggregation unterschiedlicher Typen von Quellen
Alle Probleme, die sich aus dem spezifisch nationalen geographischen Zuschnitt der Untersuchungsgebiete bereits existierender Atlanten ergeben, lassen sich auf der Grundlage webbasierter Vorgehensweise überwinden; denn die erfassten Räume können aggregiert und integriert werden, da es technisch einfach ist die jeweiligen Ortsnetze virtuell miteinander zu verknüpfen. Die folgende Karte zeigt, welche Atlanten in die Dokumentation eingebunden werden konnten. Notwendige Voraussetzung ist die Georeferenzierbarkeit der Sprachdaten. Es darf jedoch nicht verschwiegen werden, dass der Umfang der tatsächlich übernommenen Daten sehr stark variiert: Manche Projekte stellten im Rahmen von Kooperationsabkommen große Mengen zur Verfügung (vorbildlich war insbesondere die Zusammenarbeit mit dem ALD-I und dem ALD-II), andere konnten nur sehr selektiv und mit aufwändiger Handarbeit retrodigitalisiert werden; dafür wurden von Florian Zacherl spezielle Tools (zur Transkription, zur Typisierung usw.) entwickelt.
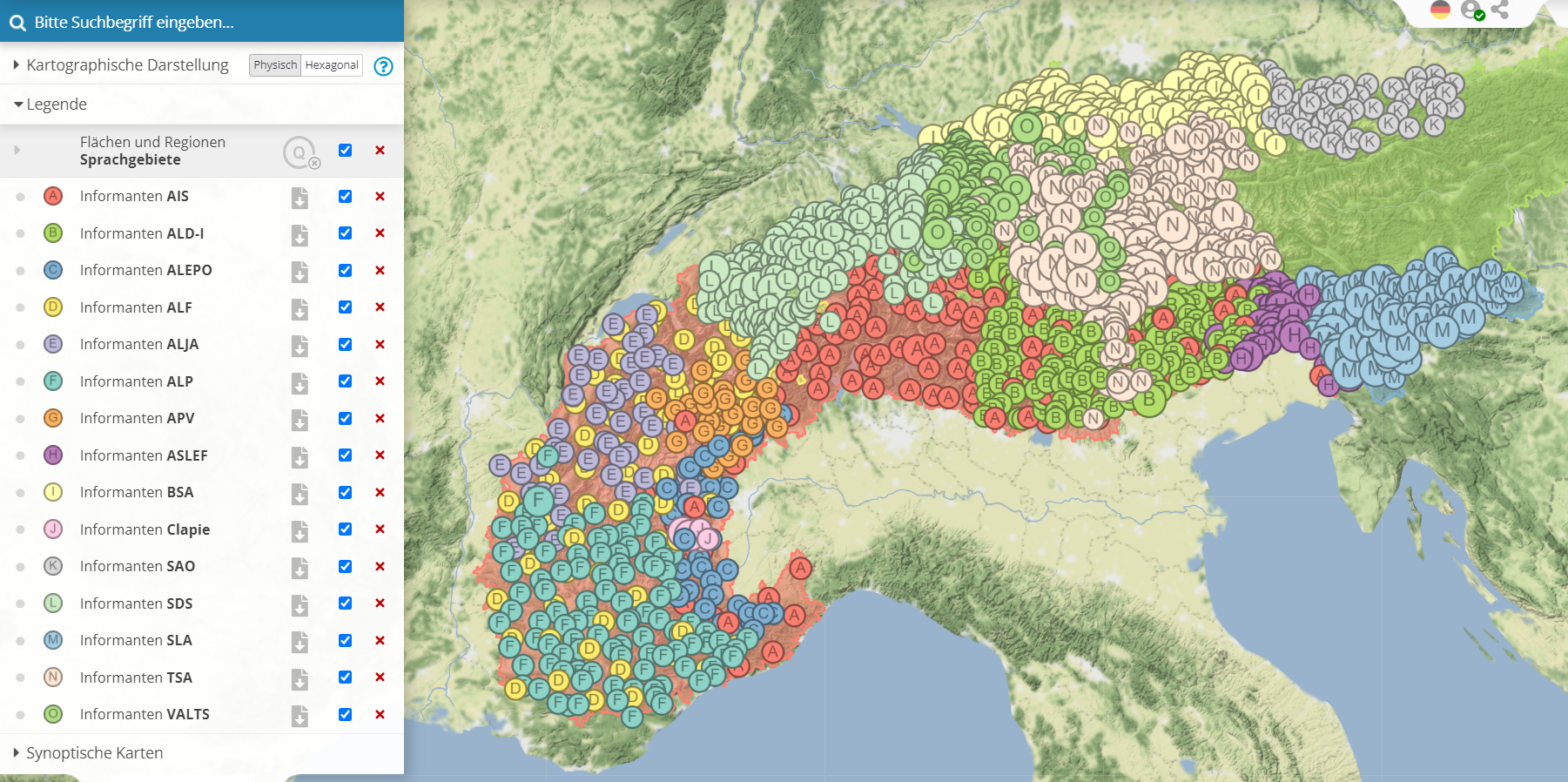
VA Informanten aus Atlanten (interaktives Original)
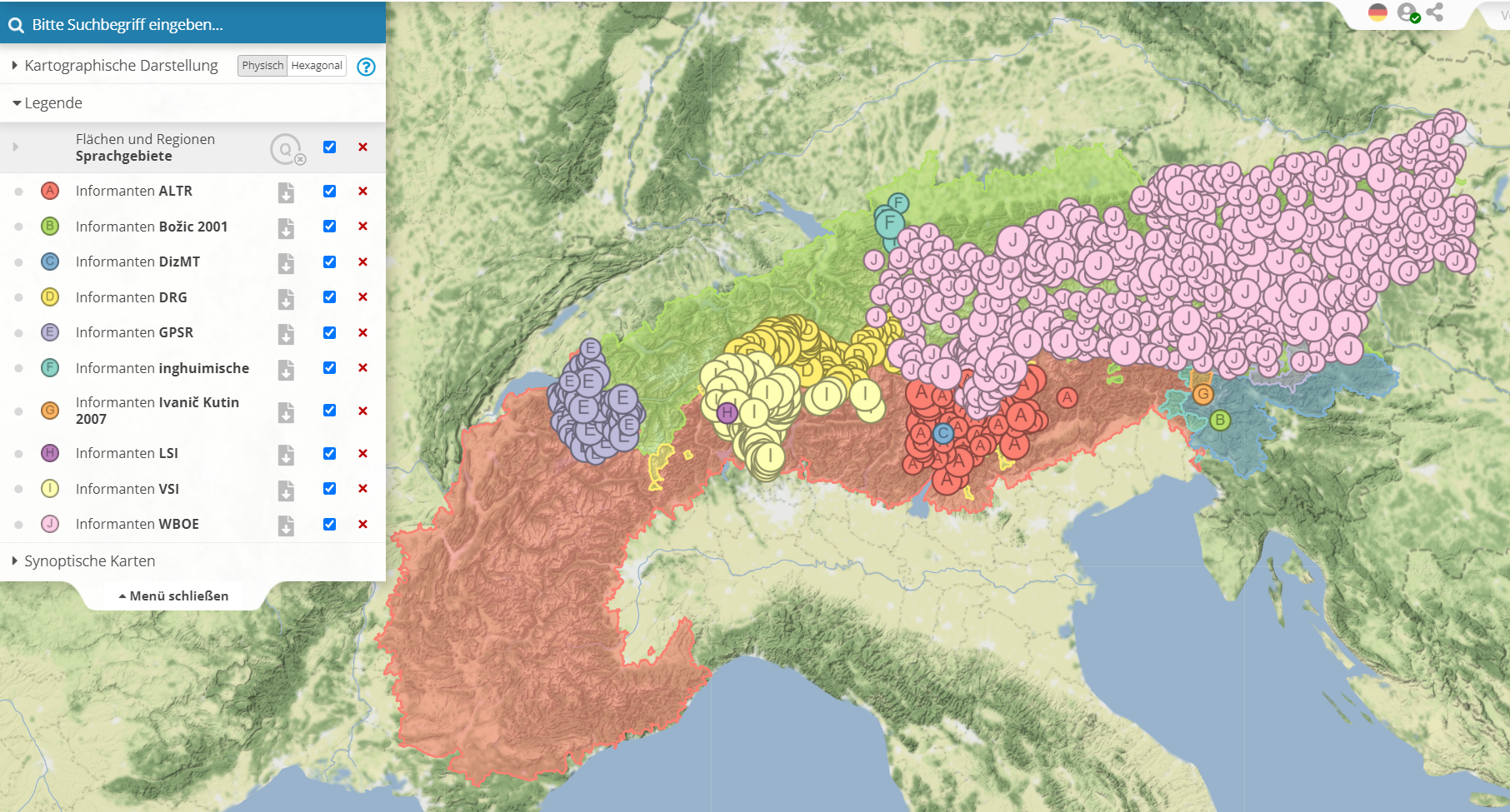
VA Informanten aus Wörterbücher (interaktives Original)
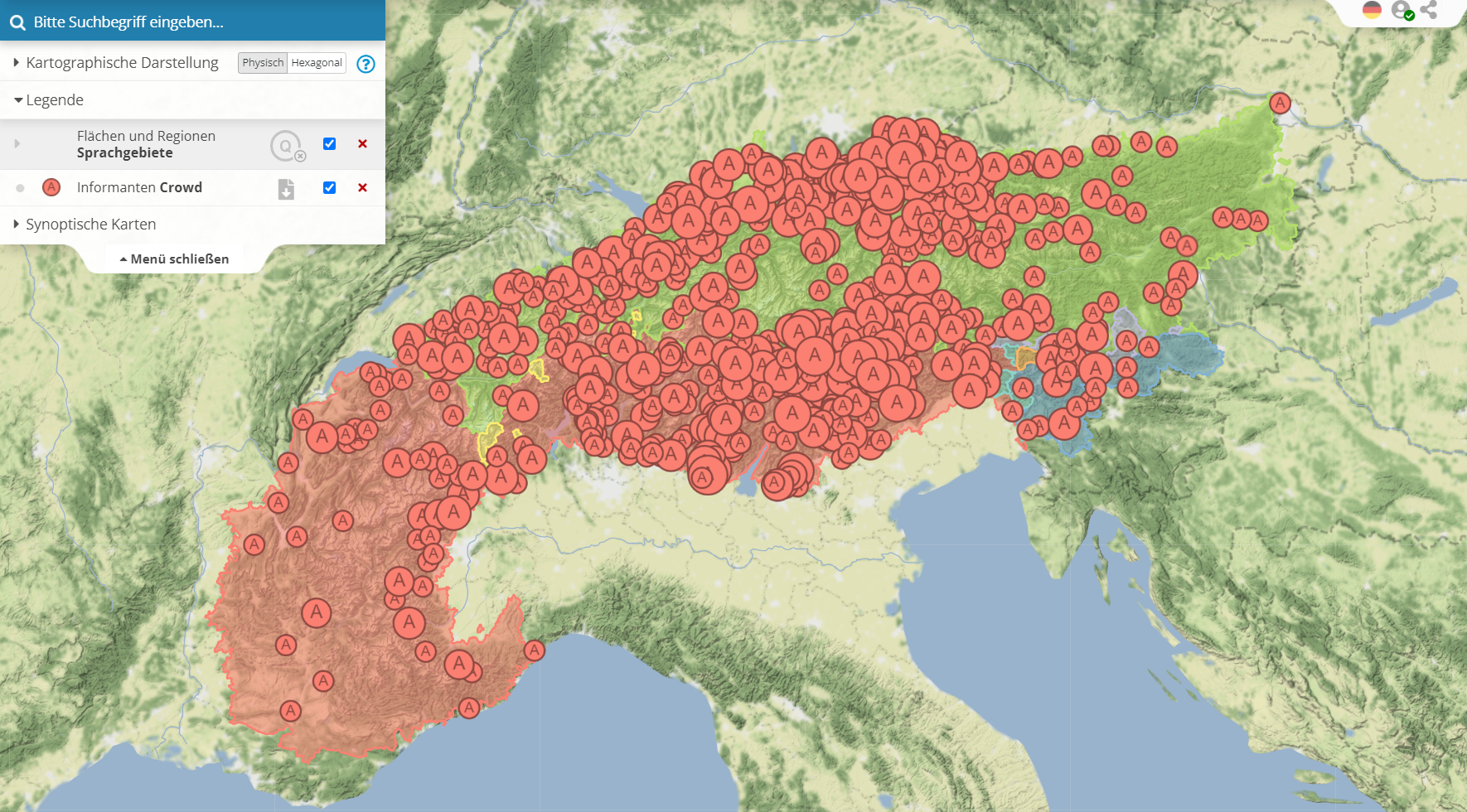
VA Informanten aus der Crowd (28.9.2021, interaktives original)
3.2 Technische Verknüpfung der Sprachen/Dialekte
Entscheidend für die synoptische Darstellung von Formen aus den unterschiedlichen Sprachen und Sprachfamilien ist ihre Verknüpfung in der Struktur des Datenbestands. Sie erfolgt in zweifacher und komplementärer Hinsicht, nämlich auf der Ebene der sprachlichen Bezeichnungen und auf der Ebene der außersprachlichen Sachverhalte (KONZEPTE).
3.2.1 Ebene der sprachlichen Bezeichnungen
Auf der Ebene der sprachlichen Formen werden die zahlreichen Belege typisiert, d.h. die rein phonetischen Varianten werden zu morpho-lexikalischen Typen gruppiert, die auf der Nutzeroberfläche gesucht werden können. Diese Typen sind spezifisch für eine der drei Sprachfamilien; falls möglich repräsentieren die Varianten der großen Nationalsprachen Französisch und Italienisch die Menge aller Varianten eines Typs. So liefert die Suche nach fra. beurre / it. burro eine Karte mit 718 Varianten (in Version 21/1), die jeweils durch Anklicken des Symbols eingesehen werden können:
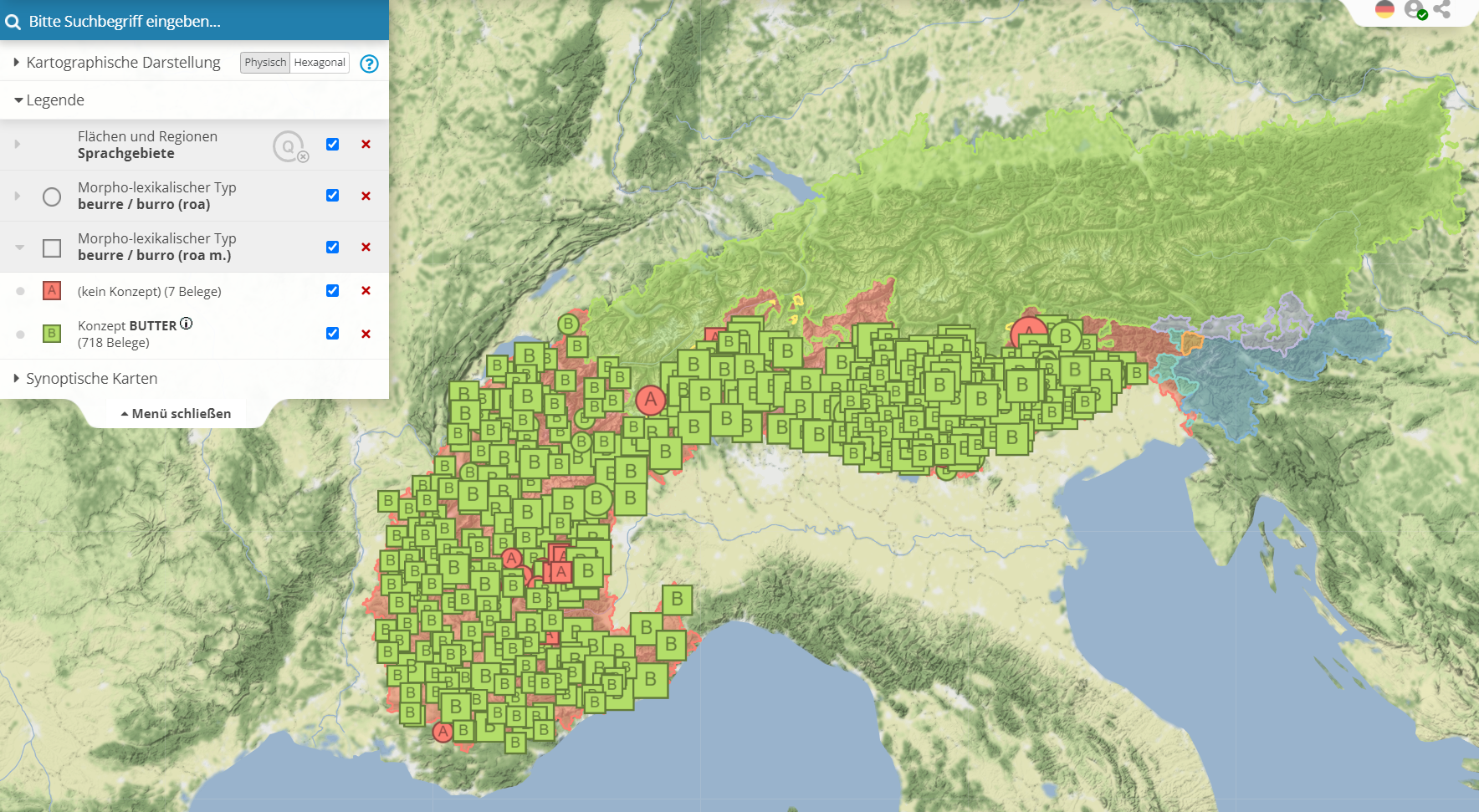
der morpho-lexikalische Type beurre/burro (roa) (interaktive Originalkarte)
Nun gehören offensichtlich auch deu. Butter und dialektal slowenisches put(e)r zu dieser Gruppe, allerdings muss es sich bei entsprechenden germanischen und slawischen Formen um Entlehnungen aus dem Romanischen handeln. Solche Typen, die in mehr als einer Sprachfamilie belegt sind, werden in VA als ‘Basistypen’ gefasst. Sie werden durch die jeweils identifizierbare etymologische Ausgangsform repräsentiert, im Fall von fra. beurre, deu. Butter usw. ist das lat. butyrum (eigentlich ein griechisches Lehnwort). Die Suche nach diesem Basistyp produziert eine Karte mit den zugehörigen Formen in allen relevanten Sprachfamilien:
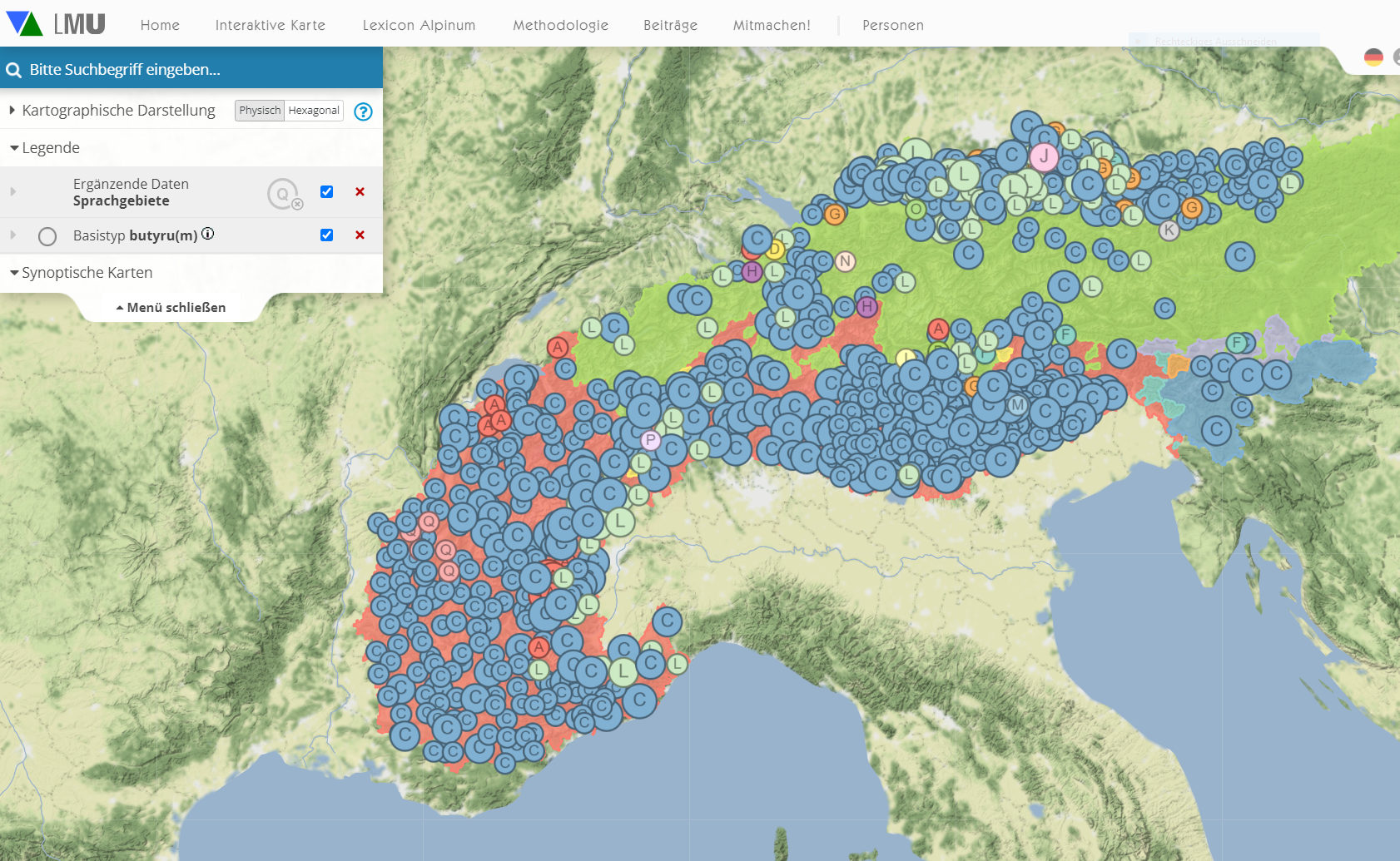
der Basistyp. lat. butyrum (interaktive Originalkarte)
3.2.2 Ebene der Konzepte
Falls an der Nutzeroberfläche ein Konzept gesucht wird, liefert das System alle erfassten sprachlichen Bezeichnungstypen.
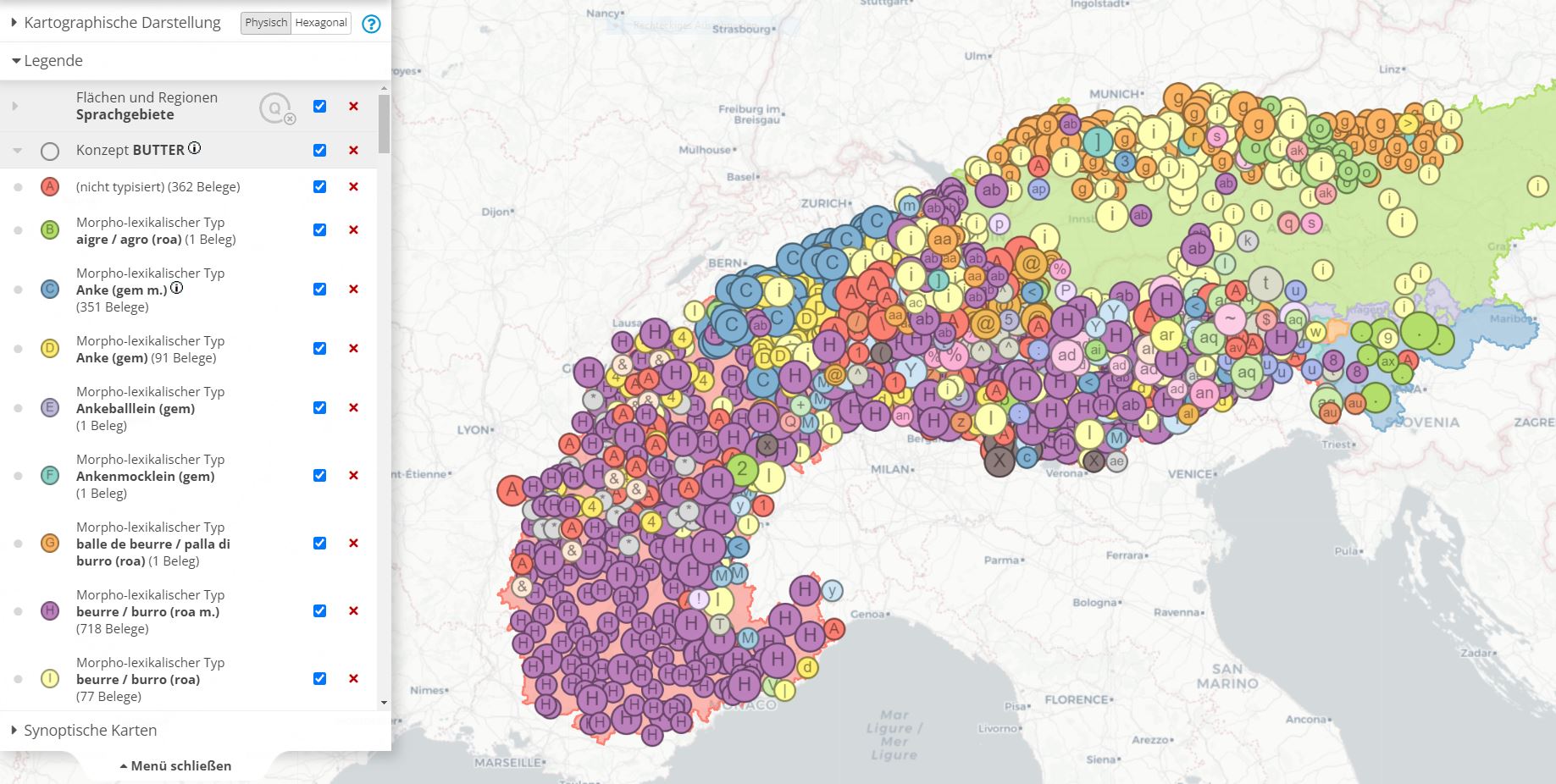
Bezeichnungen des Konzepts BUTTER (unvollständige Legende; interaktive Originalkarte)
Ausschnitt aus der Legende von Karte ## (interaktive Originalkarte|https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=133&db=xxx&tk=3972&layer=4]])
Die ethnographischen Hintergründe der gegenläufigen Entlehnungen (Lat.-Rom. → Deu. vs. Deu → Lat.-Rom.) müssen hier nicht im Detail ausgeführt werden. Es reicht festzuhalten, dass sich dem Anschein nach die Herstellung des Produkts (BUTTER) ausgehend vom Lat.-Rom. Gebiet verbreitet. Vom Deutschen ist dagegen das Auslassen der Butter (SCHMELZEN → SCHMALZ) , analog zum Auslassen des tierischen Fetts, vor allem des Schweinfetts als Konservierungstechnik der kaum haltbaren frischen Butter zu den Romanen gekommen (vgl. auch das so motivierte Kompositum Butterschmalz). Ähnlich sind sich die beiden Produkte BUTTER und SCHMALZ im Übrigen auch in anderer Hinsicht, etwa im hohen Fettgehalt (vgl. den lat. Basistyp unctum, dessen romanischen Kognaten ebenfalls beides bezeichnen (vgl. Karte Basistyp lat. unctum.
Entscheidend ist nun, dass sich Im Hinblick auf die konzeptgeleitete Verknüpfung von Bezeichnungen mehrerer Einzelsprachen in den letzten Jahren vollkommen neue Optionen ergeben haben. Durch die mittlerweile zur Verfügung stehenden, sehr umfangreichen, Bestände von sachbezogenen Normdaten lassen sich Konzepte ganz unabhängig von den sprachlichen Bezeichnungen relationieren und als autonomer Referenzbereich strukturieren; am weitesten fortgeschritten aber linguistisch allenfalls in Ansätzen genutzt sind die sogenannten ‘Datenobjekte’ des Wikidata-Projekts (vgl. Krefeld 2021d). Dabei handelt es sich um Identifikatoren (QIDs), mit denen die enzyklopädischen Inhalte der Wikipedia identifiziert werden. Die entsprechende QID für BUTTER (zugänglich über den Button ‘Wikidata-Datenobjekt’ in der linke Menüspalte des Wikpedia-Eintrags Butter) lautet Q34172. Aus diesem Wikidata-Eintrag geht hervor, das es in 141 Sprachversionen der Wikipedia Artikel zu dem Konzept BUTTER gibt (Stand vom 2.11.2021); alle diese 141 Artikel referenzieren auf die genannte ID. Darunter sind auch etliche Versionen aus romanischen Sprachen, historisch wichtige Vorgänger- und Bezugssprachen sowie zahlreiche europäische und koloniale Entlehnungen aus dem Romanischen:
Romanische Bezeichnungen
|
europäische Entlehnungen |
| Herkunftssprachen | Entlehnungen im kolonialen Kontext
|
Eine analoge Tabelle ließe sich auch für den Wikidata-Eintrag SCHMALZ (lard (Q72827)) zusammenstellen, in der sich Sprachversionen mit Bezeichnungen finden, die offenkundig auf die Übertragung der Bezeichnungen von BUTTER zurückgehen, so asturisch mantega de gochu, wörtlich ‘Butter vom Schwein’ oder span. manteca de cerdo, wörtlich ebenfalls ‘Butter vom Schwein’. Wichtig für die Organisation der onomasiologischen – oder informationstechnisch gesagt: ontologischen – Einheiten ist ihre Verknüpfung in Gestalt von dreigliedrigen Prädikatsausdrücken oder: Tripeln (so genannten ‘statements’), die im Wikidata-Projekt vorgenommen wird. Im Fall unserer Beispiele BUTTER und SCHMALZ finden sich (Stand vom 7.11.2021) u.a. folgende ‘statements’:
| butter (Q34172) | instance of (P31) | food ingredient (Q25403900) |
| subclass of (P279) | dairy product | |
| edible fats and oils (Q912613) | ||
| lard (Q72827) | instance of (P31) | chemical substance (Q79529) |
| food ingredient (Q25403900) | ||
| subclass of (P279) | edible fats and oils (Q912613) | |
| die Wikidata-Statements zu den Konzepten BUTTER und SCHMALZ | ||
Diese Tripel leisten einen fundamentalen Beitrag zum sogenannten Semantic Web, denn sie sind in das dafür erforderliche Format der RDF-Tripel überführbar. man beachte, dass es sich aus linguistischer Sicht gerade nicht um ein ‘semantisches’ (sprachgebundenes), sondern um ein onomasiologisches (sprachunabhängiges) Netz handelt. Es ist offensichtlich, dass elementare Gemeinsamkeiten der beiden Konzepte bereits zum Ausdruck kommen. Die Wikidata-Datenbank ist durch eine formale Sprache (SPARQL) abfragbar, so dass potentielle semantische Gemeinsamkeiten zwischen den Bezeichnungen und die darauf beruhenden Übertragungen durch semantische Prozesse (Metaphern, Metonymien, Meronymien, taxonomische Verschiebungen) gewissermaßen vorhersehbar bzw. motivier- und nachvollziehbar sind. So ergibt die Suche nach den ‘subclasses’ von ‘edible fats and oils’ die folgende Liste:
| wd:Q4287 | Margarine |
| wd:Q34172 | Butter |
| wd:Q72827 | Schmalz |
| wd:Q427457 | Speiseöle |
| wd:Q1194601 | Shortening |
| wd:Q1423543 | Tierfett |
| wd:Q1727434 | Streichfett |
| wd:Q2310378 | Horse fat |
| wd:Q11870297 | Pflanzenfett |
| wd:Q68187377 | Gänsefett |
Nicht weniger offensichtlich ist jedoch auch die Tatsache, dass wichtige Unterschiede wie die Arten der Produktion (SCHLAGEN VON RAHM im Fall von BUTTER und ERHITZEN im Fall SCHMALZ) oder die dafür benutzten Geräte (z.B. das BUTTERFASS) nicht abgebildet werden, obwohl das mindestens teilweise schon möglich wäre, da QIDs zur Verfügung stehen. Die Unterschiede schlagen sich ja auch in semantischen Prozessen nieder (pignatta, bündnerrom. pischada < lat. *pisiare ‘stampfen’; vgl. die interaktive Karte pischada). Daraus ergibt sich der Appell an einschlägige sprachwissenschaftliche Projekt, die Wikidata-Statements im jeweiligen thematischen Rahmen systematisch zu ergänzen.
4. Stratigraphische Wortgeschichte
Die eigentliche wortgeschichtliche Zusammenhang des Basistyps mit den zugehörigen morpho-lexikalischen Typen muss vielmehr vom dem Hintergrund der sprachlichen Stratigraphie des Alpenraums erarbeitet werden. In dieser diachronen Perspektive kommt dem lateinisch-romanischen Stratum eine besondere Bedeutung für den Alpenraum zu. Denn seit 15 n.Chr. gehörte das gesamte Gebiet zum Römischen Reich: Im Gefolge der Romanisierung verschwanden alle vorrömischen Sprachen. Ein Teil wurde nach Zusammenbruch der römischen Infrastruktur (476 n.Chr.) germanisiert, ein anderer slawisiert – dort ist das Lateinisch-Romanische also Substratsprache; das Slawische ist teils auch vom Germanischen verdrängt worden und in diesen Gegenden ebenfalls zum Substrat geworden. Das Germanische war zudem im romanisch gebliebenen Alpengebiet ebenso wie im slawisierten Teil mehr oder weniger lang und in ganz unterschiedlicher sprachlicher Gestalt (Gotisch, Langobardisch, Bairisch bzw. bairisch geprägtes Hochdeutsch) Superstrat. Elemente der vorrömischen Sprachen sind im Lexikon und in Toponymie der gesamten Raum deutlich erkennbar (vgl. Krefeld 2020c) deutlich erkennbar; sie sind mit der allergrößten Wahrscheinlichkeit jedoch indirekt, d.h. über das Lateinisch-Romanische ins Alpengermanische bzw. ins Alpenslawische gelangt.
| AKTUELLE AREALE | Romanisch | Germanisch (Deu.) | Slawisch (Slow.) | |
| ÖST. DEU. SUPERSTRAT | ||||
| GERM. SUPERSTRAT | SLAW. SUB. | |||
| ROMANISCHES SUBSTRAT | ||||
| SPÄTANTIKE AREALE | Lateinisch-Romanisch | |||
| VORRÖMISCHE SUBSTRATE | ||||
| Sprachliche Stratigraphie des Alpenraums (vereinfachtes Schema) | ||||
Die Kontaktszenarien sind also vielfältig und müssen jeweils ‘von Hand’ aufgearbeitet werden. Im Fall des oben bereits erwähnten Basistyps lat. butyrum (n.) ergibt sich abschließend etwa das folgende stratigraphische Schema:
| AKTUELLE AREALE | Romanisch (1) beurre/burro (m.) (2) butirro (m.) |
Germanisch (Deu.) die Butter (f.) ↑ |
Slawisch (Slow.) puter (Dial.) ↑ |
|
| ↑ | der Butter (m.) | → ÖST. DEU. SUPERSTRAT ↑ | ||
| ↑ | ↑ (2) | |||
| ↑ | ↑ ROMANISCHES SUBSTRAT | |||
| SPÄTANTIKE AREALE | Varianten (1) bútyrum (2) butȳrum – Lateinisch-Romanisch | |||
| Stratigraphie des Basistyps lat. butȳrum (nicht relevante Strata ausgeblendet) | ||||
Damit sind die klassischen Atlanten der ‘ersten Generation’ gemeint; zur historischen Modellierung der Dialektologie nach Generationen vergleiche Krefeld/Lücke 2021. ↩
Die Opposition von staatlich institutionalisierten und oft offizialisierten Sprachterritorien einerseits und nicht institutionalisierten Spracharealen andererseits wurde in Krefeld 2004a, 23 f., vorgeschlagen. Beide kommunikationsräumliche Kategorien (sowohl die sprachliche Territorialität wie die sprachlich Arealität) sind sprachsoziologisch zu verstehen und keineswegs verhaltensbiologisch im Sinne eines instinktiven, genetisch konditionierten Revierverhaltens. Ganz unabhängig von der Frage, ob es sinnvoll ist, der Spezies Homo sapiens ein solches Verhaltensmuster zuzumuten, ist es nicht die Aufgabe moderner demokratischer Staatswesen quasi biologische Kategorien in die Organisation des sozialen Raums einzuschreiben. Institutionen sind historisch-kultureller Natur und dementsprechend grundsätzlich nicht deterministisch, sondern regulativ und veränderlich. Auch Mehr- und Vielsprachigkeit kann und soll selbstverständlich in territorialer Weise geregelt werden. Reviere sind ausgrenzend – staatliche Territorien können und sollten integrativ definiert sein. ↩
Die Abfrage lautet:
SELECT ?item ?itemLabel
WHERE
{
?item wdt:P279 wd:Q912613.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
} ↩
Bibliographie
- AIS = Jaberg, Karl / Jud, Jakob (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz, Zofingen, vol. 1-7
- ALD-I = Goebl, Hans (1998): Atlant linguistich dl ladin dolomitich y di dialec vejins I, vol. 1-7 (sprechend: http://ald.sbg.ac.at/ald/ald-i/index.php), Wiesbaden, vol. 1-7, Reichert. Link
- ALD-II = Goebl, Hans (2012): Atlant linguistich dl ladin dolomitich y di dialec vejins, 2a pert, vol. 1-5, Editions de Linguistique et de Philologie. Link
- ALG = Séguy, Jean (1973): Atlas linguistique de la Gascogne, Toulouse, vol. 6, Inst. d'Études Mérid. de la Fac. des Lettres [u.a.]
- DRG = De Planta, Robert/ Melcher, Florian/ Pult, Chasper/ Giger, Felix (1938ff.): Dicziunari Rumantsch grischun, Chur, Inst. dal Dicziunari Rumantsch Grischun. Link
- GPSR = Gauchat, Louis (Hrsg.) (1924ff.): Glossaire des patois de la Suisse romande, Genève [u.a.], Droz [u.a.]
- Krefeld 2004a = Krefeld, Thomas (2002): Einführung in die Migrationslinguistik. Von der Germania italiana in die Romania multipla, Tübingen, Narr
- Krefeld 2020c = Krefeld, Thomas (2020): Polystratale und monostratale Toponomastik – am Beispiel der Romania Submersa und der Insel La Réunion, Version 4 (02.04.2020, 11:26), München, in: Korpus im Text. Link
- Krefeld 2021d = Krefeld, Thomas (2021): Wikidata – semiotisch: Mit Roland Barthes im Internet, München, in: Korpus im Text, Serie A, 71498. Link
- Krefeld/Lücke 2021 = Krefeld, Thomas / Lücke, Stephan (2021): (Unsere) Prinzipien der virtuellen Geolinguistik. Link
- LIÖ = Lenz, Alexandra N. (o.J.): Lexikalisches Informationssystem Österreich (LIÖ). Link
- VSI = Sganzini, Silvio (1952ff): Vocabolario dei dialetti della Svizzera italiana, Lugano, Tipografia la Commerciale
- VerbaAlpina = Krefeld, Thomas / Lücke, Stephan (2014-): VerbaAlpina. Der alpine Kulturraum im Spiegel seiner Mehrsprachigkeit, München. Link
- WBOE = Bauer, Werner/ Kranzmayer, Eberhard. Institut für österreichische Dialekt- und Namenlexika (Hrsg.) (1970–): Wörterbuch der bairischen Mundarten in Österreich, Wien, Verl. der Österr. Akad. der Wiss.